ai-powered-markdown-translator由 gpt-5.4-mini 将法语翻译成中文的文章。
AI-Powered Markdown Translator 是一个我自 2024 年起一直维护的开源项目:这是一个 Python 脚本,可通过 4 家 AI 提供方(OpenAI、Mistral AI、Claude、Gemini)把任意 Markdown 文件翻译成 14 种语言。它为这个博客的每次发布提供支持——你在这里读到的每一页,只要不是法语,基本都经过了它——而且它在生产环境中已经驱动了将近 1,800 个已翻译版本。
2026 年 5 月 8 日,我发布了 v1.9,它汇总了 75 次提交,也是自 2024 年 v1.5 以来最大的一次更新。三个产品新功能:
- 翻译后校验(防止静默失败)
- 多位置翻译说明(顶部、底部或两者都放)
--news模式,用于保留英文源引用
但这个 v1.9 有一个我想在这里讲清楚的特点:全部代码都是通过 AI 结对编写的。没有一行是手工输入的。所以除了这 3 个新功能之外,这篇文章还会讲“怎么做”:当你不亲自复查 AI 产出的内容时,如何设置护栏,去追求干净且安全的代码?
背景:一个每天都在用、但代码维护并不频繁的项目
从 2024 年 9 月到 2026 年 5 月:持续使用,间歇维护
我曾经发布过一篇详细介绍 2024 年 v1.5 源代码的文章。那时候,我是直接把脚本贴在文章里。如今角度变了:重要的不再是我写了什么代码,而是生成这些代码的工作流。
在 2024 年 9 月发布的 v1.5 和 2026 年 1 月 之间,这个项目一直在运行——它会翻译这个博客的每一篇新内容——但公开代码几乎没怎么动。2025 年只推过一个提交。期间,我一直在本地按自己的需求演进代码——主要是模型,我会随着新版本发布不断替换——但这些变化都停留在我的机器上。GitLab 上的公开版本仍然指向 v1.5 的默认值。
2026 年初,我做了第一次系统性升级:两个月内发布了三个版本(1 月初两天内的 v1.6 和 v1.7,以及 3 月的 v1.8),把功能层面更新到了最新——2026 年模型、Gemini 支持、--eco 模式、单文件、以及用于源引用的 --news 模式。但依然没有 CI,没有自动化测试,也没有质量门禁——这让我在让一个 AI 代理代我写代码时,无法继续放心往前推。
个人时间里的项目节奏
为什么会有这个时间差?因为这个项目是我用个人时间在维护。我有家庭,屏幕之外也有生活,所以项目只能在我挤出晚间和周末时一段一段地推进。我确实很投入,也会花不少时间在这些事情上——测试很多,指导代理,验证结果——但节奏终究不是职业项目那种。
AI 结对恰好改变了这一点。它让我能在两种约束之间推进——热情和屏幕之外生活的分配。没有 AI 结对,我显然不可能走到这么远,也不可能这么快。有了它,我就能在不把整个人生都投入进去的前提下,维护一个工业级开源项目。
最初目标:质量 + GitLab → GitHub 迁移
2026 年 4 月中旬,我终于决定认真处理这件事。两个简单目标:
- 增加一层质量保障(静态分析、测试、CI)
- 把仓库从 GitLab 迁移到 GitHub
仅此而已。只是,和 AI 结对写代码的代理一起工作时,你永远不会只做你原本计划的事情。最终这个 PR 变成了 75 次提交、9,837 次新增、1,982 次删除、58 个文件。
| 版本 | 日期 | 主要贡献 |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI,随后是 Mistral,再随后是 Claude |
| 1.5 | 2024 年 9 月 | 重构客户端,2024 年模型(gpt-4o、claude-3.5-sonnet) |
| 1.6 | 2026 年 1 月 | 2026 年模型(gpt-5、claude-sonnet-4-5、gemini-3-pro)、Gemini、--eco 模式、单文件(--file) |
| 1.7 | 2026 年 1 月 | --keep_filename、.env、保留内联代码 |
| 1.8 | 2026 年 3 月 | 默认 GPT-5.4 模型、带引用占位符的 --news 模式 |
