ai-powered-markdown-translatorArticolo tradotto dal fr all’it con gpt-5.4-mini.
AI-Powered Markdown Translator è un progetto open-source che mantengo dal 2024: uno script Python che traduce qualsiasi file Markdown in 14 lingue tramite 4 provider IA (OpenAI, Mistral AI, Claude, Gemini). Alimenta questo blog a ogni pubblicazione — ogni pagina che leggi qui in una lingua diversa dal francese è passata da lui — e quasi 1.800 versioni tradotte girano in produzione grazie a lui.
L’8 maggio 2026 ho pubblicato la v1.9, che raggruppa 75 commit e segna il più grande aggiornamento dalla v1.5 del 2024. Tre novità di prodotto:
- Validazione post-traduzione (anti-fallimento silenzioso)
- Nota di traduzione multi-posizione (in alto, in basso o entrambe)
- Modalità
--newsper preservare le citazioni sorgente EN
Ma questa v1.9 ha una particolarità che voglio raccontare qui: tutto il codice è stato scritto in pair-IA. Nemmeno una riga digitata a mano. Quindi, oltre alle 3 novità, l’articolo affronta il «come»: quali guardrail si mettono in piedi per puntare a un codice pulito e sicuro quando non si rileggono da soli i risultati prodotti dall’IA?
Il contesto: un progetto usato ogni giorno, poco mantenuto lato codice
Da settembre 2024 a maggio 2026: uso continuo, manutenzione a singhiozzo
Avevo pubblicato un articolo che dettagliava il codice sorgente della v1.5 nel 2024. All’epoca pubblicavo lo script direttamente nell’articolo. Oggi l’angolazione è cambiata: ciò che conta non è più tanto il codice che scrivo, ma il flusso di lavoro che lo produce.
Tra la v1.5 pubblicata nel settembre 2024 e gennaio 2026, il progetto ha continuato a girare — traduce ogni nuovo contenuto di questo blog — ma il codice pubblico non si è quasi mosso. Nel 2025 è stato pushato un solo commit. Per tutto quel tempo facevo evolvere il codice in locale per le mie esigenze personali — soprattutto i modelli, che sostituivo man mano che uscivano — ma questi cambiamenti restavano sulla mia macchina. La versione pubblica su GitLab continuava a puntare ai valori predefiniti della v1.5.
All’inizio del 2026 ho fatto un primo sforzo di aggiornamento: tre release in due mesi (v1.6 e v1.7 a due giorni di distanza a inizio gennaio, v1.8 a marzo) che hanno rimesso il progetto in pari sul fronte funzionalità — modelli 2026, supporto Gemini, modalità --eco, file singolo, modalità --news per le citazioni sorgente. Ma sempre senza CI, senza test automatizzati, senza gate di qualità — e questo mi poneva un vero problema per spingermi oltre con un agente IA che scrive al posto mio.
Il ritmo di un progetto nel tempo libero
Perché questo scarto? Perché porto avanti questo progetto nel mio tempo libero. Ho una famiglia, una vita fuori dallo schermo, quindi l’evoluzione va avanti solo a singhiozzo quando trovo serate e weekend. Sono appassionato, ci passo comunque parecchio tempo — testo molto, guido gli agenti, valido i risultati — ma il ritmo non è quello di un progetto professionale.
Il pair-IA cambia proprio questo. Mi permette di avanzare tra due vincoli — la passione e il dosaggio della vita fuori dallo schermo. Senza pair-IA non andrei chiaramente così lontano né così veloce. Con esso posso mantenere un progetto open-source di livello industriale senza dedicarci la vita.
L’obiettivo iniziale: qualità + migrazione GitLab → GitHub
A metà aprile 2026 ho voluto finalmente occuparmene sul serio. Due obiettivi semplici:
- Aggiungere uno strato di qualità (analisi statica, test, CI)
- Migrare il repo da GitLab a GitHub
Nient’altro. Solo che, con un agente di codice in pair-IA, non si scrive mai ciò che era previsto. La PR è finita a 75 commit, 9.837 addition, 1.982 deletion, 58 file.
| Versione | Data | Apporto principale |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, poi Mistral, poi Claude |
| 1.5 | sett. 2024 | Refactor dei client, modelli 2024 (gpt-4o, claude-3.5-sonnet) |
| 1.6 | gen. 2026 | Modelli 2026 (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, modalità --eco, file singolo (--file) |
| 1.7 | gen. 2026 | --keep_filename, .env, codice inline preservato |
| 1.8 | mar. 2026 | Modelli GPT-5.4 predefiniti, modalità --news con placeholder delle citazioni |
| 1.9 | mag. 2026 | Validazione post-traduzione, nota multi-posizione, stack qualità 14 hook + 229 test + revisione IA |
L’effetto a catena
Ogni strumento di qualità aggiunto faceva emergere problemi. Codacy ha segnalato duplicazioni. SonarCloud ha sollevato code smell (segnali di codice destinato a invecchiare male: funzioni troppo lunghe, parametri non usati, strutture contorte). /pr-review-toolkit ha evidenziato bug nascosti. A ogni segnalazione, l’agente correggeva, a volte migliorando anche aspetti adiacenti.
