ai-powered-markdown-translatorArticle translated from fr to en with gpt-5.4-mini.
AI-Powered Markdown Translator is an open-source project I have maintained since 2024: a Python script that translates any Markdown file into 14 languages via 4 AI providers (OpenAI, Mistral AI, Claude, Gemini). It powers this blog with every post — every page you read here in a language other than French has gone through it — and nearly 1,800 translated versions run in production thanks to it.
On May 8, 2026, I released v1.9, which brings together 75 commits and marks the biggest update since v1.5 in 2024. Three product updates:
- Post-translation validation (silent-failure protection)
- Multi-position translation note (top, bottom, or both)
--newsmode to preserve EN source quotes
But this v1.9 has a particularity I want to tell here: all the code was written in pair-AI. Not a single line typed by hand. So in addition to the 3 new features, this article also covers the “how”: what guardrails do we put in place to aim for clean, secure code when we don’t review by ourselves what the AI produces?
The context: a project used every day, lightly maintained on the code side
From September 2024 to May 2026: continuous use, sporadic maintenance
I had published an article that detailed the source code of v1.5 in 2024. At the time, I published the script directly in the article. Today, the angle has changed: what matters now is not so much the code I write, but the workflow that produces it.
Between v1.5 released in September 2024 and January 2026, the project kept running — it translates every new piece of content on this blog — but the public code barely moved. Only one commit was pushed in 2025. During all that time, I was evolving the code locally for my personal needs — especially the models, which I swapped as new ones came out — but those changes stayed on my machine. The public version on GitLab still pointed to the v1.5 default values.
At the start of 2026, I made a first attempt to bring things up to date: three releases in two months (v1.6 and v1.7 in two days at the start of January, v1.8 in March) that brought the project up to date feature-wise — 2026 models, Gemini support, --eco mode, single file, --news mode for source quotes. But still no CI, no automated tests, no quality gates — which was a real problem for me if I wanted to go further with an AI agent coding in my place.
The pace of a side-project
Why the gap? Because I carry this project on my own time. I have a family, a life away from the screen, so the project only moves forward in bursts when I find evenings and weekends. I’m passionate, I still spend quite a lot of time on these topics — I test a lot, I guide the agents, I validate the results — but the pace is not that of a professional project.
Pair-AI changes exactly that. It lets me move forward between two constraints — the passion and the balance of life away from the screen. Without pair-AI, I clearly wouldn’t go nearly as far or as fast. With it, I can maintain an open-source project at industrial level without dedicating my life to it.
The initial goal: quality + GitLab → GitHub migration
In mid-April 2026, I wanted to finally deal with it seriously. Two simple goals:
- Add a quality layer (static analysis, tests, CI)
- Migrate the repo from GitLab to GitHub
Nothing more. Except that with a pair-AI coding agent, you never write what was planned. The PR ended up at 75 commits, 9,837 additions, 1,982 deletions, 58 files.
| Version | Date | Main contribution |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, then Mistral, then Claude |
| 1.5 | Sep. 2024 | Refactor clients, 2024 models (gpt-4o, claude-3.5-sonnet) |
| 1.6 | Jan. 2026 | 2026 models (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, --eco mode, single file (--file) |
| 1.7 | Jan. 2026 | --keep_filename, .env, preserved inline code |
| 1.8 | Mar. 2026 | GPT-5.4 models by default, --news mode with citation placeholders |
| 1.9 | May 2026 | Post-translation validation, multi-position note, quality stack: 14 hooks + 229 tests + AI review |
The snowball effect
Every quality tool I added revealed issues. Codacy flagged duplications. SonarCloud raised code smells (signals that code will age badly: functions that are too long, unused parameters, awkward structures). /pr-review-toolkit pointed out hidden bugs. With every finding, the agent fixed it, sometimes improving adjacent things too.
The scope expanded organically. That’s exactly what I wanted — modernize the project — but the amount of effort was dictated by the tools, not by me. For a vibe-coding project, this is a key point: quality tools steer the work as much as they verify it.
New feature 1: post-translation validation (silent-failure protection)
The incident: the AI found the bug during testing
While testing the PR on README files from different public repos — a case no fixture covered — the AI surfaced what I had missed: on some languages (notably Hindi, ISO code hi), passages were still remaining in the source language in the middle of the translation. The API had returned 200, the script had written the file, but the content was only half translated. And this got through the existing unit test suite — which didn’t cover this real multi-language case.