| 1.9 | 2026 年 5 月 | 翻译后校验、多位置说明、14 个 hooks + 229 个测试 + AI 审查的质量栈 |
雪球效应
每增加一个质量工具,都会暴露新的问题。Codacy 报出了重复代码。SonarCloud 提出了若干 code smells(提示代码将来会难以维护的信号:函数过长、参数未使用、结构绕弯等)。/pr-review-toolkit 指出了隐藏 bug。每次出现问题,代理都会修复,有时还会顺手把相邻部分一起改好。
项目范围就这样自然地膨胀了。这正是我想要的——让项目现代化——但工作量的节奏却由工具决定,而不是由我决定。对于一个 vibe coding 项目来说,这一点很关键:质量工具既在验证工作,也在引导工作。
新功能 1:翻译后校验(防止静默失败)
事故:是 AI 在测试期间发现了 bug
在不同公共仓库的 README 上测试这个 PR 时——这类场景任何 fixture 都没有覆盖——AI 指出了我漏掉的问题:在某些语言中(尤其是印地语,ISO 代码 hi),有些片段在翻译结果里仍然保持源语言。API 已经返回了 200,脚本也把文件写出去了,但内容却只翻译了一半。而这还能穿过现有的单元测试套件——因为那些测试并没有覆盖这个真实的多语言场景。
这正是 vibe coding 可能产生、而且没人会注意到的那类 bug。代码看起来很合理,测试 fixture 没覆盖到这个场景,人类也不会复查结果。可就在这里,当我用真实案例(多仓库)测试脚本时,AI 自己做了 fixture 没做到的事。
我的结论是:真实的多仓库测试能发现单元测试漏掉的问题。而且,AI 也能用来发现前一批 AI 代理留下的 bug——前提是你要把它放到真实且多样的场景里去。
也就是在那一刻,我意识到必须增加真正的翻译后校验。下面我就来讲这个第一项新功能:双层校验。
双层校验
| 步骤 | 操作 | 如果失败 |
|---|---|---|
| 1️⃣ | 调用 provider 的 API | 网络异常 → ❌ failure |
| 2️⃣ | 按 provider 对 finish_reason(或 Claude 的 stop_reason)做白名单校验 | 不在白名单内 → ❌ failure |
| 3️⃣ | 防泄漏:输出中不能出现任何与源文本完全一致、长度 ≥ 120 字符的源窗口 | 找到源窗口 → ❌ failure |
| 4️⃣ | langdetect.detect_langs(源语言与目标语言概率) | 源语言 > 0.80 且目标语言 < 0.20 → ❌ failure |
| 5️⃣ | 空内容 + 输出/源内容比例(若源内容 ≥ 500 字符) | 为空或输出 < max(50, source/20) → ❌ failure |
| ✅ | SUCCESS | exit code 0 |
第 1 层(确定性)——第一道保险:检查 API 返回的状态。每个 provider 都会暴露一个 finish_reason 字段(或 Claude 的 stop_reason),说明 LLM 为什么停止生成。脚本会维护一份按 provider 区分的可接受状态白名单——命名因平台而异(OpenAI/Mistral 用 stop,Gemini 用 STOP 或 FINISH_REASON_STOP,Claude 用 end_turn 或 stop_sequence)。代码还会出于安全考虑容忍 None,尤其是在 SDK 没有返回这个字段时。除此之外的任何状态——例如某些 provider 下的 length、max_tokens 或 MAX_TOKENS,它们表示响应被 token 上限截断——都会立即触发 RuntimeError,不会尝试恢复。
第二道更细的确定性保险:检查源文本中是否有任何片段被原样带入了翻译输出。具体做法是从源文本中提取长度 120 字符或以上的窗口;如果其中任何一个窗口在输出中被完整找到,说明它根本没被翻译——failure。正是这个检查把印地语的案例拦了下来:LLM 返回的是 stop(也就是 API 侧“自然结束”),但输出里仍然保留了法语段落——它们没被 finish_reason 这道保险抓到,却被逐字泄漏检测抓了出来。