Il perimetro è esploso in modo organico. È esattamente ciò che volevo — modernizzare il progetto — ma il dosaggio dello sforzo era dettato dagli strumenti, non da me. Per un progetto in vibe coding, questo è un punto chiave: gli strumenti di qualità orientano il lavoro tanto quanto lo verificano.
Novità 1: la validazione post-traduzione (anti-fallimento silenzioso)
L’incidente: è stata l’IA a trovare il bug, durante i test
Testando la PR su README di diversi repo pubblici — un caso che nessuna fixture copriva —, l’IA ha segnalato ciò che mi era sfuggito: su alcune lingue (in particolare l’hindi, codice ISO hi), alcuni passaggi rimanevano nella lingua sorgente in mezzo alla traduzione. L’API aveva restituito 200, lo script aveva scritto il file, ma il contenuto era tradotto solo a metà. E questo passava attraverso la batteria di test unitari esistente — che non copriva questo caso reale multilingue.
È esattamente il tipo di bug che il vibe coding può produrre e che nessuno vede. Il codice sembra logico, le fixture di test non coprono il caso, l’essere umano non rilegge il risultato. Solo che lì, testando lo script su casi reali (multi-repo), l’IA stessa ha fatto ciò che le fixture non facevano.
Da questo ho tratto una conclusione: i test pratici multi-repo trovano ciò che i test unitari si lasciano sfuggire. E l’IA può anche servire a scoprire i bug degli agenti IA precedenti — a patto di metterla davanti a casi reali e variati.
È a quel punto che ho capito che bisognava aggiungere una vera validazione post-traduzione. È questa la prima novità che dettaglio ora: il doppio strato di validazione.
Il doppio strato di validazione
| Fase | Azione | Se KO |
|---|---|---|
| 1️⃣ | Chiamata API del provider | Eccezione di rete → ❌ failure |
| 2️⃣ | Whitelist per provider di finish_reason (o stop_reason con Claude) | Fuori whitelist → ❌ failure |
| 3️⃣ | Anti-fuga: nessuna finestra sorgente ≥ 120 caratteri verbatim nell’output | Finestra sorgente ritrovata → ❌ failure |
| 4️⃣ | langdetect.detect_langs (probabilità sorgente vs target) | Sorgente > 0,80 E target < 0,20 → ❌ failure |
| 5️⃣ | Empty-content + rapporto output/sorgente (se la sorgente ≥ 500 caratteri) | Vuoto o output < max(50, source/20) → ❌ failure |
| ✅ | SUCCESS | exit code 0 |
Strato 1 (deterministico) — Primo filtro: verificare lo stato restituito dall’API. Ogni provider espone un campo finish_reason (o stop_reason con Claude) che indica perché il LLM ha smesso di generare. Lo script mantiene una whitelist per provider degli stati accettabili — la nomenclatura varia (stop su OpenAI/Mistral, STOP o FINISH_REASON_STOP su Gemini, end_turn o stop_sequence su Claude). Il codice tollera anche None per sicurezza, quando il SDK non restituisce questo campo. Qualsiasi altro stato — per esempio length, max_tokens o MAX_TOKENS a seconda del provider, che segnalano una risposta interrotta dal limite di token — attiva un RuntimeError immediato, senza tentativi di recupero.
Secondo filtro deterministico, più sottile: verificare che nessun passaggio del testo sorgente compaia verbatim nell’output tradotto. In pratica, si estraggono finestre di 120 caratteri o più dal testo sorgente; se una di queste viene ritrovata identica nell’output, significa che non è stata tradotta — failure. È proprio questo controllo che ha intercettato il caso hindi: il LLM aveva risposto stop (quindi fine «naturale» lato API), ma alcuni paragrafi francesi erano rimasti intatti nell’output — invisibili al filtro finish_reason, rilevati dal filtro anti-fuga verbatim.
Strato 2 (probabilistico) — langdetect.detect_langs analizza la lingua dell’output e restituisce una distribuzione di probabilità su più lingue candidate. Si estrae la probabilità della lingua sorgente e quella della lingua target, poi si rifiuta solo se la probabilità della sorgente supera 0,80 e quella del target scende sotto 0,20 — una soglia deliberatamente conservativa per non generare falsi positivi sul code-switching tecnico (parole inglesi legittime in una traduzione italiana, per esempio). Questo strato viene bypassato per le lingue con script non latini (hindi hi, arabo ar, cinese zh, giapponese ja, coreano ko) dove un segnale di script sufficiente già convalida l’output. E gira solo se l’output ripulito ha almeno 100 caratteri, per evitare falsi positivi sul testo troppo corto.
