ai-powered-markdown-translatorمقالة مترجمة من الفرنسية إلى العربية باستخدام gpt-5.4-mini.
AI-Powered Markdown Translator هو مشروع مفتوح المصدر أديره منذ 2024: سكريبت Python يترجم أي ملف Markdown إلى 14 لغة عبر 4 مزودين للذكاء الاصطناعي (OpenAI، Mistral AI، Claude، Gemini). وهو يغذي هذه المدونة مع كل منشور — فكل صفحة تقرؤها هنا بلغة غير الفرنسية مرت عبره — وما يقارب 1 800 نسخة مترجمة تعمل بفضله في الإنتاج.
في 8 مايو 2026، نشرت v1.9، التي تجمع 75 commit وتمثل أكبر تحديث منذ v1.5 في 2024. ثلاث إضافات منتجية:
- التحقق بعد الترجمة (ضد الفشل الصامت)
- ملاحظة ترجمة متعددة المواضع (في الأعلى، أو في الأسفل، أو في الاثنين معًا)
- وضع
--newsللحفاظ على الاقتباسات المصدرية EN
لكن لهذه v1.9 خصوصية أريد أن أرويها هنا: كل الشفرة كُتبت بشريك ذكاء اصطناعي. لم تُكتب أي سطر باليد. لذلك، بالإضافة إلى الإضافات الثلاث، يتناول المقال أيضًا «الكيف»: ما الضوابط التي نضعها لاستهداف كود نظيف وآمن عندما لا نراجع نحن أنفسنا ما ينتجه الذكاء الاصطناعي؟
السياق: مشروع يُستخدم يوميًا، لكنه قليل الصيانة على مستوى الكود
من سبتمبر 2024 إلى مايو 2026: استخدام مستمر، وصيانة على فترات متقطعة
كنت قد نشرت مقالًا كان يفصّل الشفرة المصدرية لـ v1.5 في 2024. في ذلك الوقت، كنت أنشر السكريبت مباشرة داخل المقال. اليوم تغيّرت الزاوية: ما عاد المهم بقدر ما هو الكود الذي أكتبه، بل سير العمل الذي ينتجه.
بين v1.5 المنشورة في سبتمبر 2024 ويناير 2026، واصل المشروع العمل — فهو يترجم كل محتوى جديد لهذه المدونة — لكن الكود العام لم يتحرك تقريبًا. لم يُدفع سوى commit واحد في 2025. طوال تلك الفترة، كنت أطور الكود محليًا لاحتياجاتي الشخصية — خصوصًا النماذج، التي كنت أستبدلها مع صدور إصداراتها — لكن هذه التطورات كانت تبقى على جهازي. أما النسخة العامة على GitLab فكانت ما تزال تشير إلى القيم الافتراضية الخاصة بـ v1.5.
في بداية 2026، قمت بأول جهد حقيقي للتحديث: ثلاث إصدارات خلال شهرين (v1.6 وv1.7 في يومين مع بداية يناير، وv1.8 في مارس) أعادت المشروع إلى حداثته من ناحية الوظائف — نماذج 2026، دعم Gemini، وضع --eco، ملف واحد، ووضع --news للاقتباسات المصدرية. لكن ظل الأمر من دون CI، ومن دون اختبارات آلية، ومن دون بوابات جودة — وهو ما كان يطرح عليّ مشكلة حقيقية إذا أردت المضي أبعد مع وكيل ذكاء اصطناعي يكتب الشفرة نيابةً عني.
إيقاع مشروع يُدار على الوقت الشخصي
لماذا هذا التأخر؟ لأنني أحمل هذا المشروع في وقتي الشخصي. لديّ عائلة، وحياة خارج الشاشة، لذلك لا يتقدم التطوير إلا على دفعات عندما أجد الأمسيات وعطلات نهاية الأسبوع. أنا شغوف، وأقضي فعلًا وقتًا غير قليل في هذه المواضيع — أختبر كثيرًا، وأوجّه الوكلاء، وأتحقق من النتائج — لكن الإيقاع ليس إيقاع مشروع مهني.
الشريك مع الذكاء الاصطناعي يغيّر هذا بالضبط. فهو يتيح لي أن أتحرك بين قيدين: الشغف، وتوزيع الوقت مع الحياة خارج الشاشة. من دونه، ما كنت أصل بالتأكيد إلى هذا الحد ولا بهذه السرعة. ومعه، أستطيع أن أُبقي مشروعًا مفتوح المصدر بمستوى صناعي من دون أن أكرّس له حياتي.
الهدف الأولي: الجودة + الانتقال من GitLab إلى GitHub
في منتصف أبريل 2026، أردت أخيرًا أن أعتني بالأمر بجدية. هدفان بسيطان:
- إضافة طبقة جودة (تحليل ساكن، اختبارات، CI)
- نقل المستودع من GitLab إلى GitHub
لا أكثر. لكن مع وكيل كتابة يعمل كشريك ذكاء اصطناعي، لا نكتب أبدًا ما كان مخططًا له فقط. انتهى الأمر بـ PR مؤلفة من 75 commit، و9 837 إضافة، و1 982 حذفًا، و58 ملفًا.
| النسخة | التاريخ | الإضافة الرئيسية |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI، ثم Mistral، ثم Claude |
| 1.5 | sept. 2024 | إعادة هيكلة العملاء، ونماذج 2024 (gpt-4o، claude-3.5-sonnet) |
| 1.6 | janv. 2026 | نماذج 2026 (gpt-5، claude-sonnet-4-5، gemini-3-pro)، Gemini، وضع --eco، ملف واحد (--file) |
| 1.7 | janv. 2026 | --keep_filename، .env، والحفاظ على code inline |
| 1.8 | mars 2026 | نماذج GPT-5.4 افتراضيًا، ووضع --news مع placeholders للاقتباسات |
| 1.9 | mai 2026 | التحقق بعد الترجمة، ملاحظة متعددة المواضع، منظومة جودة 14 hook + 229 اختبارًا + مراجعة IA |
أثر كرة الثلج
كل أداة جودة أُضيفت كانت تكشف مشاكل. Codacy أشار إلى التكرارات. SonarCloud أثار code smells (إشارات إلى أن الشفرة ستتدهور مع الوقت: دوال طويلة جدًا، معاملات غير مستخدمة، تراكيب معقدة على نحو مبالغ فيه). /pr-review-toolkit كشف عن أخطاء مخفية. ومع كل تنبيه، كان الوكيل يصلح، وأحيانًا يحسن أشياء مجاورة أيضًا.