This is exactly the kind of bug vibe coding can produce and that nobody sees. The code looks logical, the test fixtures don’t cover the case, the human doesn’t review the result. But here, by testing the script on real (multi-repo) cases, the AI itself did what the fixtures were not doing.
What I take from this: practical multi-repo tests find what unit tests miss. And AI can also be used to uncover bugs in previous AI agents — as long as you put it in front of varied real-world cases.
That was the moment I understood I needed to add real post-translation validation. This is the first new feature I explain now: the double validation layer.
The double validation layer
| Step | Action | If KO |
|---|---|---|
| 1️⃣ | API call provider | Network exception → ❌ failure |
| 2️⃣ | Provider whitelist for finish_reason (or stop_reason at Claude) | Outside whitelist → ❌ failure |
| 3️⃣ | Anti-leak: no source window ≥ 120 chars verbatim in the output | Source window found again → ❌ failure |
| 4️⃣ | langdetect.detect_langs (source vs target probabilities) | Source > 0.80 AND target < 0.20 → ❌ failure |
| 5️⃣ | Empty-content + output/source ratio (if source ≥ 500 chars) | Empty or output < max(50, source/20) → ❌ failure |
| ✅ | SUCCESS | exit code 0 |
Layer 1 (deterministic) — First safety net: check the status returned by the API. Each provider exposes a finish_reason field (or stop_reason at Claude) that indicates why the LLM stopped generating. The script maintains a provider-specific whitelist of acceptable statuses — the naming varies (stop at OpenAI/Mistral, STOP or FINISH_REASON_STOP at Gemini, end_turn or stop_sequence at Claude). The code also tolerates None as a safety fallback when the SDK does not return this field. Any other status — for example length, max_tokens or MAX_TOKENS depending on the provider, which indicate a response stopped by the token limit — triggers an immediate RuntimeError, with no recovery attempt.
A second deterministic safety net, subtler this time: verify that no passage of the source text appears verbatim in the translated output. Concretely, we extract windows of 120 characters or more from the source text; if one of them is found as-is in the output, then it wasn’t translated — failure. This is exactly the check that caught the Hindi case: the LLM had replied stop (so a “natural” end on the API side), but French paragraphs had remained intact in the output — invisible to the finish_reason safety net, detected by the verbatim anti-leak net.
Layer 2 (probabilistic) — langdetect.detect_langs analyzes the language of the output and returns a probability distribution across several candidate languages. We extract the probability of the source language and that of the target language, then reject only if the source probability exceeds 0.80 and the target probability falls below 0.20 — a deliberately conservative threshold so we don’t get false positives on technical code-switching (legitimate English words in a French translation, for example). This layer short-circuits for non-Latin scripts (Hindi hi, Arabic ar, Chinese zh, Japanese ja, Korean ko) where enough script signal already validates the output. And it only runs if the cleaned output is at least 100 characters long, to avoid false positives on text that is too short.
Quantitative guardrails
Above the two layers, two more prosaic but necessary checks:
- Empty-content guard: if the provider returns an empty output while
finish_reasonisstop, we reject immediately (otherwise we would write an empty file marked success) - Sanity ratio: only if the source is at least 500 characters long do we check that the output is not suspiciously short (typically <
max(50, source/20)). This is a detector for invisible truncation, not a general length rule
On Claude specifically, max_tokens went from 4,096 to 32,768 in v1.9 (the change was made in code by Claude after I observed the symptom and asked it to investigate). The reason documented in the CHANGELOG: avoid latent truncation on 16k-character segments, with extra margin for non-Latin script languages (FR → JA, ZH, KO, AR, HI) which consume more output tokens than an equivalent Latin script.
Explicit status returns
The file pipeline (translate_markdown_file()) now returns an explicit status — success, failure, or skipped. The CLI aggregates these statuses and exits with a non-zero code as soon as at least one file has failed — which makes the failure usable by a calling script or by the new CI added in v1.9. Before v1.9, several errors were only printed or passed as a successful translation: the process could end in 0 even though the file was missing, incomplete, or incorrectly validated. The skipped status itself becomes a readable signal (“intentionally skipped”), distinct from success (“translation written correctly”).