第 2 层(概率性)——langdetect.detect_langs 会分析输出语言,并返回对多种候选语言的概率分布。我们取出源语言概率和目标语言概率,然后仅当源语言概率高于 0.80 且目标语言概率低于 0.20 时才拒绝——这个阈值故意设得比较保守,以免把技术性 code-switching 误判为失败(比如法语翻译里合法出现的英文词)。对于非拉丁脚本语言,这一层会直接短路(印地语 hi、阿拉伯语 ar、中文 zh、日语 ja、韩语 ko),因为脚本信号本身就足以验证输出。而且它只会在清理后的输出至少有 100 个字符时才运行,以避免对过短文本产生误报。
定量护栏
在这两层之上,还有两个更朴素但必要的检查:
- 空内容护栏:如果 provider 返回空输出,而
finish_reason是stop,就立刻拒绝(否则会把一个空文件写成 success) - 合理比例检查:只有当源内容至少 500 个字符时,才检查输出是否异常地短(典型情况是 <
max(50, source/20))。这是一种用于发现隐性截断的检测,不是通用长度规则
在 Claude 上,max_tokens 在 v1.9 中从 4,096 提升到了 32,768(这个改动是在我确认症状并要求调查后,由 Claude 在代码侧完成的)。CHANGELOG 里记录的原因是:避免在 16 k 字符片段上出现潜在截断,并为非拉丁脚本语言(FR → JA、ZH、KO、AR、HI)留出额外余量,因为这些语言的输出往往比等长的拉丁脚本消耗更多 token。
按显式状态回传
文件流水线(translate_markdown_file())现在会返回一个显式状态——success、failure 或 skipped。CLI 会聚合这些状态,只要有任意一个文件失败,就以非零退出码结束——这样无论是调用脚本还是 v1.9 新增的 CI,都能直接利用这个失败信号。在这个 v1.9 之前,一些错误只是在日志里打印,或者被当作翻译成功处理:进程甚至可能以 0 结束,而文件却根本不存在、内容不完整,或者校验不正确。skipped 本身也变成了一个可读信号(“故意忽略”),与 success(“翻译已正确写入”)区分开来。
📄 Python 片段:翻译后双重校验(translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejette新功能 2:多位置翻译说明
需求:一个低调但有信息量的说明
当 AI-Powered Markdown Translator 写出译文时,它会附上一段翻译说明,注明所用模型和日期。在 v1.9 之前,这段说明总是固定放在文件底部,使用一种继承下来的(legacy)格式,并带有可见分隔符。
这种固定放在底部的格式对我的使用场景有两个问题。首先,读者只有到最后才知道内容是由 AI 翻译的——更好的做法是从一开始就提醒,这样对内容的预期会更准确。其次,页脚说明并没有凸显支撑这一切的翻译项目:读文章时,驱动多语言输出的来源并不显眼。所以我希望可以把说明移到顶部,同时保留可追溯性——还不能破坏已有用法。v1.9 增加了两个不会破坏兼容性的 flag:
--note_position {top,bottom,both}:顶部、底部或两者都放--note_format {legacy,marker}:传统格式或标记格式(marker format)
向后兼容的默认值:legacy + bottom。现有任何翻译链默认行为都不会改变——只有在需要时才显式启用新 flag。
标记格式:一个干净的 GitHub 嵌入卡片(embed card)
标记格式利用了 Markdown 在 GitHub 上的一个细节:未被使用的 link reference definitions 在渲染结果中是不可见的。因此我们可以把元数据(模型、日期、来源)编码到位于文件顶部的一个注释标记里——浏览器里看不见,但在复制纯文本时会原样保留。
另外,GitHub 在分享指向译文文件的链接时还会生成一张嵌入卡片(embed card),这张卡片会正确显示文档标题,而且不会被多余文本污染。
下面是一个使用顶部 top 标记格式的原始 Markdown 示例:
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...从视觉上看,读者只会看到标题后接正文。这个标记既不会污染 HTML 渲染,也不会污染嵌入卡片。
