ai-powered-markdown-translatorArtikel vertaald van fr naar nl met gpt-5.4-mini.
AI-Powered Markdown Translator is een open-source project dat ik sinds 2024 onderhoud: een Python-script dat elk Markdown-bestand vertaalt naar 14 talen via 4 AI-providers (OpenAI, Mistral AI, Claude, Gemini). Het voedt deze blog bij elke publicatie — elke pagina die je hier leest in een andere taal dan het Frans is erdoorheen gegaan — en bijna 1.800 vertaalde versies draaien er in productie dankzij.
Op 8 mei 2026 heb ik v1.9 uitgebracht, die 75 commits bundelt en de grootste update sinds v1.5 uit 2024 markeert. Drie productnieuwigheden:
- Validatie na vertaling (tegen stille mislukkingen)
- Vertaalnotitie op meerdere posities (boven, onder of beide)
--news-modus om broncitaten in het EN te bewaren
Maar v1.9 heeft een bijzonderheid die ik hier wil vertellen: alle code is in pair-IA geschreven. Geen enkele regel is met de hand getypt. Dus naast de 3 nieuwigheden gaat dit artikel ook over het « hoe »: welke vangrails zet je op om te mikken op schone en veilige code wanneer je niet zelf naleest wat de AI produceert?
De context: een project dat elke dag wordt gebruikt, maar aan de codekant weinig werd onderhouden
Van september 2024 tot mei 2026: continu gebruik, onderhoud in spurten
Ik had een artikel gepubliceerd dat de broncode van v1.5 in 2024 uitlegd. In die tijd publiceerde ik het script rechtstreeks in het artikel. Vandaag is de invalshoek veranderd: wat telt is niet langer zozeer de code die ik schrijf, maar de workflow die die code produceert.
Tussen de v1.5 die in september 2024 werd uitgebracht en januari 2026 bleef het project draaien — het vertaalt elke nieuwe inhoud van deze blog — maar de publieke code bewoog nauwelijks. In 2025 werd slechts één commit gepusht. Al die tijd liet ik de code lokaal evolueren voor mijn persoonlijke noden — vooral de modellen, die ik verving naarmate er nieuwe releases kwamen — maar die evoluties bleven op mijn machine. De publieke versie op GitLab bleef naar de standaardwaarden van v1.5 wijzen.
Begin 2026 heb ik een eerste inhaalbeweging gedaan: drie releases in twee maanden (v1.6 en v1.7 op twee dagen begin januari, v1.8 in maart) die het project functioneel weer up-to-date brachten — 2026-modellen, Gemini-ondersteuning, --eco-modus, enkel bestand, --news-modus voor broncitaten. Maar nog steeds zonder CI, zonder geautomatiseerde tests, zonder kwaliteitsgates — wat voor mij een echt probleem vormde om verder te gaan met een AI-agent die code in mijn plaats schrijft.
Het tempo van een project in vrije tijd
Waarom dat verschil? Omdat ik dit project in mijn vrije tijd draag. Ik heb een gezin, een leven buiten het scherm, dus de evolutie gaat alleen in spurten vooruit wanneer ik de avonden en weekends vind. Ik ben gepassioneerd, ik besteed toch behoorlijk wat tijd aan deze onderwerpen — ik test veel, ik stuur de agents aan, ik valideer de resultaten — maar het tempo is niet dat van een professioneel project.
Pair-IA verandert precies dat. Het laat me vooruitgaan tussen twee beperkingen — de passie en het evenwicht van het leven buiten het scherm. Zonder pair-IA zou ik duidelijk niet zo ver of zo snel gaan. Met pair-IA kan ik een open-source project op industrieel niveau onderhouden zonder er mijn leven aan te wijden.
