ai-powered-markdown-translatorArtigo traduzido do fr para o pt com gpt-5.4-mini.
AI-Powered Markdown Translator é um projeto open-source que mantenho desde 2024: um script Python que traduz qualquer arquivo Markdown para 14 idiomas via 4 provedores de IA (OpenAI, Mistral AI, Claude, Gemini). Ele alimenta este blog a cada publicação — toda página que você lê aqui em um idioma diferente do francês passou por ele — e quase 1 800 versões traduzidas rodam graças a ele em produção.
Em 8 de maio de 2026, publiquei a v1.9, que reúne 75 commits e marca a maior atualização desde a v1.5 de 2024. Três novidades de produto:
- Validação pós-tradução (anti-falha silenciosa)
- Nota de tradução multi-posicionamento (no topo, no rodapé ou em ambos)
- Modo
--newspara preservar as citações-fonte em EN
Mas essa v1.9 tem uma particularidade que quero contar aqui: todo o código foi escrito em pair-IA. Nem uma linha digitada à mão. Então, além das 3 novidades, o artigo aborda o “como”: quais guardrails colocar em prática para buscar código limpo e seguro quando você não revisa você mesmo o que a IA produz?
O contexto: um projeto usado todos os dias, pouco mantido do lado do código
De setembro de 2024 a maio de 2026: uso contínuo, manutenção em ondas
Eu havia publicado um artigo que detalhava o código-fonte da v1.5 em 2024. Na época, eu publicava o script diretamente no artigo. Hoje, o ângulo mudou: o que importa não é mais tanto o código que eu escrevo, e sim o fluxo de trabalho que o produz.
Entre a v1.5 publicada em setembro de 2024 e janeiro de 2026, o projeto continuou rodando — ele traduz cada novo conteúdo deste blog — mas o código público quase não se mexeu. Um único commit foi enviado em 2025. Durante todo esse tempo, eu fui evoluindo o código localmente para minhas necessidades pessoais — principalmente os modelos, que eu substituía conforme iam sendo lançados — mas essas evoluções ficavam na minha máquina. A versão pública no GitLab continuava apontando para os valores padrão da v1.5.
No início de 2026, fiz um primeiro esforço de atualização: três releases em dois meses (v1.6 e v1.7 em dois dias no começo de janeiro, v1.8 em março) que atualizaram o projeto do lado funcional — modelos de 2026, suporte a Gemini, modo --eco, arquivo único, modo --news para as citações-fonte. Mas ainda sem CI, sem testes automatizados, sem gates de qualidade — o que me colocava um problema real para ir mais longe com um agente de IA que codifica no meu lugar.
O ritmo de um projeto no tempo livre
Por que esse descompasso? Porque eu conduzo esse projeto no meu tempo livre. Tenho família, uma vida fora da tela, então a evolução só avança em ondas quando encontro as noites e os fins de semana. Sou apaixonado pelo tema, passo mesmo bastante tempo nesses assuntos — testo muito, guio os agentes, valido os resultados — mas o ritmo não é o de um projeto profissional.
O pair-IA muda justamente isso. Ele me permite avançar entre duas limitações — a paixão e o equilíbrio da vida fora da tela. Sem pair-IA, eu claramente não iria tão longe nem tão rápido. Com ele, consigo manter um projeto open-source em nível industrial sem dedicar minha vida a isso.
O objetivo inicial: qualidade + migração GitLab → GitHub
Em meados de abril de 2026, quis finalmente cuidar disso de forma séria. Dois objetivos simples:
- Adicionar uma camada de qualidade (análise estática, testes, CI)
- Migrar o repo do GitLab para o GitHub
Nada além disso. Só que, com um agente de código em pair-IA, a gente nunca escreve exatamente o que tinha previsto. A PR acabou em 75 commits, 9 837 additions, 1 982 suppressions, 58 arquivos.
| Versão | Data | Principal contribuição |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, depois Mistral, depois Claude |
| 1.5 | set. 2024 | Refatoração dos clientes, modelos 2024 (gpt-4o, claude-3.5-sonnet) |
| 1.6 | jan. 2026 | Modelos 2026 (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, modo --eco, arquivo único (--file) |
| 1.7 | jan. 2026 | --keep_filename, .env, código inline preservado |
| 1.8 | mar. 2026 | Modelos GPT-5.4 por padrão, modo --news com placeholders de citações |
| 1.9 | mai. 2026 | Validação pós-tradução, nota multi-posicionamento, stack de qualidade 14 hooks + 229 testes + revisão IA |
O efeito bola de neve
Cada ferramenta de qualidade adicionada revelava problemas. O Codacy apontou duplicações. O SonarCloud levantou code smells (sinais de que o código vai envelhecer mal: funções longas demais, parâmetros não usados, estruturas complicadas). /pr-review-toolkit apontou bugs ocultos. A cada sinal, o agente corrigia, às vezes melhorando também coisas adjacentes.