I guardrail quantitativi
Sopra i due strati, due controlli più prosaici ma necessari:
- Empty-content guard: se il provider restituisce un output vuoto mentre
finish_reasonèstop, si rifiuta subito (altrimenti scriveremmo un file vuoto segnato come successo) - Sanity ratio: solo se la sorgente ha almeno 500 caratteri, si verifica che l’output non sia sospettosamente corto (tipicamente <
max(50, source/20)). È un rilevatore di troncamento invisibile, non una regola generale di lunghezza
Su Claude in particolare, max_tokens è passato da 4.096 a 32.768 nella v1.9 (la modifica è stata fatta lato codice da Claude dopo che ho constatato il sintomo e chiesto di indagare). La ragione documentata nel CHANGELOG: evitare la troncatura latente sui segmenti da 16k caratteri, con un margine aggiuntivo per le lingue con script non latin (FR → JA, ZH, KO, AR, HI) che consumano più token in output rispetto a uno script latino equivalente.
Resi per stato esplicito
La pipeline per file (translate_markdown_file()) restituisce ormai uno stato esplicito — success, failure o skipped. Il CLI aggrega questi stati e termina con un codice di uscita non nullo non appena almeno un file è fallito — cosa che rende il fallimento sfruttabile da uno script chiamante o dalla nuova CI aggiunta nella v1.9. Prima di questa v1.9, diversi errori erano solo stampati o passavano come traduzione riuscita: il process poteva terminare con 0 mentre il file era assente, incompleto o convalidato male. Lo stato skipped diventa a sua volta un segnale leggibile («ignorato volontariamente»), distinto da success («traduzione scritta correttamente»).
📄 Estratto Python: doppia validazione post-traduzione (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNovità 2: la nota di traduzione multi-posizione
Il bisogno: una nota discreta ma informativa
Quando AI-Powered Markdown Translator scrive una traduzione, aggiunge una nota di traduzione che indica il modello usato e la data. Prima della v1.9, questa nota veniva sistematicamente incollata in fondo al file, in un formato ereditato (legacy) con delimitatori visibili.
Il formato incollato in fondo poneva due problemi per i miei usi. Prima di tutto, il lettore veniva informato solo alla fine che il contenuto era stato tradotto dall’IA — è meglio avvisare dall’inizio, così si crea un’aspettativa corretta sul contenuto. Inoltre, la nota in fondo alla pagina non valorizzava il progetto di traduzione che rende tutto questo possibile: si legge l’articolo, e l’origine del flusso multilingue passa inosservata. Volevo quindi poter spostare la nota in alto mantenendo la tracciabilità — senza rompere gli usi esistenti. La v1.9 aggiunge due flag che non rompono nulla:
--note_position {top,bottom,both}: in alto, in basso o entrambe--note_format {legacy,marker}: formato legacy o formato marker (marker format)
Default retrocompatibili : legacy + bottom. Nessuna stringa di traduzione esistente cambia comportamento di default — si attivano esplicitamente i nuovi flag su richiesta.
Il formato marker: una scheda incorporata (embed card) GitHub pulita
Il formato marker sfrutta un dettaglio sottile del Markdown GitHub: le link reference definitions non utilizzate sono invisibili nel rendering. Si possono quindi codificare metadati (modello, data, fonte) in un commento-marker posizionato in cima al file — invisibile nel browser, ma conservato tale e quale quando si copia il sorgente grezzo.
GitHub in più genera una scheda incorporata (embed card) quando si condivide un link al file tradotto, e questa scheda mostra correttamente il titolo del documento senza inquinamento testuale.
Esempio di Markdown grezzo con formato marker in posizione top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...A colpo d’occhio, il lettore vede solo il titolo seguito dal contenuto. Il marker non inquina né il rendering HTML né la scheda di embed.
L’inserimento consapevole del frontmatter (frontmatter-aware)
Dettaglio tecnico ma cruciale: inserire una nota in top non significa «inserire alla riga 1 del file». Se il file ha un frontmatter YAML (ed è il caso di questo blog), bisogna inserire dopo il frontmatter — altrimenti la nota rompe il YAML.
