ai-powered-markdown-translatorArtículo traducido del fr al es con gpt-5.4-mini.
AI-Powered Markdown Translator es un proyecto de código abierto que mantengo desde 2024: un script Python que traduce cualquier archivo Markdown a 14 idiomas a través de 4 proveedores de IA (OpenAI, Mistral AI, Claude, Gemini). Alimenta este blog con cada publicación — toda página que lees aquí en un idioma distinto del francés ha pasado por él — y casi 1 800 versiones traducidas funcionan gracias a él en producción.
El 8 de mayo de 2026 publiqué la v1.9, que agrupa 75 commits y marca la mayor actualización desde la v1.5 de 2024. Tres novedades de producto:
- Validación pos-traducción (anti-fallo silencioso)
- Nota de traducción multiposición (arriba, abajo o ambas)
- Modo
--newspara preservar las citas fuente EN
Pero esta v1.9 tiene una particularidad que quiero contar aquí: todo el código fue escrito en pair-IA. Ni una sola línea tecleada a mano. Así que, además de las 3 novedades, el artículo aborda el «cómo»: qué salvaguardas se ponen en marcha para apuntar a un código limpio y seguro cuando uno no relee por sí mismo lo que produce la IA.
El contexto: un proyecto usado todos los días, poco mantenido del lado del código
De septiembre de 2024 a mayo de 2026: uso continuo, mantenimiento a trompicones
Había publicado un artículo que detallaba el código fuente de la v1.5 en 2024. En aquel momento, publicaba el script directamente en el artículo. Hoy, el ángulo ha cambiado: lo que importa ya no es tanto el código que escribo, sino el flujo de trabajo que lo produce.
Entre la v1.5 publicada en septiembre de 2024 y enero de 2026, el proyecto siguió funcionando — traduce cada nuevo contenido de este blog — pero el código público casi no se movió. Solo se subió un commit en 2025. Durante todo ese tiempo, fui haciendo evolucionar el código en local para mis necesidades personales — sobre todo los modelos, que iba sustituyendo según salían — pero esas evoluciones se quedaban en mi máquina. La versión pública en GitLab seguía apuntando a los valores por defecto de la v1.5.
A principios de 2026, hice un primer esfuerzo de puesta al día: tres releases en dos meses (v1.6 y v1.7 en dos días a comienzos de enero, v1.8 en marzo) que actualizaron el proyecto en cuanto a funcionalidades — modelos 2026, soporte de Gemini, modo --eco, archivo único, modo --news para las citas fuente. Pero seguía sin CI, sin tests automatizados, sin gates de calidad — lo que me planteaba un verdadero problema para ir más lejos con un agente IA que codifica en mi lugar.
El ritmo de un proyecto en tiempo libre
¿Por qué ese desfase? Porque llevo este proyecto en mi tiempo libre. Tengo una familia, una vida fuera de la pantalla, así que la evolución solo avanza a trompicones cuando encuentro las noches y los fines de semana. Me apasiona, sigo dedicando bastante tiempo a estos temas — pruebo mucho, guío a los agentes, valido los resultados — pero el ritmo no es el de un proyecto profesional.
El pair-IA cambia precisamente eso. Me permite avanzar entre dos restricciones — la pasión y la dosis de vida fuera de la pantalla. Sin pair-IA, claramente no iría tan lejos ni tan rápido. Con él, puedo mantener un proyecto de código abierto de nivel industrial sin dedicarle mi vida.
El objetivo inicial: calidad + migración GitLab → GitHub
A mediados de abril de 2026 quise ocuparme por fin en serio. Dos objetivos simples:
- Añadir una capa de calidad (análisis estático, tests, CI)
- Migrar el repo de GitLab a GitHub
Nada más. Salvo que con un agente de código en pair-IA, nunca se escribe lo que estaba previsto. La PR terminó con 75 commits, 9 837 adiciones, 1 982 supresiones, 58 archivos.
| Versión | Fecha | Aporte principal |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, luego Mistral, luego Claude |
| 1.5 | sept. 2024 | Refactor de clientes, modelos 2024 (gpt-4o, claude-3.5-sonnet) |
| 1.6 | ene. 2026 | Modelos 2026 (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, modo --eco, archivo único (--file) |
| 1.7 | ene. 2026 | --keep_filename, .env, código inline preservado |
| 1.8 | mar. 2026 | Modelos GPT-5.4 por defecto, modo --news con marcadores de posición de citas |
| 1.9 | mayo 2026 | Validación pos-traducción, nota multiposición, stack de calidad 14 hooks + 229 tests + revisión IA |
El efecto bola de nieve
Cada herramienta de calidad añadida revelaba problemas. Codacy señalaba duplicaciones. SonarCloud sacaba a la luz code smells (señales de código que envejecerá mal: funciones demasiado largas, parámetros no utilizados, estructuras enrevesadas). /pr-review-toolkit detectó bugs ocultos. Con cada aviso, el agente corregía, a veces mejorando también cosas adyacentes.