O escopo cresceu organicamente. Era exatamente o que eu queria — modernizar o projeto —, mas a dosagem do esforço era ditada pelas ferramentas, não por mim. Para um projeto em vibe coding, esse é um ponto-chave: as ferramentas de qualidade orientam o trabalho tanto quanto o verificam.
Novidade 1: a validação pós-tradução (anti-falha silenciosa)
O incidente: foi a IA que encontrou o bug, durante os testes
Ao testar a PR em READMEs de diferentes repositórios públicos — um caso que nenhuma fixture cobria —, a IA apontou o que eu tinha perdido: em certos idiomas (notadamente o hindi, código ISO hi), trechos continuavam no idioma-fonte no meio da tradução. A API tinha retornado 200, o script tinha gravado o arquivo, mas o conteúdo estava parcialmente traduzido. E isso passava pela bateria de testes unitários existente — que não cobria esse caso real multilíngue.
Esse é exatamente o tipo de bug que o vibe coding pode produzir e que ninguém vê. O código parece lógico, as fixtures de teste não cobrem o caso, o humano não revisa o resultado. Só que, ao testar o script em casos reais (multi-repo), a própria IA fez o que as fixtures não faziam.
O que levo disso: testes práticos multi-repo encontram o que os testes unitários não pegam. E a IA também pode servir para descobrir bugs de agentes de IA anteriores — desde que você a coloque diante de casos reais e variados.
Foi nesse momento que percebi que era preciso adicionar uma validação pós-tradução de verdade. É essa primeira novidade que detalho agora: a camada dupla de validação.
A camada dupla de validação
| Etapa | Ação | Se KO |
|---|---|---|
| 1️⃣ | Chamada de API do provedor | Exceção de rede → ❌ failure |
| 2️⃣ | Lista de permissões por provedor para finish_reason (ou stop_reason no Claude) | Fora da whitelist → ❌ failure |
| 3️⃣ | Anti-vazamento: nenhuma janela-fonte ≥ 120 chars verbatim na saída | Janela-fonte encontrada → ❌ failure |
| 4️⃣ | langdetect.detect_langs (probabilidades fonte vs target) | Fonte > 0,80 E target < 0,20 → ❌ failure |
| 5️⃣ | Empty-content + ratio saída/fonte (se fonte ≥ 500 chars) | Vazio ou saída < max(50, source/20) → ❌ failure |
| ✅ | SUCESSO | exit code 0 |
Camada 1 (determinística) — Primeiro filtro: verificar o status devolvido pela API. Cada provedor expõe um campo finish_reason (ou stop_reason no Claude) que indica por que o LLM parou de gerar. O script mantém uma whitelist por provedor dos statuses aceitáveis — a nomenclatura varia (stop no OpenAI/Mistral, STOP ou FINISH_REASON_STOP no Gemini, end_turn ou stop_sequence no Claude). O código também tolera None por segurança, quando o SDK não devolve esse campo. Qualquer outro status — por exemplo length, max_tokens ou MAX_TOKENS conforme o provedor, que sinalizam uma resposta interrompida pelo limite de tokens — dispara um RuntimeError imediato, sem tentativa de recuperação.
Segundo filtro determinístico, mais sutil: verificar que nenhum trecho do texto-fonte apareça verbatim na saída traduzida. Na prática, extraímos janelas de 120 caracteres ou mais do texto-fonte; se uma delas for encontrada exatamente assim na saída, é porque não foi traduzida — failure. Foi exatamente esse check que resgatou o caso do hindi: o LLM tinha respondido stop (ou seja, fim “natural” do lado da API), mas parágrafos em francês tinham permanecido intactos na saída — invisíveis ao filtro finish_reason, detectados pelo filtro anti-vazamento verbatim.
Camada 2 (probabilística) — langdetect.detect_langs analisa o idioma da saída e retorna uma distribuição de probabilidades sobre várias línguas candidatas. Extraímos a probabilidade do idioma-fonte e a do idioma-alvo, e então rejeitamos somente se a prob fonte ultrapassar 0,80 e a prob target cair abaixo de 0,20 — um limiar deliberadamente conservador para não gerar falsos positivos em code-switching técnico (palavras em inglês legítimas numa tradução em francês, por exemplo). Essa camada faz short-circuit para idiomas com scripts não latinos (hindi hi, árabe ar, chinês zh, japonês ja, coreano ko), onde um sinal de script suficiente já valida a saída. E ela só roda se a saída limpa tiver pelo menos 100 caracteres, para evitar falsos positivos em texto curto demais.