لقد اتسع النطاق طبيعيًا. وهذا بالضبط ما كنت أريده — تحديث المشروع — لكن حجم الجهد كان تحدده الأدوات، لا أنا. بالنسبة إلى مشروع يُبنى بأسلوب الترميز الحدسي، هذه نقطة أساسية: أدوات الجودة توجه العمل بقدر ما تتحقق منه.
الإضافة 1: التحقق بعد الترجمة (ضد الفشل الصامت)
الحادثة: الذكاء الاصطناعي نفسه هو من اكتشف الخطأ أثناء الاختبارات
أثناء اختبار الـ PR على ملفات README من مستودعات عامة مختلفة — وهي حالة لم تكن أي fixture تغطيها —، أبلغ الذكاء الاصطناعي عن ما فاتني: في بعض اللغات (ولا سيما الهندية، رمز ISO hi)، بقيت مقاطع باللغة المصدرية وسط الترجمة. كانت الواجهة البرمجية قد أرجعت 200، وكتب السكريبت الملف، لكن المحتوى كان مترجمًا جزئيًا فقط. وهذا مرّ عبر مجموعة الاختبارات الوحدوية الموجودة — لأنها لم تكن تغطي هذه الحالة الواقعية متعددة اللغات.
هذا هو بالضبط النوع من الأخطاء الذي يمكن أن ينتجه vibe coding ولا يلاحظه أحد. الشفرة تبدو منطقية، وfixtures الاختبار لا تغطي الحالة، والإنسان لا يراجع النتيجة. لكن هنا، عندما اختُبر السكريبت على حالات واقعية (متعددة المستودعات)، فعل الذكاء الاصطناعي نفسه ما لم تكن تفعله fixtures.
ما أستخلصه من ذلك: الاختبارات العملية متعددة المستودعات تجد ما تفوّته الاختبارات الوحدوية. ويمكن للذكاء الاصطناعي أيضًا أن يُستخدم لاكتشاف أخطاء وكلاء ذكاء اصطناعي سابقين — بشرط أن نضعه أمام حالات واقعية ومتنوعة.
عندها فهمت أنه لا بد من إضافة تحقق حقيقي بعد الترجمة. وهذه هي الإضافة الأولى التي أفصّلها الآن: طبقة التحقق المزدوجة.
طبقة التحقق المزدوجة
| الخطوة | الإجراء | إذا فشل |
|---|---|---|
| 1️⃣ | استدعاء API لدى المزود | استثناء شبكي → ❌ فشل |
| 2️⃣ | قائمة سماح خاصة بالمزود لـ finish_reason (أو stop_reason لدى Claude) | خارج قائمة السماح → ❌ فشل |
| 3️⃣ | منع التسرب: لا توجد نافذة من المصدر بطول ≥ 120 حرفًا حرفيًا في المخرجات | تم العثور على نافذة من المصدر → ❌ فشل |
| 4️⃣ | langdetect.detect_langs (احتمالات المصدر مقابل الهدف) | المصدر > 0,80 والهدف < 0,20 → ❌ فشل |
| 5️⃣ | محتوى فارغ + نسبة المخرجات إلى المصدر (إذا كان المصدر ≥ 500 حرف) | فارغ أو المخرجات < max(50, source/20) → ❌ فشل |
| ✅ | نجاح | exit code 0 |
الطبقة 1 (حتمية) — أول شبكة أمان: التحقق من الحالة التي تُرجعها الواجهة البرمجية. كل مزود يعرّض حقل finish_reason (أو stop_reason لدى Claude) يوضح لماذا توقف الـ LLM عن التوليد. يحافظ السكريبت على قائمة سماح خاصة بكل مزود للحالات المقبولة — وتتغير التسمية باختلاف المزود (stop لدى OpenAI/Mistral، وSTOP أو FINISH_REASON_STOP لدى Gemini، وend_turn أو stop_sequence لدى Claude). كما يتسامح الكود مع None من باب الأمان، عندما لا يعيد SDK هذا الحقل. أي حالة أخرى — مثل length أو max_tokens أو MAX_TOKENS بحسب المزود، والتي تشير إلى أن الرد توقف بسبب حد التوكنات — تؤدي إلى RuntimeError فوري، من دون أي محاولة للاسترداد.
الشبكة الحتمية الثانية، والأكثر دقة: التحقق من أن أي جزء من النص المصدر لا يظهر حرفيًا في المخرجات المترجمة. عمليًا، نستخرج نوافذ بطول 120 حرفًا أو أكثر من النص المصدر؛ وإذا عُثر على إحداها كما هي داخل المخرجات، فهذا يعني أنها لم تُترجم — failure. وهذا تحديدًا هو الفحص الذي أمسك حالة الهندية: كان الـ LLM قد ردّ بـ stop (أي نهاية «طبيعية» من جهة الـ API)، لكن فقرات فرنسية بقيت كما هي داخل المخرجات — غير مرئية في شبكة finish_reason، وكُشف عنها عبر شبكة منع التسرب الحرفي.