El alcance creció orgánicamente. Era exactamente lo que quería — modernizar el proyecto — pero la magnitud del esfuerzo la dictaban las herramientas, no yo. Para un proyecto en vibe coding, este es un punto clave: las herramientas de calidad orientan el trabajo tanto como lo verifican.
Novedad 1: la validación pos-traducción (anti-fallo silencioso)
El incidente: fue la IA la que encontró el bug, durante las pruebas
Al probar la PR sobre README de distintos repos públicos — un caso que ninguna fixture cubría —, la IA señaló lo que yo había pasado por alto: en algunos idiomas (especialmente el hindi, código ISO hi), algunos fragmentos seguían en el idioma fuente en medio de la traducción. La API había devuelto 200, el script había escrito el archivo, pero el contenido estaba a medio traducir. Y eso pasaba a través de la batería de tests unitarios existente — que no cubría ese caso real multilingüe.
Ese es exactamente el tipo de bug que puede producir el vibe coding y que nadie ve. El código parece lógico, las fixtures de test no cubren el caso, el humano no relee el resultado. Pero aquí, al probar el script sobre casos reales (multi-repo), la propia IA hizo lo que las fixtures no hacían.
Lo que saco en limpio: los tests prácticos multi-repo encuentran lo que los tests unitarios pasan por alto. Y la IA también puede servir para descubrir bugs de agentes IA anteriores — siempre que la pongas frente a casos reales variados.
Fue en ese momento cuando entendí que hacía falta añadir una verdadera validación pos-traducción. Esa es la primera novedad que detallo ahora: la doble capa de validación.
La doble capa de validación
| Etapa | Acción | Si falla |
|---|---|---|
| 1️⃣ | Llamada a la API del proveedor | Excepción de red → ❌ fallo |
| 2️⃣ | Lista blanca por proveedor de finish_reason (o stop_reason en Claude) | Fuera de la lista blanca → ❌ fallo |
| 3️⃣ | Anti-fuga: ninguna ventana fuente ≥ 120 caracteres aparece verbatim en la salida | Ventana fuente encontrada → ❌ fallo |
| 4️⃣ | langdetect.detect_langs (probabilidades fuente vs target) | Fuente > 0,80 Y target < 0,20 → ❌ fallo |
| 5️⃣ | Contenido vacío + ratio salida/fuente (si la fuente ≥ 500 caracteres) | Vacío o salida < max(50, source/20) → ❌ fallo |
| ✅ | SUCCESS | exit code 0 |
Capa 1 (determinista) — Primer filtro: comprobar el estado devuelto por la API. Cada proveedor expone un campo finish_reason (o stop_reason en Claude) que indica por qué el LLM dejó de generar. El script mantiene una lista blanca por proveedor de los estados aceptables — la nomenclatura varía (stop en OpenAI/Mistral, STOP o FINISH_REASON_STOP en Gemini, end_turn o stop_sequence en Claude). El código también tolera None por seguridad, cuando el SDK no devuelve ese campo. Cualquier otro estado — por ejemplo length, max_tokens o MAX_TOKENS según el proveedor, que señalan una respuesta detenida por el límite de tokens — desencadena un RuntimeError inmediato, sin intento de recuperación.
Segundo filtro determinista, más sutil: comprobar que ningún fragmento del texto fuente aparece verbatim en la salida traducida. Concretamente, se extraen ventanas de 120 caracteres o más desde el texto fuente; si una de ellas se encuentra tal cual en la salida, significa que no se tradujo — failure. Precisamente este chequeo fue el que salvó el caso hindi: el LLM había respondido stop (es decir, fin «natural» del lado de la API), pero algunos párrafos franceses se habían quedado intactos en la salida — invisibles al filtro finish_reason, detectados por el filtro anti-fuga verbatim.
Capa 2 (probabilística) — langdetect.detect_langs analiza el idioma de la salida y devuelve una distribución de probabilidades sobre varias lenguas candidatas. Se extrae la probabilidad del idioma fuente y la del idioma destino, y luego se rechaza solo si la prob fuente supera 0,80 y la prob target cae por debajo de 0,20 — un umbral deliberadamente conservador para no generar falsos positivos en el code-switching técnico (palabras inglesas legítimas en una traducción francesa, por ejemplo). Esta capa se salta para idiomas con escritura no latina (hindi hi, árabe ar, chino zh, japonés ja, coreano ko) donde una señal de escritura suficiente ya valida la salida. Y solo se ejecuta si la salida limpiada tiene al menos 100 caracteres, para evitar falsos positivos en textos demasiado cortos.