前置元数据的有意识插入(frontmatter-aware)
一个技术上细节却至关重要的点:在 top 中插入一条注释,并不意味着“插到文件第 1 行”。如果文件带有 YAML frontmatter(这个博客就是如此),就必须在 frontmatter 之后 插入——否则这条注释会把 YAML 弄坏。
我把需求交给 Claude(“把注释插到 frontmatter 后面,不要放前面——否则你会把 YAML 弄坏”),它产出了一个 _split_frontmatter helper,能检测打开/关闭的 --- fence。如果文件有一条未闭合的 YAML fence(格式错误的情况),这个 helper 会抛出一个 RuntimeError,而不是悄悄生成一个损坏的文件。从一个单体函数拆成 7 个纯 helper(彼此分离且可测试),正是指导得当的 pair-IA 擅长快速完成的典型工作。我在这里的角色:需求引导、测试者、最终验收结果的客户。不是写代码。在这个项目里,我身兼多职——唯独不写代码,那部分交给 Claude。
| 位置 | 格式 | 典型使用场景 |
|---|---|---|
top | marker | 博客文章(低调注释、干净的嵌入卡片) |
top | legacy | 内部文档,强调可见追溯性 |
bottom | marker | 开源 README(与页脚一致) |
bottom | legacy | 默认值 — 向后兼容 |
both | marker | 长篇文章,顶部 + 底部更让人放心 |
both | legacy | 具有双重可追溯性要求的遗留场景 |
📄 Python 片段:helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")新功能 3:使用 --news 模式来保留英文来源引文
问题:翻译时不能破坏引文
当我为这个博客撰写 ia-actualites 文章时(AI 多源新闻的日更/周更),我经常引用英文推文、博客文章、版本发布公告——通常每篇都会有好几条。如果翻译碰到这些引文,它们就会失真。
被翻译过的引文,就是被篡改过的引文。在所有语言版本(EN、DE、JA 等)里,我们都想保留引文的英文原文——这是对来源忠实性的要求——同时附上目标语言的国旗,并提供斜体译文以便阅读。
解决方案:占位符 <NEWSQUOTE id="N"/>
| 步骤 | 操作 |
|---|---|
| 1️⃣ | 输入为带有英文引文的 FR Markdown 源文件 |
| 2️⃣ | 预处理:提取英文引文,用占位符 <NEWSQUOTE id="0"/>、<NEWSQUOTE id="1"/> 等替换 |
| 3️⃣ | API 翻译(FR → target_lang)——原始英文引文从不发送给 LLM,发送的只有占位符(原样保留) |
| 4️⃣ | 后处理:用原始英文引文完整恢复占位符,并插入目标语言的国旗 |
| 5️⃣ | 翻译后校验:所有占位符是否都已恢复? |
| ✅ | 目标输出,保留英文引文 |
| ❌ | 若占位符未恢复或引文被篡改,则失败 |
--news 模式依赖于这个原则:先做预处理,提取所有英文引文,替换成类似 <NEWSQUOTE id="0"/> 的占位符,翻译其余内容,再把占位符原封不动地恢复回来。
映射 LANG_FLAGS 会根据 target_lang 调整国旗(覆盖 15 种语言):🇬🇧 代表英语,🇩🇪 代表德语,🇪🇸 代表西班牙语,🇮🇹 代表意大利语,🇵🇹 代表葡萄牙语,🇳🇱 代表荷兰语,🇵🇱 代表波兰语,🇸🇪 代表瑞典语,🇷🇴 代表罗马尼亚语,🇸🇦 代表阿拉伯语,🇮🇳 代表印地语,🇯🇵 代表日语,🇰🇷 代表韩语,🇨🇳 代表中文,🇫🇷 代表法语。
翻译后校验会检查所有占位符是否都被完整恢复。错误不是“EN 泄漏”——EN 本来就是有意保留的——而是占位符未恢复或引文被篡改。
当前用例与展望
今天,我只在博客的 --news 文章上使用 ia-actualites。从长远看,它还可以扩展到任何混合了法语正文和英文来源引文的文章——访谈、引用英文研究论文的经验总结、会议演讲逐字稿。
无需重读代码:为什么必须加倍护栏
「我不读代码。」