📄 Python excerpt: double post-translation validation (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNew feature 2: the multi-position translation note
The need: a discreet but informative note
When AI-Powered Markdown Translator writes a translation, it adds a translation note that indicates the model used and the date. Before v1.9, this note was always appended to the bottom of the file, in a legacy (legacy) format with visible delimiters.
Having the note stuck at the bottom created two problems for my own use cases. First, the reader was only told at the very end that the content had been translated by AI — it’s better to say it up front, it sets the right expectation for the content. Second, the footer note didn’t highlight the translation project that makes all this possible: you read the article, and the origin of the multilingual flow goes unnoticed. So I wanted to be able to move the note to the top while keeping traceability — without breaking existing usage. v1.9 adds two flags that don’t break anything:
--note_position {top,bottom,both}: top, bottom, or both--note_format {legacy,marker}: legacy format or marker format (marker format)
Backward-compatible defaults: legacy + bottom. No existing translation chain changes default behavior — the new flags are activated explicitly on demand.
The marker format: a clean GitHub embedded card (embed card)
The marker format leverages a subtle detail of GitHub Markdown: unused link reference definitions are invisible in the rendered output. We can therefore encode metadata (model, date, source) into a marker comment placed at the top of the file — invisible in the browser, but preserved as-is when copied in raw form.
GitHub also generates an embedded card (embed card) when you share a link to the translated file, and that card properly displays the document title without textual noise.
Raw Markdown example with marker format at top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...To the eye, the reader only sees the title followed by the content. The marker pollutes neither the HTML render nor the embed card.
Conscious insertion of the frontmatter (frontmatter-aware)
A technical but crucial detail: inserting a note in top does not mean “insert it at line 1 of the file.” If the file has a YAML frontmatter (which is the case for this blog), it must be inserted after the frontmatter — otherwise the note breaks the YAML.
I gave Claude the requirement (“insert the note after the frontmatter, not before — otherwise you break the YAML”), and it produced a _split_frontmatter helper that detects open/close --- fences. If the file has an unclosed YAML fence (a malformed case), the helper raises a RuntimeError rather than silently producing a broken file. The move from a monolithic function to 7 pure helpers (separated and testable) is typical of what well-guided pair-AI can do quickly. My role here: requirements guide, tester, final client who validates the result. Not coding. On this project I wear several hats — except the one of writing the code, which belongs to Claude.
| Position | Format | Typical use case |
|---|---|---|
top | marker | Blog posts (discreet note, clean embed card) |
top | legacy | Internal docs where visible traceability matters |
bottom | marker | Open-source README (consistent with footer) |
bottom | legacy | Defaults — backward compatible |
both | marker | Long articles where top + bottom are reassuring |
both | legacy | Legacy case with a dual traceability requirement |
📄 Python excerpt: _split_frontmatter helper (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")New feature 3: --news mode for preserving source EN quotes
The problem: translating without breaking quotes
When I write ia-actualites articles for this blog (daily/weekly multi-source AI news), I regularly quote tweets, blog posts, and release announcements in English — often several per article. If translation touches the quotes, they become wrong.
A translated quote is an altered quote. In every language version (EN, DE, JA, etc.), we want to keep the original English of the quotes — that is a requirement of fidelity to the sources — accompanied by the target-language flag and an italic translation for readability.
The solution: <NEWSQUOTE id="N"/> placeholders
| Step | Action |
|---|---|
| 1️⃣ | FR source Markdown with EN quotes as input |
| 2️⃣ | Pre-processing: extraction of EN quotes, replacement with <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, etc. placeholders |
| 3️⃣ | API translation (FR → target_lang) — the original EN quotes are never sent to the LLM, only the placeholders are (preserved as-is) |
| 4️⃣ | Post-processing: restoration of placeholders with the original EN quotes intact + insertion of the target-language flag |
| 5️⃣ | Post-translation validation: have all placeholders been restored? |
| ✅ | Target output with EN quotes preserved |
| ❌ | Failure if a placeholder is not restored or a quote is altered |
The --news mode relies on this principle: pre-processing extracts all EN quotes, replaces them with placeholders like <NEWSQUOTE id="0"/>, translates the rest, and restores the placeholders intact.