De oorspronkelijke doelstelling: kwaliteit + migratie GitLab → GitHub
Halverwege april 2026 wilde ik me er eindelijk serieus mee bezighouden. Twee eenvoudige doelstellingen:
- Een kwaliteitslaag toevoegen (statistische analyse, tests, CI)
- De repo migreren van GitLab naar GitHub
Niet meer dan dat. Alleen schrijft men met een code-agent in pair-IA nooit precies wat gepland was. De PR eindigde op 75 commits, 9.837 toevoegingen, 1.982 verwijderingen, 58 bestanden.
| Versie | Datum | Belangrijkste bijdrage |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, daarna Mistral, daarna Claude |
| 1.5 | sept. 2024 | Refactor van clients, 2024-modellen (gpt-4o, claude-3.5-sonnet) |
| 1.6 | jan. 2026 | 2026-modellen (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, --eco-modus, enkel bestand (--file) |
| 1.7 | jan. 2026 | --keep_filename, .env, behouden inline code |
| 1.8 | maart 2026 | GPT-5.4-modellen standaard, --news-modus met citatie-placeholders |
| 1.9 | mei 2026 | Validatie na vertaling, notitie op meerdere posities, kwaliteitsstack 14 hooks + 229 tests + AI-review |
Het sneeuwbaleffect
Elke toegevoegde kwaliteitstool bracht problemen aan het licht. Codacy wees duplicaties aan. SonarCloud bracht code smells naar boven (signalen dat code slecht zal verouderen: te lange functies, ongebruikte parameters, gekunstelde structuren). /pr-review-toolkit wees op verborgen bugs. Bij elke melding corrigeerde de agent, soms door ook gerelateerde zaken te verbeteren.
De scope explodeerde organisch. Dat was precies wat ik wilde — het project moderniseren — maar de mate van inspanning werd bepaald door de tools, niet door mij. Voor een project in vibe coding is dat een sleutelpunt: de kwaliteitstools sturen het werk evenzeer als ze het controleren.
Nieuwigheid 1: validatie na vertaling (tegen stille mislukkingen)
Het incident: de AI vond de bug, tijdens de tests
Tijdens het testen van de PR op README’s van verschillende publieke repos — een geval dat geen enkele fixture dekte — meldde de AI wat ik had gemist: in bepaalde talen (met name Hindi, ISO-code hi), bleven passages in de brontaal staan midden in de vertaling. De API had 200 teruggestuurd, het script had het bestand weggeschreven, maar de inhoud was half vertaald. En dat gleed door de bestaande set unit tests heen — die dit echte meertalige geval niet dekte.
Dat is precies het soort bug dat vibe coding kan produceren en dat niemand ziet. De code lijkt logisch, de testfixtures dekken het geval niet, de mens leest het resultaat niet na. Alleen testte de AI in dit geval het script op echte gevallen (multi-repo), en deed de AI zelf wat de fixtures niet deden.
Wat ik hieruit meeneem: praktische multi-repo-tests vinden wat unit-tests missen. En AI kan ook dienen om de bugs van eerdere AI-agents te ontdekken — op voorwaarde dat je haar confronteert met uiteenlopende echte gevallen.
Op dat moment begreep ik dat er een echte validatie na vertaling nodig was. Dat is de eerste nieuwigheid die ik nu toelicht: de dubbele validatielaag.
De dubbele validatielaag
| Stap | Actie | Als fout |
|---|---|---|
| 1️⃣ | API-call van de provider | Netwerkexception → ❌ failure |
| 2️⃣ | Provider-whitelist van finish_reason (of stop_reason bij Claude) | Buiten whitelist → ❌ failure |
| 3️⃣ | Anti-lek: geen enkel bronvenster van ≥ 120 tekens letterlijk in de output | Bronvenster teruggevonden → ❌ failure |
| 4️⃣ | langdetect.detect_langs (bronkans vs doelkans) | Bron > 0,80 EN doel < 0,20 → ❌ failure |
| 5️⃣ | Empty-content + output/bron-ratio (als bron ≥ 500 tekens) | Leeg of output < max(50, source/20) → ❌ failure |
| ✅ | SUCCESS | exit code 0 |
Laag 1 (deterministisch) — Eerste vangnet: controleer de status die de API teruggeeft. Elke provider exposeert een veld finish_reason (of stop_reason bij Claude) dat aangeeft waarom het LLM stopte met genereren. Het script houdt een provider-whitelist bij van aanvaardbare statussen — de nomenclatuur verschilt (stop bij OpenAI/Mistral, STOP of FINISH_REASON_STOP bij Gemini, end_turn of stop_sequence bij Claude). De code tolereert ook None uit voorzorg, wanneer de SDK dat veld niet terugstuurt. Elke andere status — bijvoorbeeld length, max_tokens of MAX_TOKENS afhankelijk van de provider, die signaleren dat een antwoord werd afgebroken door de tokenlimiet — triggert onmiddellijk een RuntimeError zonder enige herstelpoging.