Las salvaguardas cuantitativas
Por encima de las dos capas, dos controles más prosaicos pero necesarios:
- Guarda de contenido vacío: si el proveedor devuelve una salida vacía mientras
finish_reasonesstop, se rechaza de inmediato (si no, escribiríamos un archivo vacío marcado como success) - Relación de seguridad: solo si la fuente tiene al menos 500 caracteres, se comprueba que la salida no sea sospechosamente corta (típicamente <
max(50, source/20)). Es un detector de truncación invisible, no una regla general de longitud
En Claude específicamente, max_tokens pasó de 4 096 a 32 768 en la v1.9 (la modificación la hizo Claude en el código después de que yo constatara el síntoma y le pidiera investigar). La razón documentada en el CHANGELOG: evitar la truncación latente en segmentos de 16 k caracteres, con un margen adicional para los idiomas con escritura no latina (FR → JA, ZH, KO, AR, HI) que consumen más tokens en salida que un script latino equivalente.
Respuestas por estado explícito
El pipeline de archivo (translate_markdown_file()) devuelve ahora un estado explícito — success, failure o skipped. El CLI agrega estos estados y termina con un código de salida distinto de cero en cuanto falla al menos un archivo, lo que hace que el fallo sea aprovechable por un script llamador o por la nueva CI añadida en la v1.9. Antes de esta v1.9, varios errores solo se imprimían o pasaban como una traducción exitosa: el proceso podía terminar en 0 aunque el archivo estuviera ausente, incompleto o mal validado. El estado skipped se convierte en sí mismo en una señal legible («ignorado voluntariamente»), distinta de success («traducción escrita correctamente»).
📄 Extracto de Python: doble validación pos-traducción (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNovedad 2: la nota de traducción multiposición
La necesidad: una nota discreta pero informativa
Cuando AI-Powered Markdown Translator escribe una traducción, añade una nota de traducción que indica el modelo utilizado y la fecha. Antes de la v1.9, esa nota se pegaba sistemáticamente al final del archivo, en un formato heredado (legacy) con delimitadores visibles.
El formato pegado al final planteaba dos problemas para mis propios usos. Primero, el lector solo se enteraba al final de que el contenido había sido traducido por IA — es mejor avisar desde el principio, eso crea una expectativa correcta sobre el contenido. Además, la nota al pie no ponía en valor el proyecto de traducción que hace todo esto posible: uno lee el artículo, y el origen del flujo multilingüe pasa desapercibido. Quería, por tanto, poder mover la nota arriba manteniendo la trazabilidad — sin romper los usos existentes. La v1.9 añade dos flags que no rompen nada:
--note_position {top,bottom,both}: arriba, abajo o ambas--note_format {legacy,marker}: formato heredado o formato marcador (marker format)
Valores por defecto retrocompatibles: legacy + bottom. Ninguna cadena de traducción existente cambia de comportamiento por defecto — se activan explícitamente los nuevos flags cuando se solicitan.
El formato marcador: una tarjeta incrustada (embed card) de GitHub limpia
El formato marcador aprovecha un detalle sutil del Markdown de GitHub: las definiciones de referencias de enlace no utilizadas son invisibles en el renderizado. Así se pueden codificar metadatos (modelo, fecha, fuente) en un comentario-marcador situado en la parte superior del archivo — invisible en el navegador, pero conservado tal cual al copiar en bruto.
Además, GitHub genera una tarjeta incrustada (embed card) cuando se comparte un enlace al archivo traducido, y esa tarjeta muestra bien el título del documento sin ruido textual.
Ejemplo de Markdown en bruto con formato marcador en posición top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...A simple vista, el lector solo ve el título seguido del contenido. El marcador no ensucia ni el renderizado HTML ni la tarjeta de embed.
La inserción consciente del frontmatter (frontmatter-aware)
Detalle técnico pero crucial: insertar una nota en top no significa «insertar en la línea 1 del archivo». Si el archivo tiene un frontmatter YAML (que es el caso de este blog), hay que insertar después del frontmatter — si no, la nota rompe el YAML.