الطبقة 2 (احتمالية) — langdetect.detect_langs يحلل لغة المخرجات ويعيد توزيعًا لاحتمالات عدة لغات مرشحة. نستخرج احتمال لغة المصدر واحتمال لغة الهدف، ثم نرفض فقط إذا تجاوز احتمال المصدر 0,80 و هبط احتمال الهدف دون 0,20 — وهو عتبة محافظة عمدًا حتى لا نُنتج إيجابيات كاذبة على code-switching التقني (مثل الكلمات الإنجليزية المشروعة داخل ترجمة فرنسية). هذه الطبقة تُختصر للغات ذات الكتابات غير اللاتينية (الهندية hi، العربية ar، الصينية zh، اليابانية ja، الكورية ko) حيث تكفي إشارة كتابية ملائمة للتحقق من المخرجات. وهي لا تعمل إلا إذا كانت المخرجات المنظفة لا تقل عن 100 حرف، لتجنب الإيجابيات الكاذبة على النص القصير جدًا.
الضوابط الكمية
فوق الطبقتين، هناك فحصان أكثر بساطة لكنهما ضروريان:
- حارس المحتوى الفارغ: إذا أعاد المزود مخرجات فارغة بينما
finish_reasonيساويstop، نرفض مباشرة (وإلا لكنا كتبنا ملفًا فارغًا وموسومًا كنجاح) - نسبة السلامة: فقط إذا كان المصدر بطول لا يقل عن 500 حرف، نتحقق من أن المخرجات ليست قصيرة بشكل مريب (عادةً <
max(50, source/20)). هذا كاشف لاقتطاع غير مرئي، لا قاعدة عامة للطول
وعلى Claude تحديدًا، ارتفع max_tokens من 4 096 إلى 32 768 في v1.9 (وقد جرى التعديل من جهة الشفرة بواسطة Claude بعد أن لاحظت العرض وطلبت التحقيق). والسبب الموثق في CHANGELOG: تجنب الاقتطاع الكامن في المقاطع ذات 16 ألف حرف، مع هامش إضافي للغات ذات الكتابة غير اللاتينية (FR → JA، ZH، KO، AR، HI) التي تستهلك توكنات أكثر في المخرجات من نظيرتها اللاتينية.
ردود عبر حالة صريحة
خط أنابيب الملف الواحد (translate_markdown_file()) يعيد الآن حالة صريحة — success، failure أو skipped. ويجمع CLI هذه الحالات وينهي التنفيذ برمز خروج غير صفري بمجرد فشل ملف واحد على الأقل — ما يجعل الفشل قابلًا للاستغلال بواسطة سكريبت مستدعي أو عبر CI الجديدة المضافة في v1.9. قبل هذه v1.9، كانت عدة أخطاء تُطبع فقط أو تمر كما لو أن الترجمة نجحت: كان يمكن للعملية أن تنتهي بـ 0 بينما كان الملف غائبًا أو غير مكتمل أو غير مُتحقق منه جيدًا. أما الحالة skipped فأصبحت بحد ذاتها إشارة قابلة للقراءة («تم التجاهل عمدًا»)، ومختلفة عن success («تمت كتابة الترجمة بشكل صحيح»).
📄 مقتطف Python: التحقق المزدوج بعد الترجمة (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteالإضافة 2: ملاحظة الترجمة متعددة المواضع
الحاجة: ملاحظة هادئة لكنها مفيدة
عندما يكتب AI-Powered Markdown Translator ترجمةً، يضيف ملاحظة ترجمة تشير إلى النموذج المستخدم والتاريخ. قبل v1.9، كانت هذه الملاحظة تُلصق دائمًا في أسفل الملف، بصيغة موروثة (legacy) مع فواصل مرئية.
كان للصيغة الملصقة في الأسفل مشكلتان في استخدامي الشخصي. أولًا، كان القارئ لا يُبلَّغ إلا في النهاية بأن المحتوى تمت ترجمته بالذكاء الاصطناعي — ومن الأفضل التحذير منذ البداية، حتى تكون التوقعات صحيحة تجاه المحتوى. ثانيًا، كانت الملاحظة السفلية لا تبرز مشروع الترجمة الذي يجعل كل هذا ممكنًا: يقرأ المرء المقال، وتبقى أصول التدفق متعدد اللغات غير ملحوظة. لذلك أردت أن أتمكن من نقل الملاحظة إلى الأعلى مع الحفاظ على التتبع — من دون كسر الاستخدامات القائمة. تضيف v1.9 علامتين لا تكسران شيئًا:
--note_position {top,bottom,both}: أعلى، أسفل، أو الاثنين معًا--note_format {legacy,marker}: الصيغة الموروثة أو صيغة العلامة (marker format)
افتراضات متوافقة رجعيًا: legacy + bottom. لا يتغير السلوك الافتراضي لأي سلسلة ترجمة موجودة — نفعّل الأعلام الجديدة صراحةً عند الطلب.
صيغة العلامة: بطاقة مضمّنة GitHub نظيفة
تستفيد صيغة العلامة من تفصيل دقيق في Markdown الخاص بـ GitHub: تعريفات الروابط المرجعية غير المستخدمة تكون غير مرئية في العرض. لذلك يمكننا ترميز البيانات الوصفية (النموذج، التاريخ، المصدر) داخل تعليق-علامة موضوع في أعلى الملف — غير مرئي في المتصفح، لكنه يبقى كما هو عند نسخه نصًا خامًا.
وفوق ذلك، ينشئ GitHub بطاقة مضمّنة عند مشاركة رابط إلى الملف المترجم، وتعرض هذه البطاقة بالفعل عنوان المستند من دون أي تلوث نصي.
مثال Markdown خام مع صيغة العلامة في الموضع top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...بالنظر فقط، لا يرى القارئ سوى العنوان متبوعًا بالمحتوى. ولا تلوّث العلامة لا عرض HTML ولا بطاقة التضمين.
الإدراج الواعي للـ frontmatter (frontmatter-aware)
تفصيل تقني لكنه حاسم: إدراج ملاحظة في top لا يعني «إدراجها في السطر 1 من الملف». إذا كان الملف يحتوي على frontmatter YAML (وهذا هو الحال في هذه المدونة)، فيجب إدراجها بعد الـ frontmatter — وإلا ستكسر الملاحظة الـ YAML.