我什么都不重读。有时我会快速看一下 diff——这很少,而且只有在 Claude 在某个点上自己搞不定时才会这样。下面就是我日常使用、并且生成了 v1.9 的流程:Claude Code(仅限 Opus)负责写代码。Codex 在 Opus 卡住或用量窗口已满时接棒。GPT-5.5 在 reasoning extra-high 模式下会在执行前审查这些方案。/pr-review-toolkit:review-pr 会在每次 merge 前复查 PR。我的角色到此为止:确认方向并定义护栏。
这种开发方式——完全凭感觉开发(vibe coding)——并不是不严谨。它是一种明确的权衡:更少的人类复审,更多的工具化验证。刚刚介绍的 3 个 v1.9 新功能,全部都是在这个流程里产出的。而也正因为我们不重读代码,才必须加倍技术护栏——不是删掉它们。
下面这两道护栏,就是为了让这种开发方式能够在生产环境中可行:一套自动化质量栈(护栏 1)和一条多模型 AI 辅助审查流程(护栏 2)。
护栏 1:自动化质量栈(14 个 hook + 实践测试)
概览
| 防护网 | 工具 | 典型耗时 | 失败时阻断 |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hooks), detect-secrets, Lizard CCN | < 10 s | 是 |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | 是,除了 pip-audit 处于初始报告模式 |
| CI 外部 | SonarCloud, Codacy, CodeFactor | 并行 | 本地不阻断,PR 徽章 |
v1.9 数据:14 个 hook、229 个 unittest stdlib 测试、新代码约 98 % 覆盖率、11 个 SonarCloud 徽章、3 个外部平台。
pre-commit:快速防护网
| # | 工具 | 版本 | 作用 |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Shell 代码检查 |
| 2 | ruff (lint) | 0.8.6 | Python 代码检查 |
| 3 | ruff (format) | 0.8.6 | Python 格式化 |
| 4 | prettier | 3.1.0 | Markdown / JSON / YAML 格式化 |
| 5 | trailing-whitespace | 5.0.0 | 删除行尾空格 |
| 6 | end-of-file-fixer | 5.0.0 | 强制末尾换行 |
| 7 | check-yaml | 5.0.0 | YAML 语法校验 |
| 8 | check-toml | 5.0.0 | TOML 语法校验 |
| 9 | check-added-large-files | 5.0.0 | 阻止意外添加的大型二进制文件 |
| 10 | check-merge-conflict | 5.0.0 | 检测 Git 冲突标记 |
| 11 | check-executables-have-shebangs | 5.0.0 | 检查可执行文件是否有 shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | 检查带 shebang 的脚本是否可执行 |
| 13 | detect-secrets | 1.5.0 | 检测 API 密钥和机密信息 |
| 14 | check-complexity (Lizard) | local | 对新代码设置循环复杂度上限 |
实测总耗时:整个 repo 约 2 到 3 秒(热缓存情况下,pre-commit run --all-files 计时约 2.4 秒)。对于只改动少量文件的普通提交,会更快。我的经验法则是:超过 10 秒,开发者就会绕过(pair-IA 也是如此)——所以这个快速防护网必须始终保留。
pre-push:重型防护网
- mypy:宽松模式;不是完全 strict(历史代码的 translate.py 过不了),而是对新代码做进展性检查
- Opengrep SAST:
p/security-audit p/default p/python—— 大约 30 秒,用于扫描注入、eval、不安全反序列化 - pip-audit 由