Le di la necesidad a Claude («inserta la nota después del frontmatter, no antes — si no, rompes el YAML»), y sacó un helper _split_frontmatter que detecta las fences --- de apertura/cierre. Si el archivo tiene una fence YAML sin cerrar (caso malformado), el helper lanza una RuntimeError en lugar de producir silenciosamente un archivo roto. El paso de una función monolítica a 7 helpers puros (separados y testeables) es típico de lo que un pair-IA bien guiado sabe hacer rápido. Mi papel aquí: guía de la necesidad, tester, cliente final que valida el resultado. No programar. En este proyecto llevo varias gorros — salvo el de escribir el código, que le toca a Claude.
| Posición | Formato | Caso de uso típico |
|---|---|---|
top | marker | Artículos de blog (nota discreta, embed card limpio) |
top | legacy | Doc interna donde importa la trazabilidad visible |
bottom | marker | README open source (coherente con el footer) |
bottom | legacy | Predeterminados — compatible con versiones anteriores |
both | marker | Artículos largos donde top + bottom tranquilizan |
both | legacy | Caso legacy con exigencia de doble trazabilidad |
📄 Extracto de Python: helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")Novedad 3: el modo --news para preservar las citas fuente EN
El problema: traducir sin romper las citas
Cuando escribo artículos ia-actualites para este blog (noticias IA multi-source diarias/semanales), cito regularmente tweets, entradas de blog, anuncios de versión en inglés — a menudo varias por artículo. Si la traducción toca las citas, se vuelven falsas.
Una cita traducida es una cita alterada. En todas las versiones lingüísticas (EN, DE, JA, etc.), queremos mantener el inglés original de las citas — es una exigencia de fidelidad a las fuentes — acompañado de la bandera del idioma objetivo y una traducción en cursiva para la comodidad de lectura.
La solución: placeholders <NEWSQUOTE id="N"/>
| Paso | Acción |
|---|---|
| 1️⃣ | Markdown fuente FR con citas EN en entrada |
| 2️⃣ | Preprocesado: extracción de las citas EN, reemplazo por placeholders <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, etc. |
| 3️⃣ | Traducción API (FR → target_lang) — las citas EN originales nunca se envían al LLM, solo los placeholders (preservados tal cual) |
| 4️⃣ | Posprocesado: restauración de los placeholders con las citas EN originales intactas + inserción de la bandera del idioma objetivo |
| 5️⃣ | Validación post-traducción: ¿se han restaurado todos los placeholders? |
| ✅ | Salida objetivo con citas EN preservadas |
| ❌ | Fallo si un placeholder no se restaura o si la cita se altera |
El modo --news se apoya en este principio: un preprocesado extrae todas las citas EN, las reemplaza por placeholders tipo <NEWSQUOTE id="0"/>, traduce el resto y restaura los placeholders intactos.
El mapping LANG_FLAGS adapta la bandera a la target_lang (15 idiomas cubiertos): 🇬🇧 para inglés, 🇩🇪 para alemán, 🇪🇸 para español, 🇮🇹 para italiano, 🇵🇹 para portugués, 🇳🇱 para neerlandés, 🇵🇱 para polaco, 🇸🇪 para sueco, 🇷🇴 para rumano, 🇸🇦 para árabe, 🇮🇳 para hindi, 🇯🇵 para japonés, 🇰🇷 para coreano, 🇨🇳 para chino, 🇫🇷 para francés.
La validación post-traducción comprueba que todos los placeholders se restauran intactos. El error no es una «fuga EN» — el EN es deseado — sino un placeholder no restaurado o una cita alterada.
Casos de uso actuales y perspectivas
Hoy, utilizo --news exclusivamente sobre los artículos ia-actualites del blog. A medio plazo, esto podría extenderse a cualquier artículo que mezcle prosa francesa y citas fuente EN — entrevistas, relatos de experiencia que citan artículos de investigación en inglés, transcripciones de presentaciones de conferencias.
Sin releer el código: por qué hay que duplicar los guardarraíles
«No leo el código.»
No releo nada. A veces miro un diff por encima — es raro, y solo cuando Claude no sale solo de un punto. Este es el flujo que uso a diario y que produjo la v1.9: Claude Code (Opus, exclusivamente) teclea el código. Codex toma el relevo cuando Opus se bloquea o la ventana de uso está saturada. GPT-5.5 en reasoning extra-high desafía los planes antes de la ejecución. /pr-review-toolkit:review-pr relee la PR antes de cada merge. Mi papel se limita a validar las direcciones y definir los guardarraíles.
Este modo de desarrollo — desarrollo al feeling (vibe coding) integral — no es una falta de rigor. Es un compromiso explícito: menos releer humano, más validación instrumentada. Las 3 novedades v1.9 que acabo de presentar se produjeron todas en este flujo. Y precisamente porque no se relee el código hay que duplicar los guardarraíles técnicos — no eliminarlos.