أعطيتُ Claude المتطلب («أدرِج الملاحظة بعد الـ frontmatter، لا قبله — وإلا ستكسر الـ YAML»)، فأنشأ helper _split_frontmatter يكتشف fences --- المفتوح/المغلق. إذا كان الملف يحتوي على fence YAML غير مُغلقة (حالة مشوهة)، فإن helper يرمي RuntimeError بدل أن ينتج بصمت ملفًا مكسورًا. الانتقال من دالة أحادية كتلية إلى 7 helpers نقية (منفصلة وقابلة للاختبار) هو نموذج لما يستطيع pair-IA موجَّه جيدًا إنجازه بسرعة. دوري هنا: مرشد للمتطلب، مختبِر، عميل نهائي يوافق على النتيجة. لا أكتب الكود. في هذا المشروع أرتدي عدة قبعات — ما عدا قبعة كتابة الكود، فهي تعود إلى Claude.
| الموضع | التنسيق | حالة الاستخدام النموذجية |
|---|---|---|
top | marker | مقالات المدونة (ملاحظة خفية، embed card نظيف) |
top | legacy | توثيق داخلي حيث تهمّ قابلية التتبع المرئية |
bottom | marker | README مفتوح المصدر (متسق مع footer) |
bottom | legacy | القيم الافتراضية — متوافق مع الإصدارات السابقة |
both | marker | مقالات طويلة حيث يطمئنك التثبيت من الأعلى والأسفل |
both | legacy | حالة legacy مع متطلب تتبع مزدوج |
📄 مقتطف Python : helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")الجديد 3 : وضع --news للحفاظ على الاقتباسات المصدرية EN
المشكلة : الترجمة دون كسر الاقتباسات
عندما أكتب مقالات ia-actualites لهذه المدونة (أخبار IA متعددة المصادر يومية/أسبوعية)، أقتبس بانتظام تغريدات، تدوينات مدونات، وإعلانات إصدارات باللغة الإنجليزية — وغالبًا عدة اقتباسات في المقال الواحد. إذا مسّت الترجمة الاقتباسات، تصبح خاطئة.
الاقتباس المترجم هو اقتباس محرَّف. في جميع النسخ اللغوية (EN، DE، JA، إلخ)، نريد الإبقاء على الإنجليزية الأصلية للاقتباسات — وهذا مطلب وفاء للمصادر — مع إرفاق علم اللغة المستهدفة وترجمة بالخط المائل لراحة القراءة.
الحل : placeholders <NEWSQUOTE id="N"/>
| الخطوة | الإجراء |
|---|---|
| 1️⃣ | Markdown المصدر FR مع اقتباسات EN كمدخل |
| 2️⃣ | المعالجة المسبقة : استخراج الاقتباسات EN، واستبدالها بـ placeholders <NEWSQUOTE id="0"/>، <NEWSQUOTE id="1"/>، إلخ. |
| 3️⃣ | ترجمة API (FR → target_lang) — الاقتباسات EN الأصلية لا تُرسل أبدًا إلى LLM، وإنما تُرسل placeholders فقط (محفوظة كما هي) |
| 4️⃣ | المعالجة اللاحقة : استرجاع placeholders مع الاقتباسات EN الأصلية سليمة + إدراج علم اللغة المستهدفة |
| 5️⃣ | التحقق بعد الترجمة : هل أُعيدت جميع placeholders؟ |
| ✅ | مخرجات مستهدفة مع الحفاظ على الاقتباسات EN |
| ❌ | فشل إذا لم يُسترجع placeholder أو إذا تحرّف الاقتباس |
يعتمد وضع --news على هذا المبدأ : معالجة مسبقة تستخرج كل الاقتباسات EN، تستبدلها بـ placeholders من نوع <NEWSQUOTE id="0"/>، تترجم الباقي، ثم تسترجع placeholders سليمة.
يُكيّف mapping LANG_FLAGS العلم مع target_lang (15 لغة مغطاة) : 🇬🇧 للإنجليزية، 🇩🇪 للألمانية، 🇪🇸 للإسبانية، 🇮🇹 للإيطالية، 🇵🇹 للبرتغالية، 🇳🇱 للهولندية، 🇵🇱 للبولندية، 🇸🇪 للسويدية، 🇷🇴 للرومانية، 🇸🇦 للعربية، 🇮🇳 للهندية، 🇯🇵 لليابانية، 🇰🇷 للكورية، 🇨🇳 للصينية، 🇫🇷 للفرنسية.
يتحقق التحقق بعد الترجمة من أن جميع placeholders أُعيدت سليمة. الخطأ ليس «تسرّبًا EN» — فالإنجليزية مقصودة — بل placeholder غير مسترجع أو اقتباس محرَّف.
حالات الاستخدام الحالية والآفاق
اليوم، أستخدم --news حصريًا على مقالات ia-actualites في المدونة. وعلى المدى الطويل، يمكن أن يمتد إلى أي مقال يمزج نثرًا فرنسيًا مع اقتباسات مصادر EN — مقابلات، وخواطر/تجارب تستشهد بمقالات بحثية بالإنجليزية، ونصوص عروض تقديمية لمؤتمرات.
دون إعادة قراءة الكود : لماذا يجب مضاعفة الضوابط
« لا أقرأ الكود. »
أنا لا أراجع شيئًا. أحيانًا أنظر بسرعة إلى diff — وهذا نادر، ويحدث فقط عندما يعجز Claude عن حل نقطة ما بمفرده. هذا هو التدفق الذي أستخدمه يوميًا والذي أنتج v1.9 : Claude Code (Opus، حصريًا) يكتب الكود. Codex يتولى الأمر عندما يتعطل Opus أو عندما تمتلئ نافذة الاستخدام. GPT-5.5 في reasoning extra-high يتحدّى الخطط قبل التنفيذ. /pr-review-toolkit:review-pr يراجع PR قبل كل merge. دوري يتوقف عند اعتماد الاتجاهات وتحديد الضوابط.