Os guardrails quantitativos
Acima das duas camadas, dois controles mais prosaicos, mas necessários:
- Proteção contra conteúdo vazio: se o provedor devolve uma saída vazia enquanto
finish_reasonéstop, rejeitamos imediatamente (caso contrário, escreveríamos um arquivo vazio marcado como sucesso) - Relação de sanidade: somente se a fonte tiver pelo menos 500 caracteres, verificamos que a saída não ficou suspeitamente curta (tipicamente <
max(50, source/20)). Isso é um detector de truncamento invisível, não uma regra geral de comprimento
No Claude especificamente, max_tokens passou de 4 096 para 32 768 na v1.9 (a alteração foi feita no código pelo Claude depois que eu constatei o sintoma e pedi para investigar). A razão documentada no CHANGELOG: evitar truncamento latente em segmentos de 16 k caracteres, com margem adicional para idiomas em script não latino (FR → JA, ZH, KO, AR, HI) que consomem mais tokens na saída do que um script latino equivalente.
Retornos por status explícito
O pipeline de arquivo (translate_markdown_file()) agora devolve um status explícito — success, failure ou skipped. O CLI agrega esses statuses e termina com um código de saída não nulo assim que pelo menos um arquivo falha — o que torna a falha aproveitável por um script chamador ou pela nova CI adicionada na v1.9. Antes desta v1.9, vários erros eram apenas impressos ou passavam como uma tradução bem-sucedida: o processo podia terminar em 0 enquanto o arquivo estava ausente, incompleto ou mal validado. O status skipped passa a ser, ele próprio, um sinal legível (“ignorado de propósito”), distinto de success (“tradução gravada corretamente”).
📄 Trecho Python: validação dupla pós-tradução (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNovidade 2: a nota de tradução multi-posicionamento
A necessidade: uma nota discreta, mas informativa
Quando o AI-Powered Markdown Translator escreve uma tradução, ele adiciona uma nota de tradução que indica o modelo usado e a data. Antes da v1.9, essa nota era sempre colada no fim do arquivo, em um formato legado (legacy) com delimitadores visíveis.
O formato colado no fim trazia dois problemas para os meus próprios usos. Primeiro, o leitor só era informado no final de que o conteúdo tinha sido traduzido por IA — é melhor avisar logo no começo, isso cria uma expectativa correta sobre o conteúdo. Depois, a nota no rodapé não destacava o projeto de tradução que torna tudo isso possível: você lê o artigo, e a origem do fluxo multilíngue passa despercebida. Eu queria, portanto, poder mover a nota para o topo sem perder a rastreabilidade — sem quebrar os usos existentes. A v1.9 adiciona dois flags que não quebram nada:
--note_position {top,bottom,both}: topo, rodapé ou ambos--note_format {legacy,marker}: formato legado ou formato marcador (marker format)
Padrões retrocompatíveis: legacy + bottom. Nenhuma cadeia de tradução existente muda de comportamento por padrão — ativamos explicitamente os novos flags sob demanda.
O formato marcador: um cartão incorporado GitHub limpo
O formato marcador explora um detalhe sutil do Markdown do GitHub: as link reference definitions não usadas ficam invisíveis na renderização. Podemos, então, codificar metadados (modelo, data, origem) em um comentário-marker posicionado no topo do arquivo — invisível no navegador, mas preservado como está na cópia bruta.
Além disso, o GitHub gera um cartão incorporado (embed card) quando compartilhamos um link para o arquivo traduzido, e esse cartão exibe corretamente o título do documento sem poluição textual.
Exemplo de Markdown bruto com o formato marcador na posição top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...A olho nu, o leitor vê apenas o título seguido do conteúdo. O marcador não polui nem a renderização HTML nem o cartão embed.
A inserção consciente do frontmatter (frontmatter-aware)
Detalhe técnico, mas crucial: inserir uma nota em top não significa « inserir na linha 1 do arquivo ». Se o arquivo tem um frontmatter YAML (o que é o caso deste blog), é preciso inserir depois do frontmatter — caso contrário, a nota quebra o YAML.