The LANG_FLAGS mapping adapts the flag to target_lang (15 languages covered): 🇬🇧 for English, 🇩🇪 for German, 🇪🇸 for Spanish, 🇮🇹 for Italian, 🇵🇹 for Portuguese, 🇳🇱 for Dutch, 🇵🇱 for Polish, 🇸🇪 for Swedish, 🇷🇴 for Romanian, 🇸🇦 for Arabic, 🇮🇳 for Hindi, 🇯🇵 for Japanese, 🇰🇷 for Korean, 🇨🇳 for Chinese, 🇫🇷 for French.
Post-translation validation checks that all placeholders have been restored intact. The error is not an “EN leak” — EN is intended — but an unrestored placeholder or an altered quote.
Current use cases and outlook
Today, I use --news exclusively on the blog’s ia-actualites articles. In the long run, that could extend to any article that mixes French prose and EN source quotes — interviews, experience reports that cite English research papers, transcripts of conference talks.
Without rereading the code: why the safeguards need to be doubled
“I don’t read the code.”
I don’t reread anything. I sometimes glance at a diff quickly — it’s rare, and only when Claude cannot handle a point on its own. Here is the flow I use every day and that produced v1.9: Claude Code (Opus, exclusively) writes the code. Codex takes over when Opus gets stuck or the usage window is saturated. GPT-5.5 in reasoning extra-high challenges the plans before execution. /pr-review-toolkit:review-pr rereads the PR before every merge. My role stops at validating directions and defining the safeguards.
This development mode — full vibe coding — is not a lack of rigor. It is an explicit trade-off: less human rereading, more automated validation. The 3 v1.9 features I just presented were all produced in this flow. And precisely because we do not reread the code, we need to double the technical safeguards — not remove them.
Here are the two safeguards put in place to make this development mode viable in production: an automated quality stack (Safeguard 1) and an AI-assisted review in a multi-model flow (Safeguard 2).
Safeguard 1: the automated quality stack (14 hooks + practical tests)
Overview
| Safety net | Tools | Typical cost | Blocking on failure |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hooks), detect-secrets, Lizard CCN | < 10 s | Yes |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Yes, except pip-audit in initial reporting mode |
| external CI | SonarCloud, Codacy, CodeFactor | in parallel | Non-blocking locally, PR badges |
v1.9 figures: 14 hooks, 229 unittest stdlib tests, ~98% coverage on the new v1.9 code, 11 SonarCloud badges, 3 external platforms.
Pre-commit: the fast net
| # | Tool | Version | Role |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Shell lint |
| 2 | ruff (lint) | 0.8.6 | Python lint |
| 3 | ruff (format) | 0.8.6 | Python formatting |
| 4 | prettier | 3.1.0 | Markdown / JSON / YAML formatting |
| 5 | trailing-whitespace | 5.0.0 | Remove trailing whitespace |
| 6 | end-of-file-fixer | 5.0.0 | Mandatory final newline |
| 7 | check-yaml | 5.0.0 | YAML syntax validation |
| 8 | check-toml | 5.0.0 | TOML syntax validation |
| 9 | check-added-large-files | 5.0.0 | Block large binaries added by accident |
| 10 | check-merge-conflict | 5.0.0 | Detect Git conflict markers |
| 11 | check-executables-have-shebangs | 5.0.0 | Verify that executables have a shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Verify that shebang scripts are executable |
| 13 | detect-secrets | 1.5.0 | Detect API keys and secrets |
| 14 | check-complexity (Lizard) | local | Cyclomatic complexity ceiling on new code |
Measured total: about 2 to 3 seconds across the entire repo (warm, pre-commit run --all-files timed at about 2.4 s). On an average commit that only touches a few files, it is even faster. The rule of thumb I apply: above 10 s, developers work around it (pair-AI too) — so this fast net has to stay in place permanently.
Pre-push: the heavy net
- mypy in lax mode: no full strictness (the historical translate.py code would not pass), but a progress check on new code
- Opengrep SAST:
p/security-audit p/default p/python— about 30 seconds to scan for injections, eval, unsafe deserialization - pip-audit wrapped by
scripts/check-pip-audit.sh: capture the JSON output, classify transport errors on the shell side (network, PyPI down) so as not to confuse vulnerability with unavailability, and report vulnerabilities. In initial reporting mode for v1.9 (warn + exit 0) — to be hardened into blocking after a PR that bumps obsolete dependencies. - unittest discovery:
python -m unittest discoverontests/thenscripts/tests/— 229 tests, about 8 seconds locally
External CI: SonarCloud + Codacy + CodeFactor
The .github/workflows/sonarcloud.yml workflow (project key jls42_ai-powered-markdown-translator) runs on every PR. 11 SonarCloud badges displayed on the README: Quality Gate, Security/Reliability/Maintainability Rating, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC.