هذا النمط من التطوير — تطوير بالإحساس (vibe coding) بشكل كامل — ليس نقصًا في الانضباط. إنه مقايضة صريحة : مراجعة بشرية أقل، تحقق أدواتي أكثر. لقد أُنتجت كل nouveauté v1.9 الثلاث التي عرضتها للتو ضمن هذا التدفق. ولهذا بالضبط، لأننا لا نراجع الكود، يجب مضاعفة الضوابط التقنية — لا إزالتها.
إليك الضابطان الموضوعان لجعل هذا النمط من التطوير قابلًا للحياة في الإنتاج : حزمة جودة مؤتمتة (الضابط 1) ومراجعة مساعدة بالذكاء الاصطناعي ضمن تدفق متعدد النماذج (الضابط 2).
الضابط 1 : حزمة الجودة المؤتمتة (14 hook + اختبارات عملية)
نظرة عامة
| الشبكة | الأدوات | الكلفة النموذجية | حاجز إذا فشل |
|---|---|---|---|
| pre-commit | shellcheck، ruff، prettier، pre-commit-hooks (8 sub-hooks)، detect-secrets، Lizard CCN | < 10 s | نعم |
| pre-push | mypy، Opengrep SAST، pip-audit + audit_verdict، unittest (229) | ~ 30 s | نعم، باستثناء pip-audit في وضع reporting initial |
| CI خارجي | SonarCloud، Codacy، CodeFactor | بالتوازي | غير حاجز محليًا، شارات PR |
أرقام v1.9 : 14 hook، 229 اختبارًا unittest stdlib، حوالي 98 % تغطية على الكود الجديد v1.9، 11 شارة SonarCloud، 3 منصات خارجية.
Pre-commit : الشبكة السريعة
| # | الأداة | الإصدار | الدور |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Lint shell |
| 2 | ruff (lint) | 0.8.6 | Lint Python |
| 3 | ruff (format) | 0.8.6 | تنسيق Python |
| 4 | prettier | 3.1.0 | تنسيق Markdown / JSON / YAML |
| 5 | trailing-whitespace | 5.0.0 | إزالة المسافات في نهاية السطر |
| 6 | end-of-file-fixer | 5.0.0 | فرض newline نهائي |
| 7 | check-yaml | 5.0.0 | التحقق من صحة YAML |
| 8 | check-toml | 5.0.0 | التحقق من صحة TOML |
| 9 | check-added-large-files | 5.0.0 | يمنع الملفات الثنائية الكبيرة المضافة بالخطأ |
| 10 | check-merge-conflict | 5.0.0 | كشف مؤشرات تعارض Git |
| 11 | check-executables-have-shebangs | 5.0.0 | يتحقق من أن الملفات التنفيذية تحتوي على shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | يتحقق من أن السكربتات ذات shebang قابلة للتنفيذ |
| 13 | detect-secrets | 1.5.0 | كشف مفاتيح API والأسرار |
| 14 | check-complexity (Lizard) | local | سقف التعقيد الحلزوني على الكود الجديد |
الإجمالي المقاس : حوالي 2 إلى 3 ثوانٍ على كامل المستودع (وهو دافئ، pre-commit run --all-files مؤقتًا بحوالي ~2,4 s). على commit متوسط لا يمس إلا بضعة ملفات، يكون أسرع من ذلك. قاعدة الإبهام التي أطبقها : فوق 10 s، يبدأ المطورون بتجاوز الفحص (وكذلك pair-IA) — لذلك يجب الحفاظ على هذه الشبكة السريعة دائمًا.
Pre-push : الشبكة الثقيلة
- mypy بوضع lax : لا strict شامل (الكود التاريخي في translate.py لن يجتاز ذلك)، بل تحقق تقدمي على الكود الجديد
- Opengrep SAST :
p/security-audit p/default p/python— نحو 30 ثانية لفحص injections، eval، deserialize غير الآمن - pip-audit مغلف بواسطة
scripts/check-pip-audit.sh: يلتقط مخرجات JSON، ويصنف من جهة shell أخطاء النقل (الشبكة، تعطّل PyPI) حتى لا يُخلط بين الثغرة الأمنية وعدم الإتاحة، ثم يبلّغ عن الثغرات. في وضع reporting initial لـ v1.9 (warn + exit 0) — على أن يصبح حاجزًا بعد PR لترقية الاعتماديات القديمة. - unittest discovery :
python -m unittest discoverعلىtests/ثمscripts/tests/— 229 اختبارًا، حوالي 8 ثوانٍ محليًا
CI خارجي : SonarCloud + Codacy + CodeFactor
الـ workflow .github/workflows/sonarcloud.yml (مفتاح المشروع jls42_ai-powered-markdown-translator) يعمل على كل PR. 11 شارة SonarCloud معروضة على README : Quality Gate، Security/Reliability/Maintainability Rating، Coverage، Vulnerabilities، Bugs، Code Smells، Duplications، Technical Debt، LOC.
لماذا التكرار Codacy + SonarCloud + CodeFactor؟ لأن كل واحد منها يرى أشياء مختلفة. Codacy كشف duplications لم يشر إليها SonarCloud. SonarCloud كشف إشارات جودة سيئة (ما يُسمى code smells) تركها Codacy تمر. CodeFactor كشف مشاكل تعقيد تجاهلها الاثنان الآخران. ولا واحد منها كان يكفي وحده. الكلفة الهامشية لمنصة إضافية معدومة (شارة مجانية، تكامل 5 دقائق)، لذلك نضاعف الزوايا.
الاختبارات : unittest stdlib (لا pytest)
229 اختبارًا، 0 regression على مدى 6 أشهر من الـ PR، ~98 % تغطية على الكود الجديد v1.9.