Eu passei o requisito ao Claude (« insere a nota depois do frontmatter, não antes — caso contrário você quebra o YAML »), e ele produziu um helper _split_frontmatter que detecta as fences --- de abertura/fechamento. Se o arquivo tem uma fence YAML não fechada (caso malformado), o helper lança uma RuntimeError em vez de produzir silenciosamente um arquivo quebrado. A passagem de uma função monolítica para 7 helpers puros (separados e testáveis) é típica do que um pair-IA bem orientado consegue fazer rápido. Meu papel aqui: guia do requisito, testador, cliente final que valida o resultado. Não programar. Neste projeto, eu visto vários chapéus — exceto o de escrever o código, que cabe ao Claude.
| Posição | Formato | Caso de uso típico |
|---|---|---|
top | marker | Artigos de blog (nota discreta, card embed limpo) |
top | legacy | Doc interna em que a rastreabilidade visível importa |
bottom | marker | README open-source (coerente com o footer) |
bottom | legacy | Padrões — compatível com versões anteriores |
both | marker | Artigos longos em que topo + rodapé tranquilizam |
both | legacy | Casos legacy com exigência de dupla rastreabilidade |
📄 Trecho Python : helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")Novidade 3 : o modo --news para preservar as citações-fonte EN
O problema : traduzir sem quebrar as citações
Quando escrevo artigos ia-actualites para este blog (notícias diárias/semanais de IA multi-source), cito regularmente tweets, posts de blog, anúncios de versão em inglês — muitas vezes vários por artigo. Se a tradução mexe nas citações, elas viram falsas.
Uma citação traduzida é uma citação alterada. Em todas as versões linguísticas (EN, DE, JA etc.), queremos manter o inglês original das citações — é uma exigência de fidelidade às fontes — acompanhado da bandeira do idioma-alvo e de uma tradução em itálico para o conforto de leitura.
A solução : placeholders <NEWSQUOTE id="N"/>
| Etapa | Ação |
|---|---|
| 1️⃣ | Markdown fonte FR com citações EN na entrada |
| 2️⃣ | Pré-processamento : extração das citações EN, substituição por placeholders <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, etc. |
| 3️⃣ | Tradução via API (FR → target_lang) — as citações EN originais nunca são enviadas ao LLM, apenas os placeholders são (preservados exatamente como estão) |
| 4️⃣ | Pós-processamento : restauração dos placeholders com as citações EN originais intactas + inserção da bandeira do idioma-alvo |
| 5️⃣ | Validação pós-tradução : todos os placeholders foram restaurados ? |
| ✅ | Saída-alvo com citações EN preservadas |
| ❌ | Falha se o placeholder não for restaurado ou se a citação tiver sido alterada |
O modo --news se baseia nesse princípio : um pré-processamento extrai todas as citações EN, substitui por placeholders do tipo <NEWSQUOTE id="0"/>, traduz o resto e restaura os placeholders intactos.
O mapeamento LANG_FLAGS adapta a bandeira ao target_lang (15 idiomas cobertos) : 🇬🇧 para o inglês, 🇩🇪 para o alemão, 🇪🇸 para o espanhol, 🇮🇹 para o italiano, 🇵🇹 para o português, 🇳🇱 para o neerlandês, 🇵🇱 para o polonês, 🇸🇪 para o sueco, 🇷🇴 para o romeno, 🇸🇦 para o árabe, 🇮🇳 para o hindi, 🇯🇵 para o japonês, 🇰🇷 para o coreano, 🇨🇳 para o chinês, 🇫🇷 para o francês.
A validação pós-tradução verifica que todos os placeholders foram restaurados intactos. O erro não é um « vazamento EN » — o EN é intencional — mas um placeholder não restaurado ou uma citação alterada.
Casos de uso atuais e perspectivas
Hoje, uso --news exclusivamente nos artigos ia-actualites do blog. No futuro, isso poderia se estender a qualquer artigo que misture prosa em francês e citações-fonte em EN — entrevistas, relatos de experiência que citam artigos de pesquisa em inglês, transcrições de apresentações de conferência.
Sem reler o código : por que é preciso dobrar as proteções
« Eu não leio o código. »
Eu não releio nada. Às vezes dou uma olhada rápida num diff — é raro, e só quando o Claude não consegue se virar sozinho em algum ponto. Aqui está o fluxo que uso no dia a dia e que produziu a v1.9 : Claude Code (Opus, exclusivamente) escreve o código. Codex assume quando o Opus trava ou quando a janela de uso fica saturada. GPT-5.5 em reasoning extra-high desafia os planos antes da execução. /pr-review-toolkit:review-pr revisa a PR antes de cada merge. Meu papel termina em validar as direções e definir as proteções.
Esse modo de desenvolvimento — desenvolvimento integral ao feeling (vibe coding) — não é falta de rigor. É um compromisso explícito : menos revisão humana, mais validação instrumentada. As 3 novidades v1.9 que acabei de apresentar foram todas produzidas nesse fluxo. E é precisamente porque não se relê o código que é preciso dobrar as proteções técnicas — não suprimi-las.