Ho spiegato l’esigenza a Claude («inserisci la nota dopo il frontmatter, non prima — altrimenti rompi il YAML»), e lui ha prodotto un helper _split_frontmatter che rileva le fence --- di apertura/chiusura. Se il file ha una fence YAML non chiusa (caso malformato), l’helper solleva una RuntimeError invece di produrre silenziosamente un file rotto. Il passaggio da una funzione monolitica a 7 helper puri (separati e testabili) è tipico di ciò che il pair-IA ben guidato sa fare in fretta. Il mio ruolo qui: guida dei requisiti, tester, cliente finale che valida il risultato. Non scrivere codice. Su questo progetto porto più cappelli — tranne quello di scrivere il codice, che spetta a Claude.
| Posizione | Formato | Caso d’uso tipico |
|---|---|---|
top | marker | Articoli blog (nota discreta, card embed pulita) |
top | legacy | Documentazione interna dove conta la tracciabilità visibile |
bottom | marker | README open-source (coerente con il footer) |
bottom | legacy | Default — compatibile con le versioni precedenti |
both | marker | Articoli lunghi in cui top + bottom rassicurano |
both | legacy | Caso legacy con esigenza di doppia tracciabilità |
📄 Estratto Python : helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")Novità 3: la modalità --news per preservare le citazioni fonte EN
Il problema: tradurre senza rompere le citazioni
Quando scrivo articoli ia-actualites per questo blog (notizie IA multi-source quotidiane/settimanali), cito regolarmente tweet, post di blog, annunci di versione in inglese — spesso diversi per articolo. Se la traduzione tocca le citazioni, diventano false.
Una citazione tradotta è una citazione alterata. In tutte le versioni linguistiche (EN, DE, JA, ecc.), vogliamo mantenere l’inglese originale delle citazioni — è un requisito di fedeltà alle fonti — accompagnato dalla bandiera della lingua di destinazione e da una traduzione in corsivo per la comodità di lettura.
La soluzione: placeholder <NEWSQUOTE id="N"/>
| Fase | Azione |
|---|---|
| 1️⃣ | Markdown sorgente FR con citazioni EN in ingresso |
| 2️⃣ | Pre-elaborazione: estrazione delle citazioni EN, sostituzione con placeholder <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, ecc. |
| 3️⃣ | Traduzione API (FR → target_lang) — le citazioni EN originali non vengono mai inviate al LLM, solo i placeholder vengono inviati (preservati così come sono) |
| 4️⃣ | Post-elaborazione: ripristino dei placeholder con le citazioni EN originali intatte + inserimento della bandiera della lingua di destinazione |
| 5️⃣ | Validazione post-traduzione: tutti i placeholder sono stati ripristinati? |
| ✅ | Output di destinazione con citazioni EN preservate |
| ❌ | Fallimento se un placeholder non è stato ripristinato o se una citazione è stata alterata |
La modalità --news si basa su questo principio: una pre-elaborazione estrae tutte le citazioni EN, le sostituisce con placeholder tipo <NEWSQUOTE id="0"/>, traduce il resto e ripristina i placeholder intatti.
Il mapping LANG_FLAGS adatta la bandiera alla target_lang (15 lingue coperte) : 🇬🇧 per l’inglese, 🇩🇪 per il tedesco, 🇪🇸 per lo spagnolo, 🇮🇹 per l’italiano, 🇵🇹 per il portoghese, 🇳🇱 per il neerlandese, 🇵🇱 per il polacco, 🇸🇪 per lo svedese, 🇷🇴 per il romeno, 🇸🇦 per l’arabo, 🇮🇳 per l’hindi, 🇯🇵 per il giapponese, 🇰🇷 per il coreano, 🇨🇳 per il cinese, 🇫🇷 per il francese.
La validazione post-traduzione verifica che tutti i placeholder siano ripristinati intatti. L’errore non è una «fuga EN» — l’EN è voluto — ma un placeholder non ripristinato o una citazione alterata.
Casi d’uso attuali e prospettive
Oggi uso --news esclusivamente sugli articoli ia-actualites del blog. In futuro, potrebbe estendersi a qualsiasi articolo che mescoli prosa francese e citazioni fonte EN — interviste, resoconti di esperienza che citano articoli di ricerca in inglese, trascrizioni di presentazioni di conferenze.
Senza rileggere il codice: perché bisogna raddoppiare le protezioni
« Non leggo il codice. »
Non rileggo nulla. A volte guardo un diff in fretta — è raro, e succede solo quando Claude non riesce a cavarsela da solo su un punto. Ecco il flusso che uso quotidianamente e che ha prodotto la v1.9: Claude Code (Opus, esclusivamente) scrive il codice. Codex prende il relais quando Opus si blocca o quando la finestra d’uso è satura. GPT-5.5 in reasoning extra-high mette alla prova i piani prima dell’esecuzione. /pr-review-toolkit:review-pr rilegge la PR prima di ogni merge. Il mio ruolo si ferma a validare le direzioni e definire le protezioni.