Een tweede deterministisch vangnet, subtieler: controleren dat geen enkel stuk van de brontekst letterlijk in de vertaalde output verschijnt. Concreet extraheren we vensters van 120 tekens of meer uit de brontekst; als een daarvan exact terug te vinden is in de output, dan is het niet vertaald — failure. Precies deze check pakte het Hindi-geval op: het LLM had stop geantwoord (dus een « natuurlijke » afronding aan API-kant), maar Franse paragrafen waren intact gebleven in de output — onzichtbaar voor het finish_reason-vangnet, gedetecteerd door het anti-lek-vangnet op letterlijke tekst.
Laag 2 (probabilistisch) — langdetect.detect_langs analyseert de taal van de output en geeft een verdeling van waarschijnlijkheden over meerdere kandidaat-talen terug. We halen de waarschijnlijkheid van de brontaal en die van de doeltaal eruit, en verwerpen alleen als de bronprobabiliteit boven 0,80 uitkomt en de doelprobabiliteit onder 0,20 zakt — een bewust conservatieve drempel om geen false positives te krijgen bij technische code-switching (legitieme Engelse woorden in een Franse vertaling, bijvoorbeeld). Deze laag wordt overgeslagen voor talen met niet-Latijnse scripts (Hindi hi, Arabisch ar, Chinees zh, Japans ja, Koreaans ko), waar een voldoende script-signaal de output al valideert. En ze draait alleen als de opgeschoonde output minstens 100 tekens lang is, om false positives op te korte tekst te vermijden.
De kwantitatieve vangrails
Boven de twee lagen zitten twee prozaïscher maar noodzakelijke controles:
- Empty-content guard: als de provider een lege output terugstuurt terwijl
finish_reasonstopis, verwerpen we meteen alles (anders zouden we een leeg bestand schrijven dat als succes gemarkeerd is) - Sanity ratio: alleen als de bron minstens 500 tekens telt, controleren we of de output niet verdacht kort is (typisch <
max(50, source/20)). Dit is een detector voor onzichtbare truncatie, geen algemene lengteregel
Specifiek voor Claude is max_tokens in v1.9 van 4.096 naar 32.768 gegaan (de wijziging werd in de code door Claude gedaan nadat ik het symptoom had vastgesteld en vroeg om te onderzoeken). De gedocumenteerde reden in de CHANGELOG: latente truncatie vermijden op segmenten van 16k tekens, met extra marge voor talen met niet-Latijnse scripts (FR → JA, ZH, KO, AR, HI) die in output meer tokens verbruiken dan een equivalent Latijns script.
Terugkoppelingen via expliciete status
De bestands-pipeline (translate_markdown_file()) geeft voortaan een expliciete status terug — success, failure of skipped. De CLI aggregeert deze statussen en eindigt met een niet-nul exitcode zodra minstens één bestand is mislukt — wat de fout bruikbaar maakt voor een aanroepend script of voor de nieuwe CI die in v1.9 werd toegevoegd. Voor deze v1.9 werden meerdere fouten alleen geprint of gingen ze door als een geslaagde vertaling: het proces kon eindigen op 0 terwijl het bestand ontbrak, onvolledig was of slecht gevalideerd. De status skipped wordt zelf een leesbaar signaal (« bewust genegeerd »), verschillend van success (« vertaling correct weggeschreven »).