تفصيل نموذجي :
test_silent_failure.py: 97 اختبارًا تستهدف التحقق المزدوجtest_orchestration.py: 79 اختبارًا على pipeline المنسقtest_translation_note_position.py: 38 اختبارًا على مصفوفة الموضع × التنسيقtest_audit_verdict.py: 15 اختبارًا على wrapper pip-audit (داخلscripts/tests/)
ملاحظة صادقة : تغطية ~98 % تخص الكود الجديد v1.9 — لا كل التاريخ الخاص بـ translate.py، الذي لا يزال يحتوي على بعض الدوال الموروثة قليلة التغطية ضمن حزمة الاختبارات الجديدة. أذكر هذا صراحة لأن الإعلان عن «98 % تغطية» على مشروع كامل سيكون مضللًا.
اختيار قابل للنقاش لكنه مقصود : مُشغِّل الاختبارات unittest (stdlib)، لا pytest. البادئة test_ هي بدافع العادة، لكن unittest هو الذي ينفذ. لماذا؟ في مشروع يُدار بـ vibe coding، كل تبعية مضافة = تبعية قد تستخدمها IA بشكل سيئ. البساطة هدف. unittest موجود في المكتبة القياسية لـ Python، بلا تثبيت، بلا plugin.
اختبارات عملية : multi-repo + dogfooding + التحقق من العرض البصري
اختبارات unittest الـ 229 لا تكفي. أضيف ثلاث طبقات من الاختبار العملي :
1. Multi-repo — اختبار السكربت على عدة مستودعات عامة مع README بتنسيقات مختلفة. هذا يكشف حالات حدّية لا تغطيها fixtures — README فيه 8 مستويات heading، وآخر فيه shortcodes موروثة، وثالث فيه code مضمن غريب. في هذه المرحلة كُشف حادث silent-failure الخاص بـ nouveauté 1.
2. Dogfooding على المدونة — jls42.org يُترجم بواسطة السكربت نفسه. كل مقال منشور هو اختبار حي في الإنتاج. إذا مرّت حالة حدّية عبر اختبارات الوحدة، فستظهر هنا، على الصفحة التي تقرأها. إنه الاختبار النهائي — ما هو على الخط هو ما أنتجه المشروع.
3. اختبار العرض البصري — أتحقق من أن الترجمات المعروضة تظهر بشكل صحيح، إما في المتصفح (الصفحة النهائية) أو مباشرة داخل VSCode عبر plugin لمعاينة Markdown. الفكرة : لا نكتفي بـ Markdown صحيح نحويًا، بل نرى العرض الحقيقي. العروض البصرية تكشف أخطاء شكلية (جداول مكسورة، code blocks مشوهة، frontmatter مُفسَّر خطأ) لا تراها اختبارات النص.
تشارك الـ IAs في هذه الاختبارات أيضًا. /pr-review-toolkit ينفذ الكود في بيئة اختبار، واستخدام pair-IA يتضمن دائمًا جولات تحقق بصري («تحقق أن الترجمة الألمانية للصفحة X تُعرض جيدًا»).
📄 مقتطف Python : helper _split_frontmatter (translate.py)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 مقتطف .pre-commit-config.yaml (hooks pre-commit الرئيسية)
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 مقتطف scripts/check-security-sast.sh
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}الضابط 2 : المراجعة المساعدة بالذكاء الاصطناعي + التدفق متعدد النماذج
توضيح في المصطلحات : عندما أتحدث عن Claude Opus في هذا القسم، فأنا أتحدث عن النموذج الذي أستخدمه لتطوير v1.9 — لا عن النموذج الذي يستخدمه AI-Powered Markdown Translator للترجمة. المشروع نفسه يدعم 4 مزودين (OpenAI، Mistral AI، Claude، Gemini) وأي نموذج (Sonnet، Haiku، Mistral Large، Gemini 3 Pro، إلخ). من جهة التطوير، أنا أقفل على Opus. من جهة الاستخدام عند التنفيذ، يظل المشروع محايدًا.
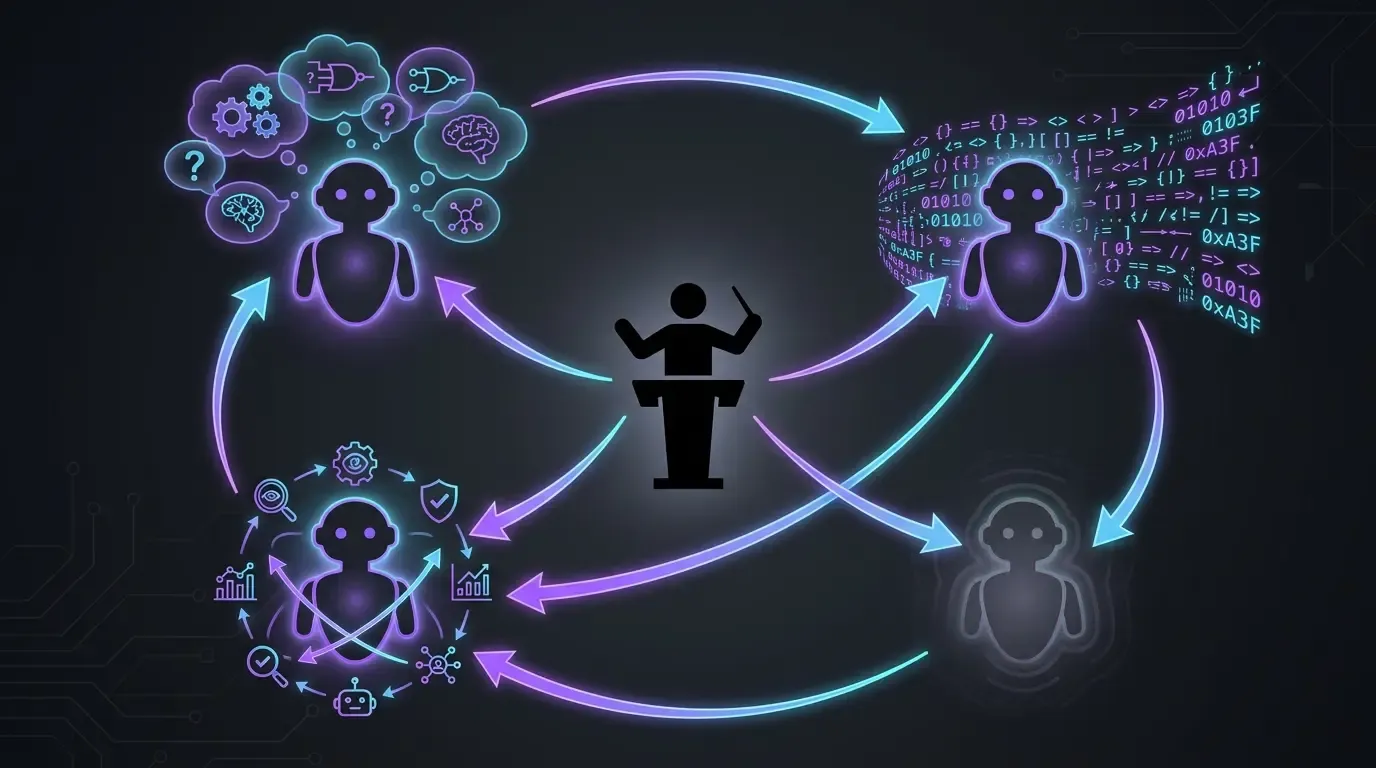
سير العمل الحقيقي: 4 نماذج، 4 أدوار (للتطوير)
- Claude Code على Opus، حصريًا (anthropic): التنفيذ الرئيسي. يقرأ السياق، يكتب الكود، ويطبّق التصحيحات. لا Sonnet، لا Haiku، ولا fast mode. في هذا المشروع، أريد النموذج الأعلى دائمًا — والفكرة بسيطة: نضمن الحصول على الأفضل من أجل السعي إلى أفضل نتيجة ممكنة.