Questo modo di sviluppare — sviluppo al feeling (vibe coding) integrale — non è mancanza di rigore. È un compromesso esplicito: meno rilettura umana, più validazione strumentata. Le 3 novità v1.9 che ho appena presentato sono tutte state prodotte in questo flusso. Ed è proprio perché non si rilegge il codice che bisogna raddoppiare le protezioni tecniche — non eliminarle.
Ecco le due protezioni messe in atto per rendere questo modo di sviluppare praticabile in produzione: uno stack qualità automatizzato (Protezione 1) e una revisione assistita IA in flusso multi-modello (Protezione 2).
Protezione 1: lo stack qualità automatizzato (14 hook + test pratici)
Panoramica
| Rete | Strumenti | Costo tipico | Bloccante in caso di fallimento |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hook), detect-secrets, Lizard CCN | < 10 s | Sì |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Sì, tranne pip-audit in reporting iniziale |
| CI esterna | SonarCloud, Codacy, CodeFactor | in parallelo | Non bloccante in locale, badge PR |
Dati v1.9: 14 hook, 229 test unittest stdlib, ~98 % di copertura sul nuovo codice v1.9, 11 badge SonarCloud, 3 piattaforme esterne.
Pre-commit: la rete rapida
| # | Strumento | Versione | Ruolo |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Lint shell |
| 2 | ruff (lint) | 0.8.6 | Lint Python |
| 3 | ruff (format) | 0.8.6 | Formattazione Python |
| 4 | prettier | 3.1.0 | Formattazione Markdown / JSON / YAML |
| 5 | trailing-whitespace | 5.0.0 | Rimozione degli spazi finali di riga |
| 6 | end-of-file-fixer | 5.0.0 | Newline finale obbligatoria |
| 7 | check-yaml | 5.0.0 | Validazione sintassi YAML |
| 8 | check-toml | 5.0.0 | Validazione sintassi TOML |
| 9 | check-added-large-files | 5.0.0 | Blocca i grandi binari aggiunti per errore |
| 10 | check-merge-conflict | 5.0.0 | Rilevamento dei marker di conflitto Git |
| 11 | check-executables-have-shebangs | 5.0.0 | Verifica che gli eseguibili abbiano uno shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Verifica che gli script con shebang siano eseguibili |
| 13 | detect-secrets | 1.5.0 | Rilevamento di chiavi API e segreti |
| 14 | check-complexity (Lizard) | local | Soglia di complessità ciclomatica sul nuovo codice |
Totale misurato: circa 2-3 secondi sull’intero repo (a caldo, pre-commit run --all-files cronomettrato a ~2,4 s). Su un commit medio che tocca solo pochi file, è ancora più veloce. La regola pratica che applico: sopra i 10 s, gli sviluppatori aggirano il controllo (anche il pair-IA) — quindi bisogna mantenere sempre questa rete rapida.
Pre-push: la rete pesante
- mypy in modalità lasca: niente strict totale (il codice storico di translate.py non passerebbe), ma una verifica di progresso sul nuovo codice
- Opengrep SAST:
p/security-audit p/default p/python— circa 30 secondi per scansionare injection, eval, deserializzazione non sicura - pip-audit incapsulato da
scripts/check-pip-audit.sh: cattura l’output JSON, classifica lato shell gli errori di trasporto (rete, PyPI down) per non confondere vulnerabilità e indisponibilità, e riporta le vulnerabilità. In modalità reporting iniziale per la v1.9 (warn + exit 0) — da irrigidire in blocco dopo una PR di bump delle dipendenze obsolete. - unittest discovery:
python -m unittest discoversutests/poiscripts/tests/— 229 test, circa 8 secondi in locale
CI esterna: SonarCloud + Codacy + CodeFactor
Il workflow .github/workflows/sonarcloud.yml (project key jls42_ai-powered-markdown-translator) gira su ogni PR. 11 badge SonarCloud mostrati sul README: Quality Gate, valutazione di Security/Reliability/Maintainability, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC.
Perché la ridondanza Codacy + SonarCloud + CodeFactor? Perché ognuno vede cose diverse. Codacy ha segnalato duplicazioni che SonarCloud non aveva indicato. SonarCloud ha segnalato segnali di scarsa qualità (i famosi code smells) che Codacy lasciava passare. CodeFactor ha segnalato problemi di complessità che gli altri due ignoravano. Nessuno sarebbe bastato da solo. Il costo marginale di una piattaforma supplementare è nullo (badge gratuito, integrazione di 5 minuti), quindi moltiplichiamo gli angoli di visione.
Test: unittest stdlib (non pytest)
229 test, 0 regressioni sui 6 mesi della PR, ~98 % di copertura sul nuovo codice v1.9.