scripts/check-pip-audit.sh包装:捕获 JSON 输出,在 shell 侧对传输错误(网络、PyPI 挂掉)进行分类,避免把漏洞和不可用性混为一谈,并报告漏洞。v1.9 采用初始报告模式(warn + exit 0)——等依赖过期项的 bump PR 之后再加严,改为阻断。 - unittest discovery:先
python -m unittest discover,再在tests/上跑scripts/tests/—— 229 个测试,本地约 8 秒
外部 CI:SonarCloud + Codacy + CodeFactor
工作流 .github/workflows/sonarcloud.yml(project key jls42_ai-powered-markdown-translator)会在每个 PR 上运行。README 上展示了 11 个 SonarCloud 徽章:质量门禁、安全性/可靠性/可维护性评级、覆盖率、漏洞、缺陷、代码异味、重复代码、技术债务、LOC。
为什么要让 Codacy + SonarCloud + CodeFactor 互相冗余?因为它们各自看到的东西不同。Codacy 报出了 SonarCloud 没提示的重复代码。SonarCloud 报出了 Codacy 放过的低质量信号(也就是那些所谓的 code smells)。CodeFactor 报出了另外两个都忽略的复杂度问题。单靠任何一个都不够。额外增加一个平台的边际成本几乎为零(免费徽章、5 分钟集成),所以就多角度覆盖。
测试:stdlib 的 unittest(不是 pytest)
229 个测试,PR 的 6 个月内 0 回归,v1.9 新代码约 98 % 覆盖率。
典型细分:
test_silent_failure.py:97 个测试,针对双重校验test_orchestration.py:79 个测试,针对编排流水线test_translation_note_position.py:38 个测试,针对 position × format 矩阵test_audit_verdict.py:15 个测试,针对 pip-audit wrapper(在scripts/tests/中)
诚信说明:约 98 % 的覆盖率指的是 v1.9 的新代码——不是整个 translate.py 的历史代码库,后者仍然包含一些遗留函数,新测试套件对它们覆盖得还不够。我之所以明确说明这一点,是因为如果对整个项目宣称“98 % 覆盖率”,那就会误导人。
一个有争议但我认同的选择:使用 unittest 测试执行器(stdlib),不是 pytest。test_ 前缀只是沿用习惯,但真正执行的是 unittest。为什么?在一个 vibe coding 项目里,每新增一个依赖 = IA 就可能多误用一个依赖。简洁是目标。unittest 已经在 Python 标准库里了,不需要安装,也不需要插件。
实践测试:多仓库 + 产品内部自用(dogfooding)+ 可视化渲染校验
229 个 unittest 还不够。我还加了三层实践测试:
1. 多仓库——在多个带有不同格式 README 的公共仓库上测试脚本。这会暴露出 fixtures 覆盖不到的边界情况——一个有 8 级标题的 README、另一个带有遗留 shortcodes 的 README、第三个带有奇特内嵌代码的 README。正是在这个阶段,Nouveauté 1 的 silent-failure 事故被发现了。
2. 在博客上自用(dogfooding)——jls42.org 由脚本自身翻译。每一篇发布的文章都是生产环境中的实时测试。如果某个边界情况逃过了单元测试,它就会在这里出现,在你正在阅读的这一页上。这是终极测试——线上呈现的,就是项目真正产出的东西。
3. 可视化渲染测试——我会检查渲染后的翻译是否正确显示,要么在浏览器里看最终网页,要么直接通过 VSCode 的 Markdown 预览插件查看。核心思想:不只满足于语法上有效的 Markdown,而是直接看真实渲染效果。可视化渲染会暴露文本测试看不到的外观问题(表格损坏、代码块格式错误、frontmatter 解析错误)。