Aqui estão as duas proteções implementadas para tornar esse modo de desenvolvimento viável em produção : uma stack de qualidade automatizada (Proteção 1) e uma revisão assistida por IA em fluxo multimodelo (Proteção 2).
Proteção 1 : a stack de qualidade automatizada (14 hooks + testes práticos)
Visão geral
| Rede | Ferramentas | Custo típico | Bloqueia se falhar |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hooks), detect-secrets, Lizard CCN | < 10 s | Sim |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Sim, exceto pip-audit em reporting initial |
| CI externa | SonarCloud, Codacy, CodeFactor | em paralelo | Não bloqueia localmente, badges PR |
Números v1.9 : 14 hooks, 229 testes unittest stdlib, ~98 % de cobertura no novo código v1.9, 11 badges SonarCloud, 3 plataformas externas.
Pre-commit : a rede rápida
| # | Ferramenta | Versão | Função |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Lint shell |
| 2 | ruff (lint) | 0.8.6 | Lint Python |
| 3 | ruff (format) | 0.8.6 | Formatação Python |
| 4 | prettier | 3.1.0 | Formatação Markdown / JSON / YAML |
| 5 | trailing-whitespace | 5.0.0 | Remoção de espaços em branco no fim da linha |
| 6 | end-of-file-fixer | 5.0.0 | Newline final obrigatória |
| 7 | check-yaml | 5.0.0 | Validação de sintaxe YAML |
| 8 | check-toml | 5.0.0 | Validação de sintaxe TOML |
| 9 | check-added-large-files | 5.0.0 | Bloqueia binários grandes adicionados por acidente |
| 10 | check-merge-conflict | 5.0.0 | Detecção dos marcadores de conflito Git |
| 11 | check-executables-have-shebangs | 5.0.0 | Verifica se os executáveis têm um shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Verifica se os scripts com shebang são executáveis |
| 13 | detect-secrets | 1.5.0 | Detecção de chaves de API e segredos |
| 14 | check-complexity (Lizard) | local | Teto de complexidade ciclomática no novo código |
Total medido : cerca de 2 a 3 segundos em todo o repositório (a quente, pre-commit run --all-files cronometrado em ~2,4 s). Em um commit médio que toca só alguns arquivos, é ainda mais rápido. A regra prática que aplico : acima de 10 s, os desenvolvedores contornam (o pair-IA também) — então é preciso manter essa rede rápida o tempo todo.
Pre-push : a rede pesada
- mypy em modo relaxado : sem strict total (o código histórico de translate.py não passaria), mas com uma verificação de progressão no novo código
- Opengrep SAST :
p/security-audit p/default p/python— cerca de 30 segundos para escanear injeções, eval, deserialização insegura - pip-audit encapsulado por
scripts/check-pip-audit.sh: captura a saída JSON, classifica no shell os erros de transporte (rede, PyPI fora do ar) para não confundir vulnerabilidade com indisponibilidade, e reporta as vulnerabilidades. Em modo reporting initial para a v1.9 (warn + exit 0) — a endurecer em modo bloqueante depois de uma PR de bump das dependências obsoletas. - unittest discovery :
python -m unittest discoveremtests/depoisscripts/tests/— 229 testes, cerca de 8 segundos localmente
CI externa : SonarCloud + Codacy + CodeFactor
O workflow .github/workflows/sonarcloud.yml (project key jls42_ai-powered-markdown-translator) roda em cada PR. 11 badges SonarCloud exibidos no README : Quality Gate, classificação de Segurança/Confiabilidade/Manutenibilidade, Cobertura, Vulnerabilidades, Bugs, Code Smells, Duplicações, Dívida técnica, LOC.
Por que a redundância Codacy + SonarCloud + CodeFactor ? Porque cada um vê coisas diferentes. O Codacy sinalizou duplicações que o SonarCloud não tinha apontado. O SonarCloud sinalizou indícios de baixa qualidade (os famosos code smells) que o Codacy deixava passar. O CodeFactor sinalizou problemas de complexidade que os dois outros ignoraram. Nenhum deles bastaria sozinho. O custo marginal de uma plataforma adicional é nulo (badge gratuito, integração de 5 minutos), então multiplicamos os pontos de vista.
Testes : unittest stdlib (não pytest)
229 testes, 0 regressão nos 6 meses da PR, ~98 % de cobertura no novo código v1.9.