Dettaglio tipico:
test_silent_failure.py: 97 test mirati alla doppia validazionetest_orchestration.py: 79 test sulla pipeline orchestratricetest_translation_note_position.py: 38 test sulla matrice posizione × formatotest_audit_verdict.py: 15 test sul wrapper pip-audit (inscripts/tests/)
Nota di onestà: la copertura ~98 % riguarda il nuovo codice v1.9 — non l’insieme storico di translate.py, che contiene ancora alcune funzioni ereditate poco coperte dalla nuova batteria di test. Lo menziono esplicitamente perché dichiarare «98 % di copertura» su un progetto intero sarebbe fuorviante.
Scelta discutibile ma assunta: esecutore dei test unittest (stdlib), non pytest. Il prefisso test_ è per abitudine, ma è unittest che esegue. Perché? In un progetto in vibe coding, ogni dipendenza aggiunta = ogni dipendenza che l’IA può usare male. La semplicità è un obiettivo. unittest è nella libreria standard di Python, zero installazione, zero plugin.
Test pratici: multi-repo + uso interno del prodotto (dogfooding) + verifica del rendering visivo
I 229 test unittest non bastano. Aggiungo tre livelli di test pratico:
1. Multi-repo — testare lo script su diversi repo pubblici con README in formati differenti. Questo fa emergere casi limite che le fixture non coprono — un README con 8 livelli di heading, un altro con shortcode ereditati, un terzo con codice incorporato esotico. È in questa fase che è stato scoperto l’incidente silent-failure della Novità 1.
2. Dogfooding sul blog — jls42.org è tradotto dallo script stesso. Ogni articolo pubblicato è un test live in produzione. Se un caso limite passa attraverso i test unitari, emergerà qui, sulla pagina che state leggendo. È il test ultimo — ciò che è online è ciò che il progetto ha prodotto.
3. Test del rendering visivo — verifico che le traduzioni renderizzate si visualizzino correttamente, sia nel browser (pagina web finale), sia direttamente in VSCode tramite un plugin di anteprima Markdown. L’idea: non accontentarsi di un Markdown sintatticamente valido, ma vedere il rendering reale. I rendering visivi fanno emergere bug di aspetto (tabelle rotte, code block malformati, frontmatter interpretato male) che i test testuali non vedono.
Le IA partecipano anche a questi test. /pr-review-toolkit esegue il codice in ambiente di test, e l’uso in pair-IA include sistematicamente passaggi di validazione visiva («verifica che la traduzione tedesca della pagina X venga visualizzata correttamente»).
📄 Estratto .pre-commit-config.yaml (hook principali pre-commit)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Estratto scripts/check-security-sast.sh
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Estratto .github/workflows/sonarcloud.yml
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Protezione 2: la revisione assistita IA + il flusso multi-modello