- OpenAI Codex كخيار احتياطي (fallback): يُستخدم في حالتين محددتين:
- عندما يتعثر Opus في موضوع ما (وهذا نادر لكنه يحدث — مثلًا عند التصحيحات المطلوبة من أدوات خارجية مثل Codacy أو SonarCloud، أحيانًا لا يصل Claude إلى نتيجة متقاربة فأحوّل الموضوع إلى Codex لفكّ التعطيل)
- عندما تكون نافذة الاستخدام لدى Anthropic ممتلئة. يتيح Codex عدم فقدان الزخم أثناء انتظار إعادة تعيين الحصة.
- GPT-5.5 reasoning extra-high (
xhigh): يختبر الخطط قبل التنفيذ. قبل أن أترك Claude Code يهاجم موضوعًا ما، أضع الخطة أمام GPT-5.5 في وضع reasoning extra-high. يطرح الأسئلة الصحيحة، ويكشف النقاط العمياء. وهذا يمنع الانطلاق في اتجاه خاطئ سيحتاج إلى تصحيحه لاحقًا. /pr-review-toolkit:review-pr(مكوّن skill في Claude Code): مراجعة قبل الدمج مع وكلاء متخصصين (الأمن، الجودة، الاختبارات، التعليقات، تصميم الأنواع). تعمل المهارة على طلب السحب قبل أن أدمجه — وهي آخر شبكة أمان بالذكاء الاصطناعي قبل دخول الكود إلىmain.
لا يكفي أيٌّ من هذه النماذج وحده. لكل واحد دور مختلف — المنفّذ الأعلى مستوى، البديل عند نقص السعة، متحدّي الخطط، والمراجع متعدد الزوايا.
/pr-review-toolkit : ما كنتُ لأراه
كل شيء. أنا لا أنظر إلى الكود. المهارة ترفع كل شيء — الأخطاء الخفية، مشكلات الأمان، التناقضات في الاختبارات، والاختبارات التي تمرّ لكنها لا تختبر شيئًا.
في طلب السحب رقم 2 (75 commit، 9 837 إضافة، 1 982 حذفًا، 58 ملفًا)، كان إنسان واحد سيتخطّى 80٪ من طلب السحب بسبب الإرهاق. المهارة لا تتخطى شيئًا. إنها تقرأ كل diff، وكل اختبار، وكل تعليق. والأهم أنها تتحدى — ترفض الأنماط التي تتعرّف عليها على أنها سيئة، وتقترح بدائل.
الإنسان كقائد أوركسترا، لا كموسيقي
دوري يغطي السلسلة كاملة — ما عدا كتابة الكود. أرتدي قبعات مدير المنتج (التفكير في الميزات، وترتيب الأولويات، والتحكيم)، وQA (الاختبار على حالات حقيقية، والتحقق بصريًا من الناتج)، والقائد التقني (تحدّي الخطط باستخدام GPT-5.5 reasoning extra-high)، والعميل النهائي (الحكم على النتيجة من خلال تجربتي اليومية الفعلية على المدونة). القبعة الوحيدة التي لا أرتديها هي قبعة البرمجة. أما الباقي، فهو أنا.
أصبحتُ منتجًا، لا موسيقيًا.
في خدمة المدونة: يترجم نفسه بنفسه (نحو 1 800 ترجمة)
AI-Powered Markdown Translator يُنشئ ملف README الخاص به في 14 لغة، وهو الذي ينتج كل النسخ الأجنبية من محتويات jls42.org. عمليًا: نحو 1 800 نسخة مترجمة تغذي المدونة (25 مقالًا + 4 مشاريع + 98 خبرًا عن الذكاء الاصطناعي × 14 لغة، باستثناء المصادر الفرنسية — أي 1 778 نسخة في اللحظة التي أكتب فيها). كل صفحة تتصفحونها هنا بلغة غير الفرنسية مرت عبر هذا المشروع.