Detalhe típico :
test_silent_failure.py: 97 testes focados na dupla validaçãotest_orchestration.py: 79 testes no pipeline orquestradortest_translation_note_position.py: 38 testes na matriz posição × formatotest_audit_verdict.py: 15 testes no wrapper pip-audit (emscripts/tests/)
Nota de honestidade : a cobertura de ~98 % diz respeito ao novo código v1.9 — não ao conjunto histórico de translate.py, que ainda contém algumas funções herdadas pouco cobertas pela nova bateria de testes. Eu menciono isso explicitamente porque anunciar « 98 % de cobertura » em um projeto inteiro seria enganoso.
Escolha discutível, mas assumida : executor de testes unittest (stdlib), não pytest. O prefixo test_ é por hábito, mas é unittest que executa. Por quê ? Em um projeto em vibe coding, cada dependência adicionada = cada dependência que a IA pode usar mal. Simplicidade é um objetivo. unittest faz parte da biblioteca padrão do Python, zero instalação, zero plugin.
Testes práticos : multi-repo + uso interno do produto (dogfooding) + verificação da renderização visual
Os 229 testes unittest não bastam. Eu adiciono três camadas de teste prático :
1. Multi-repo — testar o script em vários repositórios públicos com READMEs em formatos diferentes. Isso revela casos-limite que os fixtures não cobrem — um README com 8 níveis de heading, outro com shortcodes herdados, um terceiro com código embutido exótico. Foi nessa fase que o incidente de silent-failure da Novidade 1 foi descoberto.
2. Dogfooding no blog — jls42.org é traduzido pelo próprio script. Cada artigo publicado é um teste ao vivo em produção. Se um caso-limite passar pelos testes unitários, ele aparecerá aqui, na página que você está lendo. Esse é o teste supremo — o que está on-line é o que o projeto produziu.
3. Teste de renderização visual — verifico se as traduções renderizadas aparecem corretamente, seja no navegador (página web final), seja diretamente no VSCode via um plugin de pré-visualização Markdown. A ideia : não se contentar com um Markdown sintaticamente válido, mas ver a renderização real. As renderizações visuais revelam bugs de aparência (tabelas quebradas, code blocks malformados, frontmatter interpretado errado) que os testes de texto não enxergam.
As IAs também participam desses testes. /pr-review-toolkit executa o código em ambiente de teste, e o uso em pair-IA inclui sistematicamente passagens de validação visual (« verifique se a tradução alemã da página X aparece corretamente »).
📄 Trecho .pre-commit-config.yaml (hooks principais de pre-commit)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Trecho scripts/check-security-sast.sh
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Trecho .github/workflows/sonarcloud.yml
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Proteção 2 : a revisão assistida por IA + o fluxo multimodelo