Precisazione di vocabolario: quando parlo di Claude Opus in questa sezione, parlo del modello che uso per sviluppare la v1.9 — non del modello che AI-Powered Markdown Translator usa per tradurre. Il progetto supporta di per sé 4 provider (OpenAI, Mistral AI, Claude, Gemini) e qualsiasi modello (Sonnet, Haiku, Mistral Large, Gemini 3 Pro, ecc.). Sul lato sviluppo, blocco su Opus. Sul lato esecuzione, il progetto resta agnostico.
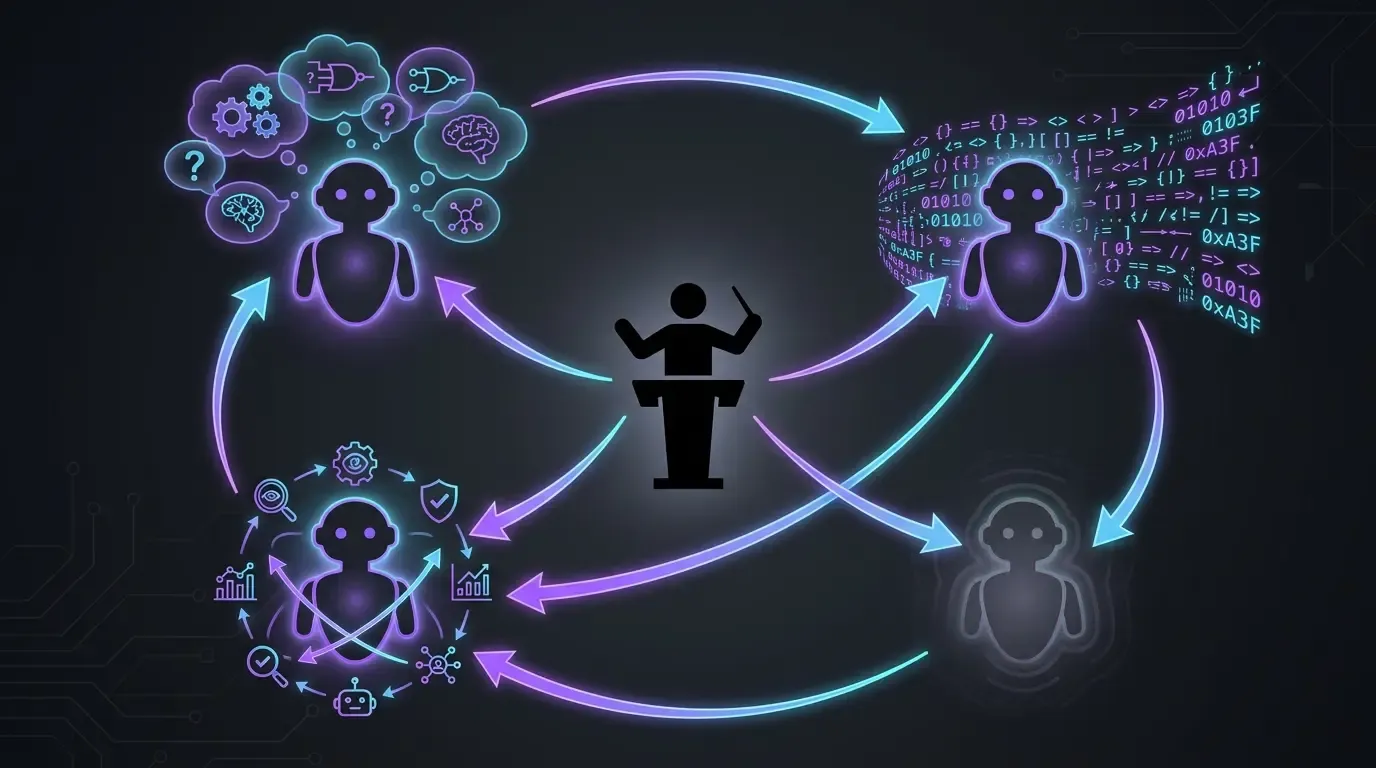
Il vero flusso di lavoro: 4 modelli, 4 ruoli (per sviluppare)
- Claude Code in Opus, esclusivamente (anthropic): esecuzione principale. Legge il contesto, scrive il codice, applica le correzioni. Niente Sonnet, niente Haiku, niente fast mode. Su questo progetto, voglio il modello di fascia alta ogni volta — l’idea è semplice: ci assicuriamo di avere il meglio per puntare al miglior risultato possibile.
- OpenAI Codex come soluzione di riserva (fallback): usato in due casi precisi:
- Quando Opus va in crisi su un tema (raro ma esistente — per esempio su correzioni richieste da agenti esterni tipo Codacy o SonarCloud, Claude a volte non converge e sposto il tema su Codex per sbloccare)
- Quando la finestra di utilizzo Anthropic è satura. Codex permette di non perdere lo slancio in attesa del reset della quota.
- GPT-5.5 reasoning extra-high (
xhigh): mette alla prova i piani prima dell’esecuzione. Prima di lasciare che Claude Code attacchi un tema, passo il piano a GPT-5.5 in reasoning extra-high. Pone le domande giuste, fa emergere i punti ciechi. Evita di partire in una direzione sbagliata che andrebbe corretta più tardi. /pr-review-toolkit:review-pr(skill plugin Claude Code): revisione prima del merge con agenti specializzati (sicurezza, qualità, test, commenti, progettazione dei tipi). Lo skill gira sulla PR prima che io faccia il merge — è l’ultima rete IA prima che il codice entri inmain.
Nessuno di questi modelli basta da solo. Ognuno svolge un ruolo diverso — l’esecutore di fascia alta, il sostituto di capacità, il provocatore di piani, il revisore (reviewer) multi-angolo.
/pr-review-toolkit : ciò che non avrei visto
Tutto. Non guardo il codice. Lo skill fa emergere tutto — bug nascosti, problemi di sicurezza, incoerenze nei test, test che passano ma non testano nulla.
Sulla PR #2 (75 commit, 9 837 additions, 1 982 suppressions, 58 file), un umano da solo avrebbe saltato l’80 % della PR per stanchezza. Lo skill non salta nulla. Legge ogni diff, ogni test, ogni commento. E soprattutto, mette in discussione — rifiuta i pattern che identifica come sbagliati e propone alternative.
L’umano come direttore d’orchestra, non come musicista
Il mio ruolo copre tutta la catena — tranne la scrittura del codice. Indosso i cappelli di product manager (riflettere sulle feature, dare priorità, arbitrare), QA (testare su casi reali, validare visivamente il rendering), tech lead (mettere in discussione i piani con GPT-5.5 reasoning extra-high), cliente finale (giudicare il risultato sulla mia esperienza d’uso quotidiana sul blog). L’unico cappello che non indosso è quello del coder. Il resto, sono io.
Sono diventato produttore, non musicista.