هذا استخدام داخلي للمنتج (dogfooding) إلى أقصى حد — وهو يختبر الترجمة تحت الضغط على المقال الذي يتحدث عن الترجمة. إذا كان ما تقرؤونه في ar أو hi أو ko متماسكًا، فهذا يعني أن شبكة الأمان الخاصة بالميزة الجديدة 1 (التحقق بعد الترجمة) تعمل؛ وإذا كانت ملاحظة الترجمة تظهر بشكل صحيح في الأعلى، فهذا يعني أن الميزة الجديدة 2 (الملاحظة متعددة المواضع) تعمل؛ وإذا كانت الاقتباسات EN محفوظة في النسخ اللغوية، فهذا يعني أن الميزة الجديدة 3 (وضع --news) تعمل أيضًا.
الحصيلة: إقران صارم بين الإنسان والذكاء الاصطناعي، لا إقران مرتجل
التطوير حسب الإحساس له سمعة سيئة لأسباب وجيهة. وأنا أعمل تحديدًا ضد هذه الأسباب. تبرز من هذه النسخة 1.9 أربع دروس عملية:
-
الإخفاقات الصامتة هي العدو رقم واحد. ينتج الذكاء الاصطناعي كودًا يبدو جيدًا ويمر عبر الاختبارات الوحدوية. التحقق من جهة العميل يجب أن يكون منهجيًا. واستخدام ذكاء اصطناعي آخر لمراجعة الناتج الفعلي، لا الكود فقط.
-
Hooks ما قبل الالتزام < 10 ثوانٍ وإلا سيتم الالتفاف عليها؛ hooks ما قبل الدفع يمكن أن تستغرق 30 ثانية فأكثر. يميل الذكاء الاصطناعي بسهولة إلى إضافة الأدوات من دون النظر إلى كلفتها. يجب تأطير ذلك يدويًا، إما في الخطة أو بعد ذلك — المهم في النهاية أن تكون hooks مضبوطة جيدًا ومستخدمة فعليًا يوميًا.
-
التغطية من دون تأكيد قوي = مسرحية. يمكن للذكاء الاصطناعي أن يولّد 200 اختبار تمرّ كلها من دون أن تختبر شيئًا. unittest مع تأكيدات دقيقة > pytest مع عدد كبير من mocks. تحقّق من القيمة المرجعة، لا مجرد أن الكود لم ينهَر.
-
مراجعة الذكاء الاصطناعي (PR review) ليست خيارًا. عندما لا يراجع الكاتب البشري، فإن المراجع الآلي ليس مجرد ترف — إنه العين المفوضة.
البرمجة بالحدس إذا أُحسِنَت تعني أيضًا قبول أننا لا نقرأ الكود، وتفويض القراءة النقدية إلى ذكاءات اصطناعية أخرى تقوم بذلك فعلًا.
ما الذي يكشفه هذا المشروع
تُظهر هذه النسخة 1.9 عدة جوانب من طريقة عملي:
- الدور البشري يغطي السلسلة كلها باستثناء الكود: المنتج (التفكير في الميزات، ترتيب الأولويات)، QA (الاختبار على حالات حقيقية، والتحقق بصريًا)، القائد التقني (تحدّي الخطط باستخدام نموذج لغوي في reasoning extra-high)، العميل النهائي (الحكم على الاستخدام الحقيقي). القبعة الوحيدة التي لا أرتديها هي البرمجة.
- مضاعفة شبكات الأمان، لا إزالتها: تقليل المراجعة البشرية = زيادة التحقق بالأدوات. هذا تفاوض مقصود، لا نقص في الصرامة. إذا أزلتُ المراجعة، فعليّ أن أضاعف شبكات الأمان، لا أن أثق بالذكاء الاصطناعي ثقة عمياء.
- الذكاء الاصطناعي لاكتشاف أخطاء الذكاء الاصطناعي: الإخفاق الصامت اكتشفه Claude أثناء الاختبارات العملية متعددة المستودعات. التفويض الكامل: يمكن أيضًا تفويض المراجعة النقدية.
- الإقران بين الإنسان والذكاء الاصطناعي كمضاعف في الوقت الشخصي: أحمل هذا المشروع في أمسياتي وعطلات نهاية الأسبوع. من دون الإقران بين الإنسان والذكاء الاصطناعي، لن أذهب بالتأكيد إلى هذا الحد ولا بهذه السرعة. ومعه، أستطيع الحفاظ على مشروع مفتوح المصدر بمستوى صناعي إلى جانب التزاماتي الأخرى. هذا ما تتيحه البرمجة بالحدس — ليس استبدال المطوّر، بل تمكينه من فعل ما لا يستطيع فعله وحده.
- التحسين التكراري بدل إعادة البناء الكاملة: 9 إصدارات، وإعادة هيكلة تدريجية (من دالة واحدة → 7 helpers)، مع الحفاظ على التوافق العكسي. يساعد الإقران بين الإنسان والذكاء الاصطناعي على التكرار السريع من دون إعادة كتابة كل شيء.
الموارد
- AI-Powered Markdown Translator على GitHub
- الإصدار v1.9
- طلب السحب #2 — 75 commit، الترحيل + الجودة
- سجل التغييرات الكامل
- صفحة المشروع على هذه المدونة
- مقال 2024 — v1.5 (بأسلوب ملاحظات الإصدار) — للمقارنة في النبرة
- الغوص العميق AWS Diagram — مقال آخر في السلسلة
إذا أردتم اختبار AI-Powered Markdown Translator على ملفات Markdown الخاصة بكم — README مفتوح المصدر، مقالات مدونات، توثيق تقني —، فالكود موجود على GitHub. التثبيت يستغرق بضع دقائق، ودعم 4 مزوّدين، ووضع --eco لتقليل الكلفة، ووضع --news للحفاظ على الاقتباسات الأصلية، وأصبح لديكم الآن حزمة جودة v1.9 يمكنكم إعادة استخدامها كقالب لمشاريعكم الخاصة في الإقران بين الإنسان والذكاء الاصطناعي.
إذا كنتم تطوّرون مشاريعكم الشخصية بالحدس (البرمجة بالحدس)، فلا تختاروا أبسط حل من ناحية الجودة. الموثوقية هي ثمن السرعة — فتقبّلوا الاثنين معًا.