Why the Codacy + SonarCloud + CodeFactor redundancy? Because each one sees different things. Codacy surfaced duplications that SonarCloud had not reported. SonarCloud surfaced poor-quality signals (the famous code smells) that Codacy let through. CodeFactor surfaced complexity issues that the other two ignored. None of them would have been enough on its own. The marginal cost of an additional platform is zero (free badge, 5-minute integration), so we multiply the perspectives.
Tests: unittest stdlib (not pytest)
229 tests, 0 regression over the 6 months of the PR, ~98% coverage on the new v1.9 code.
Typical detail:
test_silent_failure.py: 97 tests targeting the double validationtest_orchestration.py: 79 tests on the orchestrator pipelinetest_translation_note_position.py: 38 tests on the position × format matrixtest_audit_verdict.py: 15 tests on the pip-audit wrapper (inscripts/tests/)
Honesty note: the ~98% coverage refers to the new v1.9 code — not the full historical translate.py, which still contains a few inherited functions with limited coverage by the new test suite. I mention this explicitly because claiming “98% coverage” on an entire project would be misleading.
A debatable but deliberate choice: unittest test runner (stdlib), not pytest. The test_ prefix is habitual, but it is unittest that executes. Why? In a vibe-coding project, every dependency added = every dependency the AI can misuse. Simplicity is a goal. unittest is in Python’s standard library, zero installation, zero plugin.
Practical tests: multi-repo + internal product use (dogfooding) + visual rendering verification
The 229 unittest tests are not enough. I add three layers of practical testing:
1. Multi-repo — test the script on several public repos with READMEs in different formats. This reveals edge cases that fixtures do not cover — a README with 8 heading levels, another with legacy shortcodes, a third with exotic embedded code. It was in this phase that the silent-failure incident from New feature 1 was discovered.
2. Dogfooding on the blog — jls42.org is translated by the script itself. Every published article is a live production test. If an edge case slips through the unit tests, it will surface here, on the page you are reading. This is the ultimate test — what is online is what the project produced.
3. Visual rendering test — I verify that the rendered translations display correctly, either in the browser (final web page) or directly in VSCode via a Markdown preview plugin. The idea: not to settle for syntactically valid Markdown, but to see the actual rendering. Visual renderings surface appearance bugs (broken tables, malformed code blocks, misinterpreted frontmatter) that text tests do not catch.
The AIs also take part in these tests. /pr-review-toolkit runs the code in a test environment, and pair-AI usage systematically includes visual validation passes (“check that the German translation of page X displays correctly”).
📄 Python excerpt: main pre-commit hooks (.pre-commit-config.yaml)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Excerpt from scripts/check-security-sast.sh
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Excerpt from .github/workflows/sonarcloud.yml
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Safeguard 2: AI-assisted review + the multi-model flow
Vocabulary note: when I talk about Claude Opus in this section, I am talking about the model I use to develop v1.9 — not the model that AI-Powered Markdown Translator uses to translate. The project itself supports 4 providers (OpenAI, Mistral AI, Claude, Gemini) and any model (Sonnet, Haiku, Mistral Large, Gemini 3 Pro, etc.). On the development side, I lock onto Opus. At runtime, the project remains agnostic.