Al servizio del blog: si traduce da solo (quasi 1 800 traduzioni)
AI-Powered Markdown Translator genera il proprio README in 14 lingue, ed è lui a produrre tutte le versioni straniere dei contenuti di jls42.org. In concreto: quasi 1 800 versioni tradotte alimentano il blog (25 articoli + 4 progetti + 98 news IA × 14 lingue, escluse le sorgenti FR — quindi 1 778 versioni al momento in cui scrivo). Ogni pagina che sfogliate qui in una lingua diversa dal francese è passata da questo progetto.
È un uso interno del prodotto (dogfooding) spinto all’estremo — e stressa la traduzione sull’articolo che parla della traduzione. Se ciò che leggete in ar, hi o ko è coerente, significa che la rete della Novità 1 (validazione post-traduzione) regge; se la nota di traduzione viene visualizzata correttamente in alto, significa che la Novità 2 (nota multi-posizione) funziona; se le citazioni EN sono preservate nelle versioni linguistiche, significa che anche la Novità 3 (modalità --news) funziona.
Bilancio: pair-IA rigoroso, non pair-IA improvvisato
Lo sviluppo a sentimento ha una cattiva reputazione per buone ragioni. È proprio contro quelle che lavoro. Quattro lezioni concrete emergono da questa v1.9:
-
I fallimenti silenziosi sono il nemico numero uno. L’IA produce codice che sembra OK e passa attraverso i test unitari. Validazione lato client sistematica. E usare un’altra IA per rileggere la produzione reale, non solo il codice.
-
Hook pre-commit < 10 s altrimenti aggirati; i pre-push possono richiedere 30 s+. L’IA aggiunge volentieri strumenti senza considerare il loro costo. Da inquadrare manualmente, sia nel piano sia a posteriori — l’importante è che alla fine i hook siano ben tarati e realmente usati ogni giorno.
-
Copertura senza asserzione forte = teatro. L’IA può generare 200 test che passano e che non testano nulla. unittest + asserzioni precise > pytest con una valanga di mock. Verificare il valore restituito, non solo che il codice non sia crashato.
-
La revisione (PR review) IA non è un’opzione. Quando l’autore umano non ha riletto, il revisore IA non è un gadget — è l’occhio delegato.
Il vibe coding fatto bene è anche accettare di non leggere il codice e delegare la lettura critica ad altre IA che lo fanno davvero.
Ciò che questo progetto rivela
Questa v1.9 illustra diversi aspetti del mio modo di lavorare:
- Il ruolo umano copre tutta la catena tranne il codice: prodotto (riflettere sulle feature, dare priorità), QA (testare su casi reali, validare visivamente), tech lead (mettere in discussione i piani con un LLM in reasoning extra-high), cliente finale (giudicare sull’uso reale). L’unico cappello che non indosso è quello di programmare.
- Raddoppiare le reti, non eliminarle: meno revisione umana = più validazione strumentata. Compromesso assunto, non mancanza di rigore. Se elimino la revisione, devo raddoppiare le reti, non fidarmi ciecamente dell’IA.
- L’IA per scoprire i bug dell’IA: il fallimento silenzioso è stato trovato da Claude durante i test pratici multi-repo. Delega completa: si può anche delegare la revisione critica.
- Il pair-IA come moltiplicatore sul tempo personale: porto avanti questo progetto nelle mie serate e nei weekend. Senza pair-IA, chiaramente non andrei così lontano né così in fretta. Con esso, posso mantenere un progetto open-source a livello industriale a margine dei miei altri impegni. È ciò che il vibe coding rende possibile — non sostituire lo sviluppatore, ma permettergli di fare ciò che da solo non potrebbe.
- Iterare invece di rifare tutto: 9 versioni, refactoring incrementale (1 funzione → 7 helper), retrocompatibilità preservata. Il pair-IA aiuta a iterare rapidamente senza riscrivere tutto.
Risorse
- AI-Powered Markdown Translator su GitHub
- Release v1.9
- PR #2 — 75 commit, migrazione + qualità
- CHANGELOG completo
- Pagina progetto su questo blog
- Articolo 2024 — v1.5 (stile release notes) — per confrontare il tono
- Approfondimento AWS Diagram — altro articolo della serie
Se volete testare AI-Powered Markdown Translator sui vostri Markdown — README open-source, articoli di blog, documentazione tecnica —, il codice è su GitHub. Installazione in pochi minuti, 4 provider supportati, modalità --eco per ridurre il costo, modalità --news per preservare le citazioni sorgente, e ora uno stack qualità v1.9 che potete riutilizzare come template per i vostri progetti in pair-IA.
Se sviluppate a sentimento (vibe coding) i vostri progetti personali, non andate sulla soluzione più semplice sul fronte qualità. L’affidabilità è il prezzo della velocità — assumete entrambi insieme.