Aquí están los dos guardarraíles implementados para hacer viable este modo de desarrollo en producción: una pila de calidad automatizada (Guardarraíl 1) y una revisión asistida por IA en flujo multimodelo (Guardarraíl 2).
Guardarraíl 1: la pila de calidad automatizada (14 hooks + tests prácticos)
Visión general
| Red | Herramientas | Costo típico | Bloqueante si falla |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hooks), detect-secrets, Lizard CCN | < 10 s | Sí |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Sí, salvo pip-audit en reporting inicial |
| CI externa | SonarCloud, Codacy, CodeFactor | en paralelo | No bloqueante local, badges PR |
Cifras v1.9: 14 hooks, 229 tests unittest stdlib, ~98 % de cobertura sobre el nuevo código v1.9, 11 badges de SonarCloud, 3 plataformas externas.
Pre-commit: la red rápida
| # | Herramienta | Versión | Rol |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Lint shell |
| 2 | ruff (lint) | 0.8.6 | Lint Python |
| 3 | ruff (format) | 0.8.6 | Formateo Python |
| 4 | prettier | 3.1.0 | Formateo Markdown / JSON / YAML |
| 5 | trailing-whitespace | 5.0.0 | Eliminación de espacios al final de línea |
| 6 | end-of-file-fixer | 5.0.0 | Nueva línea final obligatoria |
| 7 | check-yaml | 5.0.0 | Validación de sintaxis YAML |
| 8 | check-toml | 5.0.0 | Validación de sintaxis TOML |
| 9 | check-added-large-files | 5.0.0 | Bloquea binarios grandes añadidos por accidente |
| 10 | check-merge-conflict | 5.0.0 | Detección de marcadores de conflicto Git |
| 11 | check-executables-have-shebangs | 5.0.0 | Verifica que los ejecutables tengan un shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Verifica que los scripts con shebang sean ejecutables |
| 13 | detect-secrets | 1.5.0 | Detección de claves API y secretos |
| 14 | check-complexity (Lizard) | local | Tope de complejidad ciclomática sobre el nuevo código |
Total medido: unos 2 a 3 segundos en todo el repo (en caliente, pre-commit run --all-files cronometrado en ~2,4 s). En un commit medio que solo toca unos pocos archivos, es aún más rápido. La regla práctica que aplico: por encima de 10 s, los desarrolladores lo rodean (el pair-IA también) — así que hay que mantener esta red rápida en todo momento.
Pre-push: la red pesada
- mypy en modo laxo: no hay strict total (el código histórico de translate.py no pasaría), pero sí una verificación de progreso sobre el nuevo código
- Opengrep SAST:
p/security-audit p/default p/python— unos 30 segundos para escanear inyecciones, eval, deserialización insegura - pip-audit envuelto por
scripts/check-pip-audit.sh: captura la salida JSON, clasifica del lado shell los errores de transporte (red, caída de PyPI) para no confundir vulnerabilidad e indisponibilidad, y reporta las vulnerabilidades. En modo reporting inicial para la v1.9 (warn + exit 0) — a endurecer en bloqueo después de una PR de bump de dependencias obsoletas. - unittest discovery:
python -m unittest discoversobretests/y luegoscripts/tests/— 229 tests, unos 8 segundos en local
CI externa: SonarCloud + Codacy + CodeFactor
El workflow .github/workflows/sonarcloud.yml (project key jls42_ai-powered-markdown-translator) se ejecuta en cada PR. 11 badges de SonarCloud mostrados en el README: Quality Gate, Security/Reliability/Maintainability Rating, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC.
¿Por qué la redundancia Codacy + SonarCloud + CodeFactor? Porque cada uno ve cosas distintas. Codacy reportó duplicaciones que SonarCloud no había señalado. SonarCloud reportó señales de mala calidad (los famosos code smells) que Codacy dejaba pasar. CodeFactor reportó problemas de complejidad que los otros dos ignoraban. Ninguno habría bastado por sí solo. El costo marginal de una plataforma adicional es nulo (badge gratis, integración de 5 minutos), así que se multiplican los ángulos.
Tests: unittest stdlib (no pytest)
229 tests, 0 regresiones durante los 6 meses de la PR, ~98 % de cobertura sobre el nuevo código v1.9.
Detalle típico:
test_silent_failure.py: 97 tests orientados a la doble validacióntest_orchestration.py: 79 tests sobre el pipeline orquestadortest_translation_note_position.py: 38 tests sobre la matriz posición × formatotest_audit_verdict.py: 15 tests sobre el wrapper pip-audit (enscripts/tests/)
Nota de honestidad: la cobertura ~98 % se refiere al nuevo código v1.9 — no al conjunto histórico de translate.py, que todavía contiene algunas funciones heredadas poco cubiertas por la nueva batería de tests. Lo menciono explícitamente porque anunciar «98 % de cobertura» sobre un proyecto entero sería engañoso.