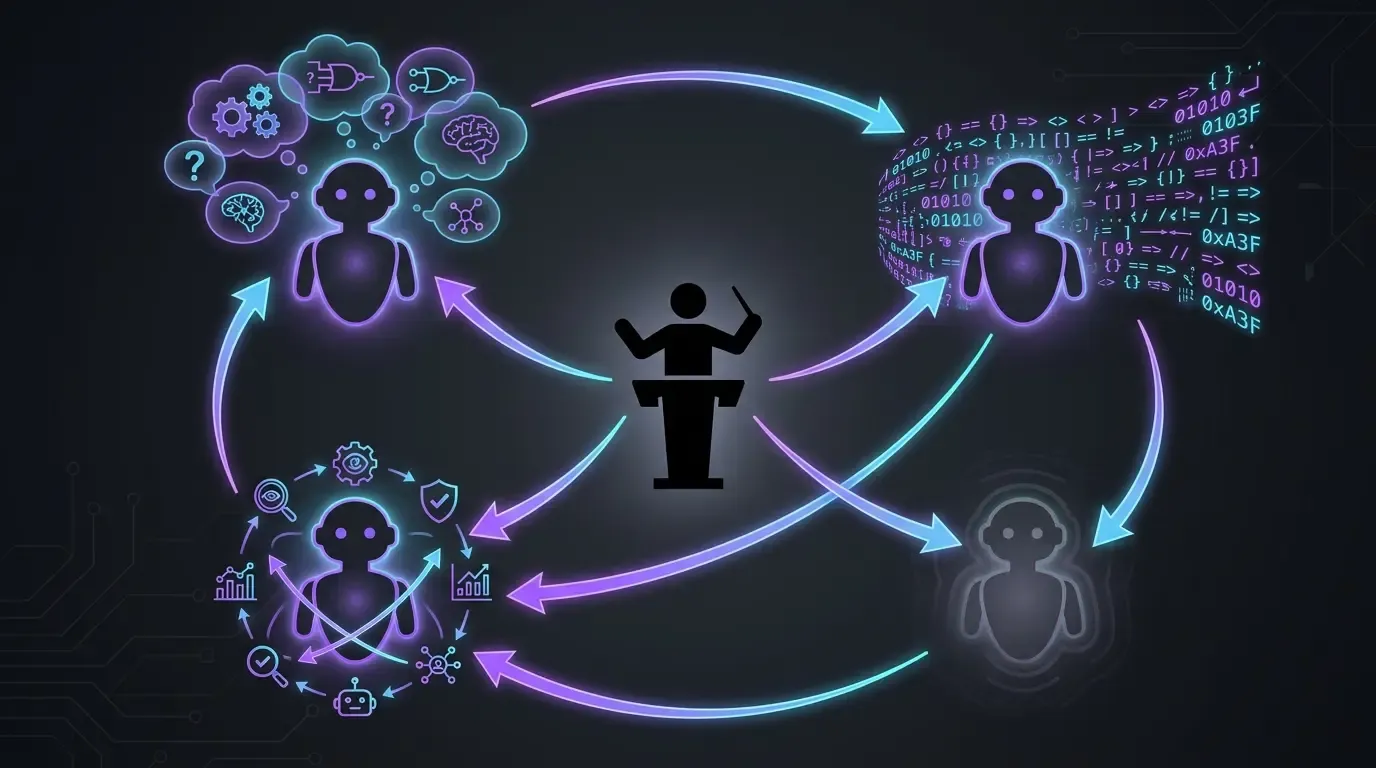
The real workflow: 4 models, 4 roles (for development)
- Claude Code in Opus, exclusively (Anthropic): main execution. It reads the context, writes the code, applies the fixes. No Sonnet, no Haiku, no fast mode. On this project, I want the top-end model every time — the idea is simple: we make sure we have the best to aim for the best possible result.
- OpenAI Codex as a fallback: used in two specific cases:
- When Opus completely misses the mark on a topic (rare but it happens — for example, on fixes requested by external agents like Codacy or SonarCloud, Claude sometimes fails to converge and I switch the topic over to Codex to unblock it)
- When the Anthropic usage window is saturated. Codex makes it possible not to lose momentum while waiting for the quota reset.
- GPT-5.5 reasoning extra-high (
xhigh): challenges plans before execution. Before letting Claude Code tackle a topic, I run the plan through GPT-5.5 in reasoning extra-high. It asks the right questions, surfaces blind spots. That keeps us from heading down the wrong path and having to patch it up later. /pr-review-toolkit:review-pr(Claude Code skill plugin): pre-merge review with specialized agents (security, quality, tests, comments, type design). The skill runs on the PR before I merge it — it’s the last AI safety net before the code entersmain.
None of these models is enough on its own. Each plays a different role — the top-end executor, the capacity fallback, the plan challenger, the multi-angle reviewer.
/pr-review-toolkit : what I would not have seen
Everything. I don’t look at the code. The skill surfaces everything — hidden bugs, security issues, test inconsistencies, tests that pass but test nothing.