📄 Python-fragment: dubbele validatie na vertaling (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNieuwigheid 2: de vertaalnotitie op meerdere posities
De behoefte: een discrete maar informatieve notitie
Wanneer AI-Powered Markdown Translator een vertaling schrijft, voegt het een vertaalnotitie toe die het gebruikte model en de datum aangeeft. Voor v1.9 werd die notitie systematisch onderaan het bestand geplakt, in een geërfd (legacy) formaat met zichtbare scheidingstekens.
Het onderaan geplakte formaat leverde voor mijn eigen gebruik twee problemen op. Eerst werd de lezer pas helemaal op het einde geïnformeerd dat de inhoud door AI was vertaald — het is beter om daar meteen aan het begin voor te waarschuwen, dat zet de juiste verwachting op de inhoud. Vervolgens zette de voetnoot-notitie het vertaalsproject dat dit alles mogelijk maakt niet in de kijker: je leest het artikel, en de oorsprong van de meertalige stroom blijft onopgemerkt. Ik wilde dus de notitie bovenaan kunnen zetten en tegelijk de traceerbaarheid behouden — zonder bestaande usages te breken. v1.9 voegt twee flags toe die niets kapot maken:
--note_position {top,bottom,both}: boven, onder of beide--note_format {legacy,marker}: geërfd formaat of markerformaat (marker format)
Achterwaarts compatibele defaults: legacy + bottom. Geen enkele bestaande vertaalreeks verandert standaard van gedrag — de nieuwe flags worden expliciet geactiveerd op aanvraag.
Het markerformaat: een nette ingebedde GitHub-kaart (embed card)
Het markerformaat benut een subtiel detail van GitHub Markdown: ongebruikte link reference definitions zijn onzichtbaar in de rendering. Je kunt dus metadata (model, datum, bron) encoderen in een commentmarker bovenaan het bestand — onzichtbaar in de browser, maar bij kopiëren naar ruwe tekst onveranderd bewaard.
GitHub genereert bovendien een embed card wanneer je een link naar het vertaalde bestand deelt, en die kaart toont netjes de titel van het document zonder tekstuele vervuiling.
Ruw Markdown-voorbeeld met markerformaat op positie top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...Op het eerste gezicht ziet de lezer alleen de titel gevolgd door de inhoud. De marker vervuilt noch de HTML-rendering, noch de embedkaart.
De bewuste invoeging van de frontmatter (frontmatter-aware)
Technisch detail maar cruciaal: een notitie invoegen in top betekent niet « invoegen op regel 1 van het bestand ». Als het bestand een YAML-frontmatter heeft (wat voor deze blog het geval is), moeten we na de frontmatter invoegen — anders breekt de notitie de YAML.
Ik heb Claude de behoefte gegeven (« voeg de notitie na de frontmatter in, niet ervoor — anders breek je de YAML »), en hij heeft een helper _split_frontmatter gemaakt die de open/gesloten ----fences detecteert. Als het bestand een niet-afgesloten YAML-fence heeft (een misvormd geval), gooit de helper een RuntimeError in plaats van stilletjes een kapot bestand te produceren. De overgang van een monolithische functie naar 7 pure helpers (gescheiden en testbaar) is typisch iets wat goed begeleide pair-IA snel kan doen. Mijn rol hier: behoeftebegeleider, tester, eindklant die het resultaat valideert. Niet coderen. In dit project draag ik meerdere petten — behalve die van het schrijven van de code, en die komt toe aan Claude.
| Positie | Formaat | Typische gebruikssituatie |
|---|---|---|
top | marker | Blogartikelen (discrete notitie, nette embed card) |
top | legacy | Interne doc waar zichtbare traceerbaarheid belangrijk is |
bottom | marker | Open-source README (consistent met de footer) |
bottom | legacy | Standaardwaarden — backward compatible |
both | marker | Lange artikelen waar top + bottom geruststellen |
both | legacy | Legacy-geval met vereiste van dubbele traceerbaarheid |
📄 Python-uittreksel : helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")Nieuwigheid 3 : de --news-modus om broncitaten in het EN te behouden
Het probleem: vertalen zonder de citaten te breken
Wanneer ik ia-actualites-artikelen voor deze blog schrijf (dagelijkse/wekelijkse AI-nieuwsberichten uit meerdere bronnen), citeer ik regelmatig tweets, blogposts, releaseaankondigingen in het Engels — vaak meerdere per artikel. Als de vertaling de citaten raakt, worden ze onjuist.