这些测试也有 IA 参与。/pr-review-toolkit 会在测试环境里执行代码,而 pair-IA 的使用流程里会系统性地加入可视化校验步骤(“检查 X 页面德语翻译是否正常显示”)。
📄 .pre-commit-config.yaml 片段(主要的 pre-commit hooks)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 scripts/check-security-sast.sh 片段
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 .github/workflows/sonarcloud.yml 片段
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}护栏 2:AI 辅助审查 + 多模型流程
术语说明:当我在这一节里说 Claude Opus 时,我指的是我用来开发 v1.9 的模型——不是 AI-Powered Markdown Translator 用来翻译的模型。这个项目本身支持 4 个 provider(OpenAI、Mistral AI、Claude、Gemini),以及任意模型(Sonnet、Haiku、Mistral Large、Gemini 3 Pro 等)。在开发侧,我锁定为 Opus;在实际运行侧,项目保持模型无关。
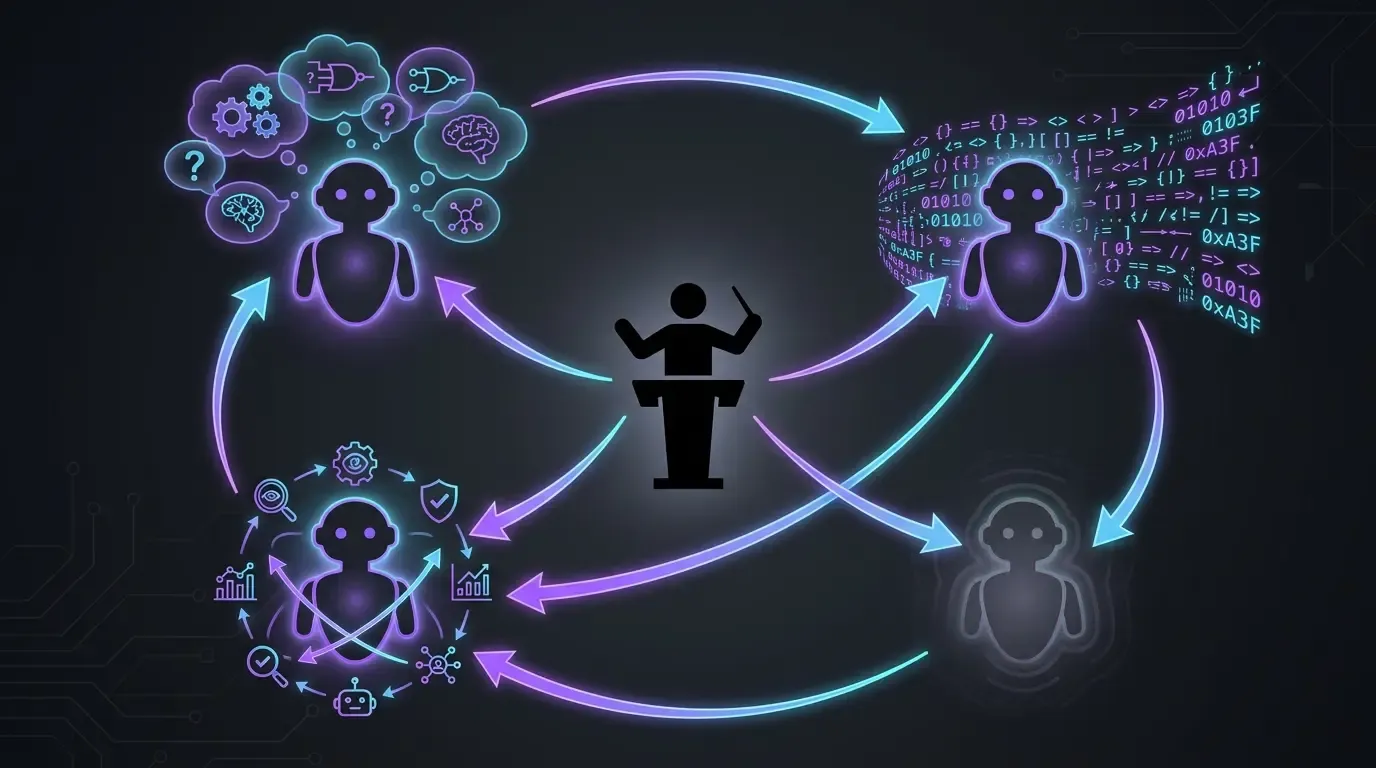
真实的工作流:4 个模型,4 个角色(用于开发)
- Claude Code 中的 Opus,且仅限于 Opus(anthropic):主要执行者。读取上下文、编写代码、应用修正。不要 Sonnet,不要 Haiku,不要 fast mode。在这个项目里,我每次都要用最高端的模型——思路很简单:确保拿到最好的,去争取尽可能好的结果。
- OpenAI Codex 作为后备方案(fallback):在两个明确场景下使用:
- 当 Opus 在某个问题上卡住时(虽然少见,但确实会发生——例如外部代理如 Codacy 或 SonarCloud 提出的修正,Claude 有时无法收敛,这时我会把问题切到 Codex 来解锁)
- 当 Anthropic 的使用额度窗口已满时。Codex 可以让我在等待配额重置期间不丢掉推进节奏。
- GPT-5.5 reasoning extra-high (
xhigh):在执行之前挑战方案。在让 Claude Code 开始处理某个问题之前,我会先把计划交给 GPT-5.5 的 reasoning extra-high。它会提出正确的问题,指出盲点。这能避免一开始就走错方向,之后还得返工。 /pr-review-toolkit:review-pr(Claude Code 的 skill plugin):在合并前进行复审,由专门代理负责(安全、质量、测试、注释、类型设计)。这个 skill 会在 PR 上运行,等我确认后再 merge——这是代码进入main之前,最后一道 AI 防线。
没有任何一个模型能单独完成全部工作。每个模型都承担不同角色——高端执行者、容量替补、计划挑战者、多角度复审者。
/pr-review-toolkit:我本来不会看到的东西
全部。我不看代码。这个 skill 会把一切都提出来——隐藏的 bug、安全问题、测试不一致、看起来通过了但实际上什么也没测到的测试。
在 PR #2(75 个 commits、9 837 次新增、1 982 次删除、58 个文件)上,单靠人类自己,疲劳之下会跳过 80% 的 PR。这个 skill 不会跳过任何东西。它会逐个阅读每个 diff、每个测试、每条评论。更重要的是,它会主动挑战——凡是被它识别为不好的模式,它都会拒绝,并给出替代方案。
人类是指挥,而不是演奏者
我的角色覆盖整条链路——除了写代码。我扮演 产品负责人(思考功能、排优先级、做取舍)、QA(在真实场景中测试、目视验证渲染效果)、tech lead(用 GPT-5.5 reasoning extra-high 挑战方案)、最终客户(基于我在博客上的日常使用体验来判断结果)。我唯一不扮演的角色,就是写代码。其余的,都是我。
我已经成了制作人,而不是音乐家。
为博客服务:它自己给自己做翻译(近 1 800 次翻译)