Precisão de vocabulário : quando falo de Claude Opus nesta seção, estou falando do modelo que uso para desenvolver a v1.9 — não do modelo que o AI-Powered Markdown Translator usa para traduzir. O projeto em si suporta 4 provedores (OpenAI, Mistral AI, Claude, Gemini) e qualquer modelo (Sonnet, Haiku, Mistral Large, Gemini 3 Pro, etc.). No desenvolvimento, eu me fixo em Opus. No uso em execução, o projeto continua agnóstico.
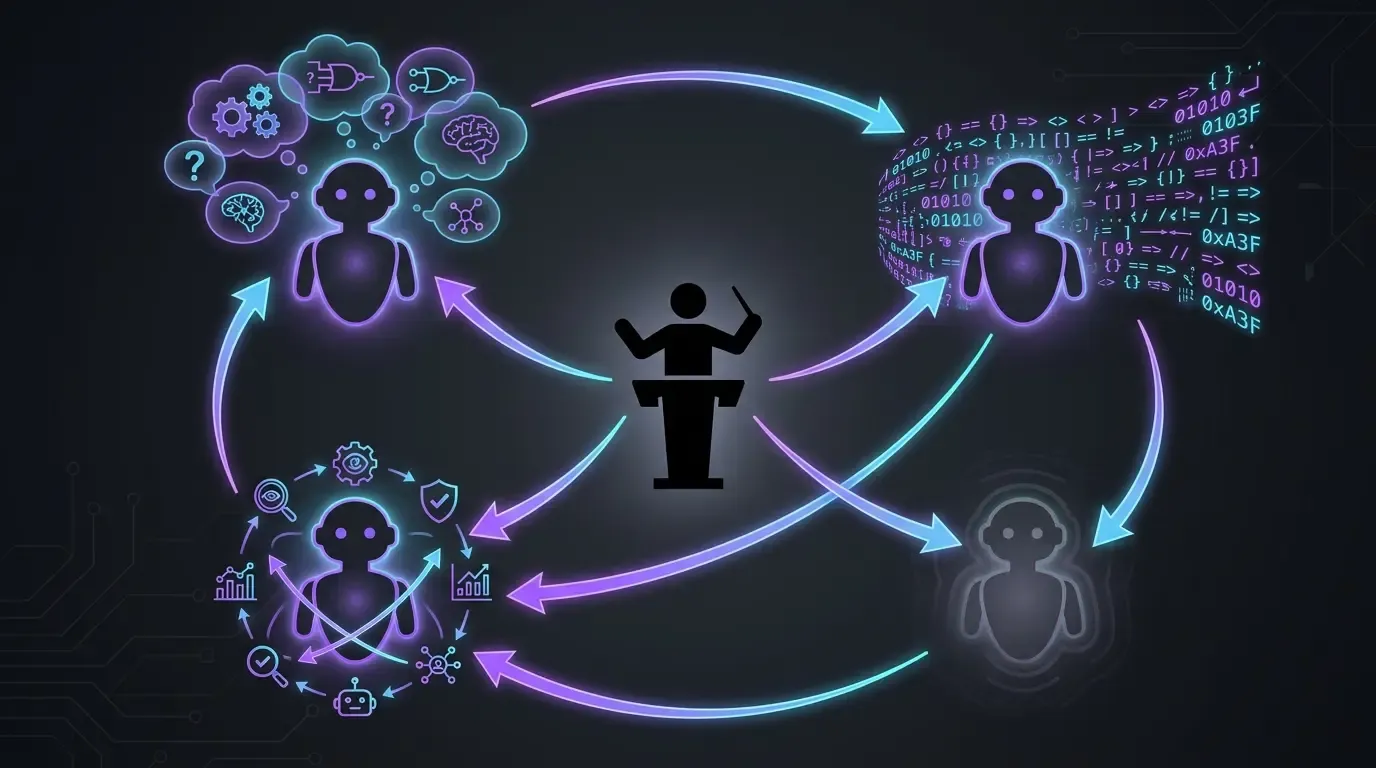
O fluxo de trabalho real: 4 modelos, 4 papéis (para desenvolver)
- Claude Code em Opus, exclusivamente (anthropic) : execução principal. Lê o contexto, escreve o código, aplica as correções. Nada de Sonnet, nada de Haiku, nada de fast mode. Neste projeto, eu quero o modelo de alto nível todas as vezes — a ideia é simples: garantimos o melhor para buscar o melhor resultado possível.
- OpenAI Codex como solução de fallback (fallback) : usado em dois casos específicos :
- Quando o Opus falha em um tema (raro, mas acontece — por exemplo, em correções pedidas por agentes externos como Codacy ou SonarCloud, o Claude às vezes não converge e eu transfiro o assunto para o Codex para destravar)
- Quando a janela de uso da Anthropic está saturada. O Codex permite não perder o ritmo enquanto espero o reset da quota.
- GPT-5.5 reasoning extra-high (
xhigh) : desafia os planos antes da execução. Antes de deixar o Claude Code atacar um tema, eu passo o plano para o GPT-5.5 em reasoning extra-high. Ele faz as perguntas certas, aponta os pontos cegos. Isso evita seguir na direção errada e depois ter que corrigir. /pr-review-toolkit:review-pr(skill plugin Claude Code) : revisão antes do merge com agentes especializados (segurança, qualidade, testes, comentários, design de tipos). O skill roda na PR antes de eu fazer merge — é a última rede de segurança de IA antes que o código entre emmain.
Nenhum desses modelos basta sozinho. Cada um desempenha um papel diferente — o executor de alto nível, o suplente de capacidade, o desafiador de planos, o revisor (reviewer) multilateral.
/pr-review-toolkit : o que eu não teria visto
Tudo. Eu não olho o código. O skill aponta tudo — bugs escondidos, problemas de segurança, incoerências nos testes, testes que passam mas não testam nada.
Na PR #2 (75 commits, 9 837 adições, 1 982 remoções, 58 arquivos), um humano sozinho teria pulado 80 % da PR por cansaço. O skill não pula nada. Ele lê cada diff, cada teste, cada comentário. E, acima de tudo, ele desafia — recusa os padrões que identifica como ruins e propõe alternativas.
O humano como maestro, não como músico
Meu papel cobre toda a cadeia — exceto a escrita do código. Eu faço os papéis de product manager (pensar nas features, priorizar, arbitrar), QA (testar em casos reais, validar visualmente o resultado), tech lead (desafiar os planos com GPT-5.5 reasoning extra-high), cliente final (julgar o resultado pela minha própria experiência de uso diário no blog). O único papel que eu não desempenho é o de codar. O resto sou eu.