On PR #2 (75 commits, 9 837 additions, 1 982 deletions, 58 files), a human alone would have skipped 80% of the PR out of fatigue. The skill skips nothing. It reads every diff, every test, every comment. And above all, it challenges — it rejects the patterns it identifies as bad, and it proposes alternatives.
The human as conductor, not musician
My role covers the whole chain — except writing the code. I wear the hats of product manager (thinking about features, prioritizing, arbitrating), QA (testing on real cases, visually validating the output), tech lead (challenging plans with GPT-5.5 reasoning extra-high), final customer (judging the result based on my own day-to-day usage experience on the blog). The only hat I don’t wear is coding. The rest is me.
I’ve become a producer, not a musician.
Serving the blog: it translates itself (nearly 1,800 translations)
AI-Powered Markdown Translator generates its own README in 14 languages, and it’s what produces all foreign-language versions of the content on jls42.org. Concretely: nearly 1,800 translated versions feed the blog (25 articles + 4 projects + 98 AI news items × 14 languages, excluding the French sources — i.e. 1,778 versions as I write this). Every page you browse here in a language other than French has gone through this project.
This is dogfooding pushed to the extreme — and it stress-tests translation on the article that talks about translation. If what you’re reading in ar, hi, or ko is consistent, then Feature 1’s safety net (post-translation validation) is holding; if the translation note displays correctly at the top, then Feature 2 (multi-position note) is working; if the EN quotes are preserved in the localized versions, then Feature 3 (mode --news) is working too.
Takeaway: rigorous AI pair-programming, not sloppy AI pair-programming
Vibe-based development has a bad reputation for good reasons. That’s exactly what I’m working against. Four concrete lessons emerge from this v1.9:
-
Silent failures are enemy number one. AI produces code that looks fine and passes unit tests. Systematic client-side validation. And use another AI to review the real output, not just the code.
-
Pre-commit hooks under 10 s or they get bypassed; pre-push hooks can take 30 s+. AI happily adds tools without considering their cost. Keep that under control manually, either in the plan or after the fact — what matters is that in the end the hooks are properly tuned and actually used day to day.
-
Coverage without strong assertions = theater. AI can generate 200 tests that pass and don’t test anything. unittest + precise assertions > pytest with mocks all over the place. Verify the returned value, not just that the code didn’t crash.
-
AI (PR review) review is not optional. When the human author hasn’t reviewed it, the AI reviewer isn’t a gimmick — it’s the delegated eye.
Good vibe coding also means accepting that we don’t read the code and delegating critical reading to other IAs that actually do it.
What this project reveals
This v1.9 illustrates several aspects of the way I work:
- The human role covers the whole chain except code: product (thinking about features, prioritizing), QA (testing on real cases, visually validating), tech lead (challenging plans with an LLM in reasoning extra-high), final customer (judging based on real usage). The only hat I don’t wear is coding.
- Double the safety nets, don’t remove them: less human review = more tool-assisted validation. An assumed tradeoff, not a lack of rigor. If I remove the review, I have to double the safety nets, not blindly trust AI.
- AI for discovering AI bugs: the silent failure was found by Claude during multi-repo hands-on testing. Full delegation: we can also delegate critical review.
- AI pair-programming as a multiplier on personal time: I carry this project on my evenings and weekends. Without AI pair-programming, I clearly wouldn’t go as far or as fast. With it, I can keep an open-source project at industrial quality alongside my other obligations. That’s what vibe coding makes possible — not replacing the developer, but enabling them to do what they couldn’t do alone.
- Iterate rather than redo everything: 9 versions, incremental refactoring (1 function → 7 helpers), backward compatibility preserved. AI pair-programming helps me iterate quickly without rewriting everything.
Resources
- AI-Powered Markdown Translator on GitHub
- Release v1.9
- PR #2 — 75 commits, migration + quality
- Full CHANGELOG
- Project page on this blog
- 2024 article — v1.5 (release notes style) — to compare the tone
- Deep Dive AWS Diagram — another article in the series
If you want to test AI-Powered Markdown Translator on your own Markdown — open-source README, blog posts, technical docs —, the code is on GitHub. Installation in a few minutes, 4 supported providers, --eco mode to reduce cost, --news mode to preserve source quotes, and now a v1.9 quality stack you can reuse as a template for your own AI pair-programming projects.
If you develop your personal projects through instinct (vibe coding), don’t go for the easiest path on quality. Reliability is the price of speed — embrace both together.