AI-Powered Markdown Translator 会用 14 种语言生成自己的 README,而它也负责生成 jls42.org 上所有外语内容。具体来说:近 1 800 个翻译版本在为博客供稿(25 篇文章 + 4 个项目 + 98 条 AI 新闻 × 14 种语言,不含法语源文——写这段时总计 1 778 个版本)。你在这里看到的任何非法语页面,都是经过这个项目处理的。
这是一种极致的产品内部使用(dogfooding)——同时也在对“翻译一篇讲翻译的文章”进行压力测试。如果你在 ar、hi 或 ko 中读到的内容是连贯的,那就说明新特性 1(翻译后验证)的安全网是有效的;如果翻译说明正确显示在顶部,那就说明新特性 2(多位置说明)工作正常;如果英文引文在各语言版本中被保留,那就说明新特性 3(--news 模式)也生效了。
结论:严谨的 AI 搭档,而不是粗糙的 AI 搭档
靠感觉开发之所以口碑不好,是有充分理由的。我正是针对这些问题在做事。这一版 v1.9 提炼出四条具体经验:
-
静默失败是头号敌人。 AI 生成的代码看起来没问题,也能通过单元测试。必须在客户端做系统性验证。并且要用另一套 AI 来复审真实产出,而不只是代码本身。
-
pre-commit 钩子若超过 10 秒就会被绕过;pre-push 可以接受 30 秒以上。 AI 很乐意加工具,却不会考虑成本。需要手动设定边界,放在计划里或者事后补救都可以——关键是最后这些钩子要真正调好,并且在日常里确实被使用。
-
没有强断言的覆盖率就是表演。 AI 能生成 200 个测试,它们都能通过,但什么也没测到。unittest + 精确断言 > 大量 mock 的 pytest。要验证返回值,而不只是确认代码没崩。
-
AI 的(PR review)不是可选项。 当人类作者没有复审时,AI 复审不是花架子——它是被委托的眼睛。
把 vibe coding 做好,也意味着接受自己不会读代码,并把批判性阅读委托给那些真正会读的其他 AI。
这个项目揭示了什么
这个 v1.9 体现了我工作方式的几个方面:
- 人的角色覆盖整条链路,唯独不写代码:产品(思考功能、排优先级)、QA(在真实场景中测试、目视验证)、tech lead(用 reasoning extra-high 的 LLM 挑战方案)、最终客户(基于真实使用来判断)。我唯一不做的事,就是写代码。
- 是增加安全网,而不是取消安全网:人工复审更少 = 工具化验证更多。这是有意为之的折中,不是严谨性不足。如果我取消复审,就必须把安全网加倍,而不是盲目相信 AI。
- 用 AI 发现 AI 的 bug:这个静默失败是在多仓库的实测中被 Claude 发现的。完全委托也意味着:我们也可以把批判性复审委托出去。
- 把 pair-IA 当作业余时间的放大器:我是在晚上和周末推进这个项目的。没有 pair-IA,我显然不可能走得这么远、这么快。有了它,我就能在其他职责之外,把一个开源项目维持在工业级水平。这就是 vibe coding 的意义——不是替代开发者,而是让开发者做成一个人做不到的事。
- 迭代,而不是推倒重来:9 个版本,渐进式重构(1 个函数 → 7 个 helper),并保留向后兼容。pair-IA 帮助我快速迭代,而不用把一切全部重写。
资源
- GitHub 上的 AI-Powered Markdown Translator
- v1.9 发布版本
- PR #2 — 75 个 commits,迁移 + 质量
- 完整 CHANGELOG
- 本博客上的项目页面
- 2024 年文章——v1.5(release notes 风格) —— 用来比较语气
- AWS Diagram 深度解析 —— 该系列中的另一篇文章
如果你想把 AI-Powered Markdown Translator 用在你自己的 Markdown 上——开源 README、博客文章、技术文档——,代码在 GitHub 上。几分钟即可安装,支持 4 个 provider,--eco 模式可降低成本,--news 模式可保留源引文,如今还配有你可以在自己的 pair-IA 项目中直接复用的 v1.9 质量栈模板。
如果你用 vibe coding 来开发个人项目,不要在质量上走最省事的路。可靠性就是速度的代价——把两者一起承担起来。