Virei produtor, não músico.
Ao serviço do blog: ele se traduz sozinho (quase 1 800 traduções)
AI-Powered Markdown Translator gera o próprio README em 14 idiomas, e é ele que produz todas as versões em língua estrangeira dos conteúdos de jls42.org. Na prática: quase 1 800 versões traduzidas alimentam o blog (25 artigos + 4 projetos + 98 notícias de IA × 14 idiomas, fora as fontes em FR — ou seja, 1 778 versões no momento em que escrevo). Toda página que você navega aqui em um idioma diferente do francês passou por este projeto.
É dogfooding levado ao extremo — e isso coloca a tradução à prova no próprio artigo que fala de tradução. Se o que você lê em ar, hi ou ko está coerente, é porque a rede de segurança da Novidade 1 (validação pós-tradução) está funcionando; se a nota de tradução aparece corretamente no topo, é porque a Novidade 2 (nota multi-posicional) funciona; se as citações EN são preservadas nas versões linguísticas, é porque a Novidade 3 (modo --news) também funciona.
Balanço: pair-IA rigoroso, não pair-IA malfeito
Desenvolver no feeling tem má fama por bons motivos. É justamente contra eles que eu trabalho. Quatro lições concretas saem desta v1.9:
-
Falhas silenciosas são o inimigo número um. A IA produz código que parece OK e passa pelos testes unitários. Validação sistemática do lado do cliente. E usar outra IA para reler a produção real, não apenas o código.
-
Hooks pre-commit < 10 s, senão são contornados; pre-push podem levar 30 s+. A IA gosta de adicionar ferramentas sem considerar o custo. É preciso enquadrar manualmente, seja no plano, seja depois — o importante é que, no fim, os hooks estejam bem ajustados e realmente usados no dia a dia.
-
Cobertura sem asserção forte = teatro. A IA pode gerar 200 testes que passam e não testam nada. unittest + asserções precisas > pytest com mocks aos montes. Verifique o valor retornado, não apenas que o código não travou.
-
A revisão (PR review) por IA não é opcional. Quando o autor humano não releu, o revisor IA não é enfeite — é o olho delegado.
Fazer vibe coding direito também é aceitar que a gente não lê o código e delegar a leitura crítica a outras IAs que realmente o fazem.
O que este projeto revela
Esta v1.9 ilustra vários aspectos da minha forma de trabalhar:
- O papel humano cobre toda a cadeia, exceto o código : produto (pensar nas features, priorizar), QA (testar em casos reais, validar visualmente), tech lead (desafiar os planos com um LLM em reasoning extra-high), cliente final (julgar pelo uso real). O único papel que eu não desempenho é o de codar.
- Dobrar as redes de segurança, não removê-las : menos revisão humana = mais validação instrumentada. Compromisso assumido, não falta de rigor. Se eu removo a revisão, preciso dobrar as redes de segurança, não confiar cegamente na IA.
- IA para descobrir os bugs da IA : a falha silenciosa foi encontrada pelo Claude durante os testes práticos multi-repo. Delegação completa : também é possível delegar a revisão crítica.
- O pair-IA como multiplicador no tempo pessoal : levo este projeto nas noites e nos fins de semana. Sem pair-IA, claramente eu não iria tão longe nem tão rápido. Com ele, consigo manter um projeto open-source em nível industrial à margem das minhas outras obrigações. É isso que o vibe coding torna possível — não substituir o desenvolvedor, mas permitir que ele faça o que não conseguiria sozinho.
- Iterar em vez de refazer tudo : 9 versões, refatoração incremental (1 função → 7 helpers), retrocompatibilidade preservada. O pair-IA ajuda a iterar rápido sem reescrever tudo.
Recursos
- AI-Powered Markdown Translator no GitHub
- Release v1.9
- PR #2 — 75 commits, migração + qualidade
- CHANGELOG completo
- Página do projeto neste blog
- Artigo 2024 — v1.5 (estilo release notes) — para comparar o tom
- Deep Dive AWS Diagram — outro artigo da série
Se você quiser testar AI-Powered Markdown Translator nos seus próprios Markdown — README open-source, artigos de blog, documentação técnica —, o código está no GitHub. Instalação em poucos minutos, 4 providers suportados, modo --eco para reduzir o custo, modo --news para preservar as citações de origem e, agora, uma stack de qualidade v1.9 que você pode reutilizar como template para seus próprios projetos em pair-IA.
Se você desenvolve no feeling (vibe coding) seus projetos pessoais, não vá pelo caminho mais simples em termos de qualidade. Confiabilidade é o preço da velocidade — assuma os dois juntos.