Elección discutible pero asumida: ejecutor de tests unittest (stdlib), no pytest. El prefijo test_ es por costumbre, pero es unittest el que ejecuta. ¿Por qué? En un proyecto en vibe coding, cada dependencia añadida = cada dependencia que la IA puede usar mal. La simplicidad es un objetivo. unittest está en la biblioteca estándar de Python, cero instalación, cero plugin.
Tests prácticos: multi-repo + uso interno del producto (dogfooding) + verificación del renderizado visual
Los 229 tests unittest no bastan. Añado tres capas de test práctico:
1. Multi-repo — probar el script sobre varios repos públicos con README en distintos formatos. Eso revela casos límite que las fixtures no cubren — un README con 8 niveles de heading, otro con shortcodes heredados, un tercero con código incrustado exótico. Fue en esta fase donde se descubrió el incidente silent-failure de la Novedad 1.
2. Dogfooding en el blog — jls42.org lo traduce el propio script. Cada artículo publicado es un test en vivo en producción. Si un caso límite pasa los tests unitarios, saldrá aquí, en la página que está leyendo. Es la prueba definitiva — lo que está en línea es lo que el proyecto ha producido.
3. Test del renderizado visual — compruebo que las traducciones renderizadas se muestren correctamente, ya sea en el navegador (página web final) o directamente en VSCode mediante un plugin de vista previa Markdown. La idea: no conformarse con un Markdown sintácticamente válido, sino ver el renderizado real. Los renderizados visuales sacan a la luz bugs de apariencia (tablas rotas, code blocks mal formados, frontmatter mal interpretado) que los tests de texto no ven.
Las IAs también participan en estas pruebas. /pr-review-toolkit ejecuta el código en entorno de test, y el uso en pair-IA incluye sistemáticamente pases de validación visual («comprueba que la traducción alemana de la página X se muestra bien»).
📄 Extracto .pre-commit-config.yaml (hooks pre-commit principales)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Extracto scripts/check-security-sast.sh
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Extracto .github/workflows/sonarcloud.yml
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Guardarraíl 2: la revisión asistida por IA + el flujo multimodelo
Precisión de vocabulario: cuando hablo de Claude Opus en esta sección, hablo del modelo que uso para desarrollar la v1.9 — no del modelo que AI-Powered Markdown Translator utiliza para traducir. El proyecto en sí soporta 4 providers (OpenAI, Mistral AI, Claude, Gemini) y cualquier modelo (Sonnet, Haiku, Mistral Large, Gemini 3 Pro, etc.). En desarrollo, lo bloqueo en Opus. En uso en ejecución, el proyecto sigue siendo agnóstico.