Een vertaald citaat is een aangetast citaat. In alle taalversies (EN, DE, JA, enz.) willen we het originele Engels van de citaten behouden — dat is een eis van trouw aan de bronnen — vergezeld van de vlag van de doeltaal en een vertaling in cursief voor het leescomfort.
De oplossing: placeholders <NEWSQUOTE id="N"/>
| Stap | Actie |
|---|---|
| 1️⃣ | FR-bron-Markdown met EN-citaten als invoer |
| 2️⃣ | Voorverwerking: extractie van EN-citaten, vervanging door placeholders <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, enz. |
| 3️⃣ | API-vertaling (FR → target_lang) — de oorspronkelijke EN-citaten worden nooit naar het LLM gestuurd, alleen de placeholders wel (intact behouden) |
| 4️⃣ | Naverwerking: herstel van de placeholders met de oorspronkelijke EN-citaten intact + invoeging van de vlag van de doeltaal |
| 5️⃣ | Validatie na de vertaling: zijn alle placeholders hersteld? |
| ✅ | Doeluitvoer met behouden EN-citaten |
| ❌ | Mislukking als een placeholder niet is hersteld of een citaat is aangepast |
De --news-modus steunt op dit principe: een voorverwerking extraheert alle EN-citaten, vervangt ze door placeholders van het type <NEWSQUOTE id="0"/>, vertaalt de rest, en herstelt de placeholders intact.
De LANG_FLAGS-mapping past de vlag aan de target_lang aan (15 gedekte talen) : 🇬🇧 voor het Engels, 🇩🇪 voor het Duits, 🇪🇸 voor het Spaans, 🇮🇹 voor het Italiaans, 🇵🇹 voor het Portugees, 🇳🇱 voor het Nederlands, 🇵🇱 voor het Pools, 🇸🇪 voor het Zweeds, 🇷🇴 voor het Roemeens, 🇸🇦 voor het Arabisch, 🇮🇳 voor het Hindi, 🇯🇵 voor het Japans, 🇰🇷 voor het Koreaans, 🇨🇳 voor het Chinees, 🇫🇷 voor het Frans.
De validatie na de vertaling controleert dat alle placeholders intact zijn hersteld. De fout is niet een « EN-lek » — EN is gewenst — maar een niet-herstelde placeholder of een aangepast citaat.
Huidige gebruikssituaties en vooruitzichten
Vandaag gebruik ik --news uitsluitend op de ia-actualites-artikelen van de blog. Op termijn zou dat kunnen uitbreiden naar elk artikel dat Franse proza en EN-broncitaten combineert — interviews, ervaringsverslagen die Engelstalige onderzoeksartikelen citeren, transcripties van conferentiepresentaties.
Zonder de code te herlezen: waarom de vangrails dubbel moeten
« Ik lees de code niet. »
Ik herlees niets. Ik kijk soms snel naar een diff — dat gebeurt zelden, en alleen wanneer Claude ergens niet alleen uitkomt. Hier is de flow die ik dagelijks gebruik en die v1.9 heeft opgeleverd: Claude Code (uitsluitend Opus) tikt de code. Codex neemt het over wanneer Opus blokkeert of wanneer het gebruiksvenster vol raakt. GPT-5.5 in reasoning extra-high daagt de plannen uit vóór uitvoering. /pr-review-toolkit:review-pr herleest de PR vóór elke merge. Mijn rol stopt bij het valideren van de richtingen en het definiëren van de vangrails.
