
この投稿では、私の「Stable Diffusion」の探求プロジェクトを皆さんと共有したいと思います。
はじめに
Stable Diffusionは、画像の生成と変換のために設計された高度な人工知能モデルです。
クリエイティブかつリアルに画像を処理・修正するために、深層学習の手法を活用しています。
当初はテキストによる説明から画像を生成するために設計されましたが、現在では画像を入力として受け取ることもできるようになりました。
この機能により、写真のレタッチ、AI支援のアート作成、画像の品質向上などの用途で特に有用です。
プロジェクトについて
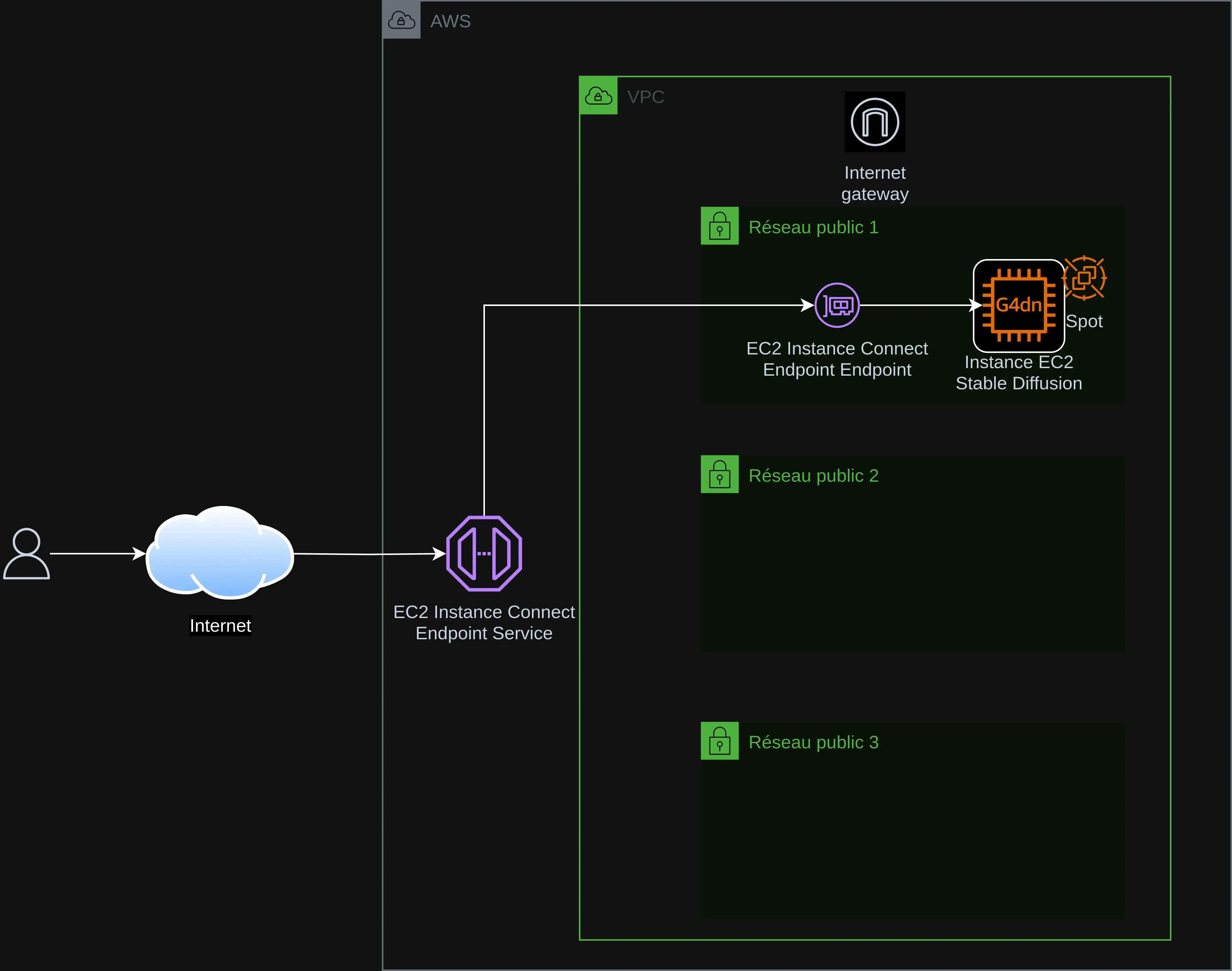
このプロジェクトは、AWSクラウド上のEC2に「Stable Diffusion XL と ControlNet」を簡単にデプロイできるようにします。
Stable Diffusion XL と ControlNet を実行するために必要なインフラの作成と設定を自動化します。
Stable Diffusionのインストールは、EC2が利用可能になった後に(コピーペースト用のガイド付きで)手動で行います。
EC2コストを抑えるために、g4dn.xlargeタイプのスポットインスタンスを使用します(NVIDIA T4 16GB GDDR6 GPU x1、Intel Cascade Lake 4 vCPU、16GB RAM)。
Stable Diffusionのデプロイは、AUTOMATIC1111インストーラーで行います。
アーキテクチャ
プロジェクトの目的
- 画像生成:プロンプトから高品質な画像を生成すること。
- アクセシビリティ:これらの技術を誰でも利用でき理解しやすくすること。
- オープンなコラボレーション:協力と知識共有を促進すること。
この文書は、gpt-5-miniモデルを使用して fr バージョンから ja 言語へ翻訳されました。翻訳プロセスの詳細については、https://gitlab.com/jls42/ai-powered-markdown-translator をご覧ください。