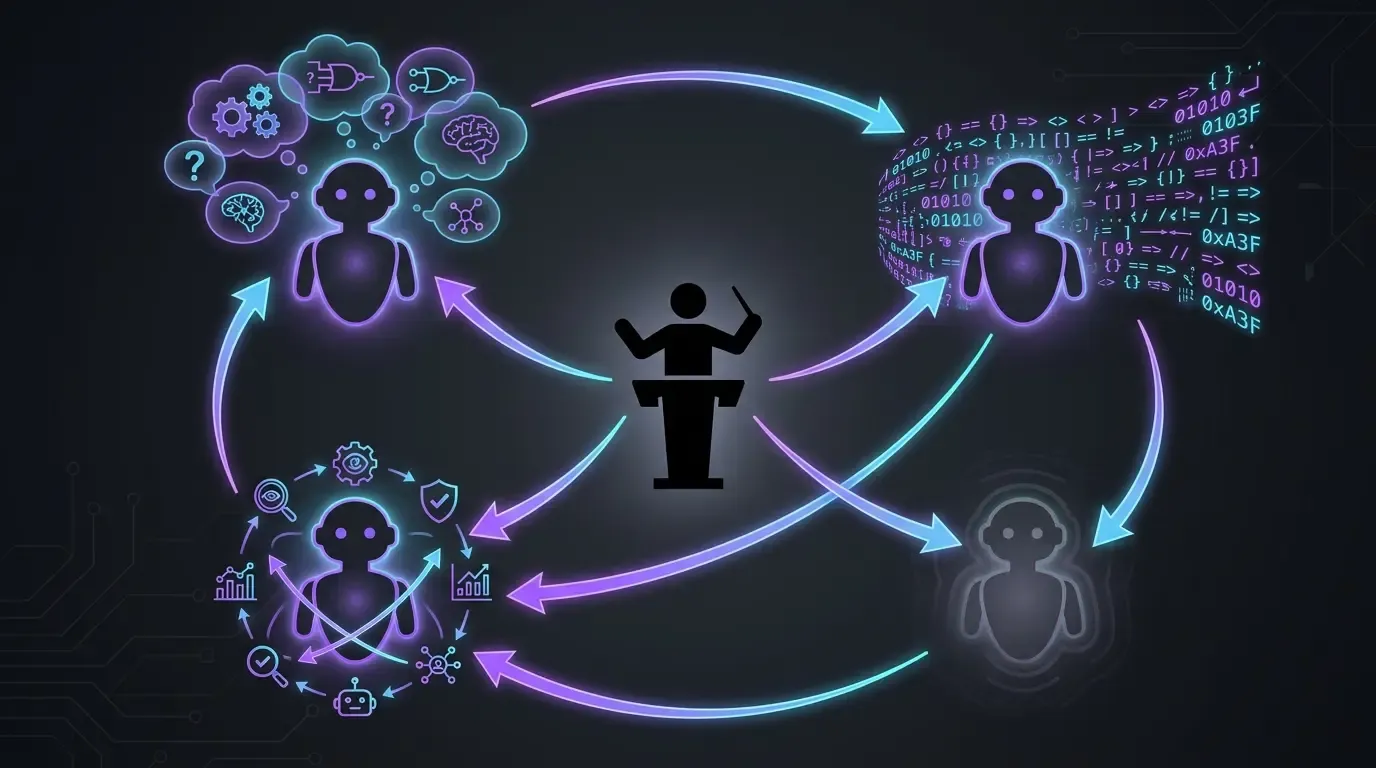
El flujo de trabajo real: 4 modelos, 4 roles (para desarrollar)
- Claude Code en Opus, exclusivamente (anthropic) : ejecución principal. Lee el contexto, escribe el código, aplica las correcciones. Nada de Sonnet, nada de Haiku, nada de fast mode. En este proyecto, quiero el modelo de gama alta cada vez — la idea es simple: nos aseguramos de tener lo mejor para apuntar al mejor resultado posible.
- OpenAI Codex como solución de repli (fallback) : utilizado en dos casos concretos :
- Cuando Opus se atasca en un tema (raro, pero existe — por ejemplo, en correcciones pedidas por agentes externos tipo Codacy o SonarCloud, Claude a veces no converge y yo paso el tema a Codex para desbloquear)
- Cuando la ventana de uso de Anthropic está saturada. Codex permite no perder el impulso mientras esperamos el reinicio del cupo.
- GPT-5.5 reasoning extra-high (
xhigh) : pone a prueba los planes antes de la ejecución. Antes de dejar que Claude Code ataque un tema, paso el plan a GPT-5.5 en reasoning extra-high. Hace las preguntas adecuadas, saca a la luz los puntos ciegos. Eso evita ir en una mala dirección que habría que corregir más tarde. /pr-review-toolkit:review-pr(skill plugin Claude Code) : revisión antes del merge con agentes especializados (seguridad, calidad, tests, comentarios, diseño de tipos). El skill se ejecuta sobre la PR antes de que haga el merge — es la última red de seguridad de IA antes de que el código entre enmain.
Ninguno de estos modelos basta por sí solo. Cada uno cumple un papel distinto — el ejecutor de gama alta, el suplente de capacidad, el retador de planes, el revisor (reviewer) multiángulo.
/pr-review-toolkit : lo que no habría visto
Todo. Yo no miro el código. El skill lo saca todo — bugs ocultos, problemas de seguridad, incoherencias en los tests, tests que pasan pero no prueban nada.
En la PR #2 (75 commits, 9 837 additions, 1 982 suppressions, 58 archivos), un humano solo habría saltado el 80 % de la PR por fatiga. El skill no se salta nada. Lee cada diff, cada test, cada comentario. Y sobre todo, cuestiona — rechaza los patrones que identifica como malos, y propone alternativas.
El humano como director de orquesta, no como músico
Mi papel cubre toda la cadena — salvo la escritura del código. Me reparto las funciones de product manager (pensar en las features, priorizar, arbitrar), QA (probar en casos reales, validar visualmente el resultado), tech lead (cuestionar los planes con GPT-5.5 reasoning extra-high), cliente final (juzgar el resultado en mi propia experiencia de uso cotidiana en el blog). La única función que no asumo es la de programar. El resto, soy yo.
Me he convertido en productor, no en músico.
Al servicio del blog: se traduce a sí mismo (casi 1 800 traducciones)
AI-Powered Markdown Translator genera su propio README en 14 idiomas, y es él quien produce todas las versiones en otros idiomas de los contenidos de jls42.org. En concreto: casi 1 800 versiones traducidas alimentan el blog (25 artículos + 4 proyectos + 98 novedades IA × 14 idiomas, sin contar las fuentes FR — es decir, 1 778 versiones en el momento en que escribo esto). Toda página que recorres aquí en un idioma distinto del francés ha pasado por este proyecto.
Es uso interno del producto (dogfooding) llevado al extremo — y eso pone a prueba la traducción en el artículo que habla de la traducción. Si lo que lees en ar, hi o ko es coherente, es que la red de seguridad de la Novedad 1 (validación posterior a la traducción) aguanta; si la nota de traducción se muestra correctamente en la parte superior, es que la Novedad 2 (nota multiposición) funciona; si las citas EN se conservan en las versiones lingüísticas, es que la Novedad 3 (modo --news) también funciona.
Balance: pair-IA rigurosa, no pair-IA chapucera
El desarrollo por intuición tiene mala prensa por buenas razones. Precisamente contra ellas trabajo yo. Cuatro lecciones concretas salen de esta v1.9:
-
Los fallos silenciosos son el enemigo número uno. La IA produce código que parece correcto y pasa por los tests unitarios. Validación del lado del cliente de forma sistemática. Y usar otra IA para revisar la producción real, no solo el código.
-
Hooks pre-commit < 10 s o se esquivan; los pre-push pueden tardar 30 s+. La IA añade encantada herramientas sin considerar su coste. Hay que encuadrarlo manualmente, ya sea en el plan o a posteriori — lo importante es que al final los hooks queden bien ajustados y se usen de verdad en el día a día.
-
Cobertura sin una aserción fuerte = teatro. La IA puede generar 200 tests que pasan y que no prueban nada. unittest + aserciones precisas > pytest con mocks a mansalva. Verificar el valor devuelto, no solo que el código no se haya caído.
-
La revisión (PR review) IA no es una opción. Cuando el autor humano no ha revisado, el revisor IA no es un adorno — es el ojo delegado.
Hacer bien el vibe coding también es aceptar que no leemos el código y delegar la lectura crítica a otras IAs que sí la hacen de verdad.
Lo que este proyecto revela
Esta v1.9 ilustra varios aspectos de mi forma de trabajar:
- El papel humano cubre toda la cadena salvo el código : producto (pensar en las features, priorizar), QA (probar en casos reales, validar visualmente), tech lead (cuestionar los planes con un LLM en reasoning extra-high), cliente final (juzgar sobre el uso real). La única función que no asumo es programar.
- Duplicar las redes, no suprimirlas : menos revisión humana = más validación con herramientas. Compromiso asumido, no falta de rigor. Si elimino la revisión, tengo que duplicar las redes, no confiar ciegamente en la IA.
- La IA para descubrir los bugs de la IA : el fallo silencioso lo encontró Claude durante las pruebas prácticas multi-repo. Delegación completa: también se puede delegar la revisión crítica.
- El pair-IA como multiplicador en tiempo personal : llevo este proyecto en mis noches y fines de semana. Sin pair-IA, claramente no iría tan lejos ni tan rápido. Con ella, puedo mantener un proyecto open source a nivel industrial al margen de mis otras obligaciones. Eso es lo que hace posible el vibe coding — no reemplazar al desarrollador, sino permitirle hacer lo que no podría hacer solo.
- Iterar en lugar de rehacerlo todo : 9 versiones, refactorización incremental (1 función → 7 helpers), retrocompatibilidad preservada. El pair-IA ayuda a iterar rápido sin reescribirlo todo.
Recursos
- AI-Powered Markdown Translator en GitHub
- Lanzamiento v1.9
- PR #2 — 75 commits, migración + calidad
- CHANGELOG completo
- Página del proyecto en este blog
- Artículo 2024 — v1.5 (estilo notas de lanzamiento) — para comparar el tono
- Deep Dive del diagrama AWS — otro artículo de la serie
Si quieres probar AI-Powered Markdown Translator con tus propios Markdown — README de código abierto, artículos de blog, documentación técnica —, el código está en GitHub. Instalación en unos minutos, 4 proveedores compatibles, modo --eco para reducir el coste, modo --news para conservar las citas fuente, y ahora además una stack de calidad v1.9 que puedes reutilizar como plantilla para tus propios proyectos en pair-IA.
Si desarrollas tus proyectos personales haciendo vibe coding, no vayas a lo más simple en cuanto a calidad. La fiabilidad es el precio de la rapidez — asume ambas cosas a la vez.