Deze ontwikkelmodus — volledig ontwikkeling-op-gevoel (vibe coding) — is geen gebrek aan nauwgezetheid. Het is een expliciet compromis: minder menselijke herlezing, meer geautomatiseerde validatie. De 3 v1.9-nieuwigheden die ik net heb voorgesteld, zijn allemaal in deze flow geproduceerd. En juist omdat we de code niet herlezen, moeten we de technische vangrails verdubbelen — niet weghalen.
Hier zijn de twee vangrails die zijn opgezet om deze ontwikkelmodus in productie werkbaar te maken: een geautomatiseerde kwaliteitsstack (Vangrail 1) en een AI-ondersteunde review in een multi-modelstroom (Vangrail 2).
Vangrail 1 : de geautomatiseerde kwaliteitsstack (14 hooks + praktische tests)
Overzicht
| Vangrail | Tools | Typische kost | Blokkerend bij mislukking |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hooks), detect-secrets, Lizard CCN | < 10 s | Ja |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Ja, behalve pip-audit in initiële reporting |
| externe CI | SonarCloud, Codacy, CodeFactor | parallel | Lokaal niet-blokkerend, PR-badges |
Cijfers v1.9 : 14 hooks, 229 tests unittest stdlib, ~98 % dekking op de nieuwe code v1.9, 11 badges SonarCloud, 3 externe platforms.
Pre-commit : de snelle vangrail
| # | Tool | Versie | Rol |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Shell-lint |
| 2 | ruff (lint) | 0.8.6 | Python-lint |
| 3 | ruff (format) | 0.8.6 | Python-opmaak |
| 4 | prettier | 3.1.0 | Opmaak van Markdown / JSON / YAML |
| 5 | trailing-whitespace | 5.0.0 | Verwijderen van spaties aan het einde van regels |
| 6 | end-of-file-fixer | 5.0.0 | Verplichte eindregel-newline |
| 7 | check-yaml | 5.0.0 | YAML-syntaxisvalidatie |
| 8 | check-toml | 5.0.0 | TOML-syntaxisvalidatie |
| 9 | check-added-large-files | 5.0.0 | Blokkeert per ongeluk toegevoegde grote binaire bestanden |
| 10 | check-merge-conflict | 5.0.0 | Detectie van Git-conflictsmarkers |
| 11 | check-executables-have-shebangs | 5.0.0 | Controleert dat uitvoerbare bestanden een shebang hebben |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Controleert dat scripts met shebang uitvoerbaar zijn |
| 13 | detect-secrets | 1.5.0 | Detectie van API-sleutels en secrets |
| 14 | check-complexity (Lizard) | local | Plafond voor cyclomatische complexiteit op de nieuwe code |
Totaal gemeten: ongeveer 2 tot 3 seconden over de hele repo (warm, pre-commit run --all-files getimed op ~2,4 s). Op een gemiddelde commit die slechts enkele bestanden raakt, is het nog sneller. De vuistregel die ik toepas: boven de 10 s gaan ontwikkelaars omzeilen (de pair-IA ook) — daarom moet deze snelle vangrail permanent behouden blijven.
Pre-push : de zware vangrail
- mypy in lakse modus : geen totale strictness (de historische code van translate.py zou niet slagen), maar een voortgangscontrole op de nieuwe code
- Opengrep SAST :
p/security-audit p/default p/python— ongeveer 30 seconden om injecties, eval en onveilige deserialisatie te scannen - pip-audit gewrapt door
scripts/check-pip-audit.sh: vangt de JSON-output op, classificeert aan shell-zijde transportfouten (netwerk, PyPI down) zodat kwetsbaarheid en onbeschikbaarheid niet worden verward, en rapporteert de kwetsbaarheden. In initiёle reporting-modus voor v1.9 (warn + exit 0) — later te verstrengen door te blokkeren na een PR voor het bumpen van verouderde afhankelijkheden. - unittest-discovery :
python -m unittest discoveroptests/en vervolgensscripts/tests/— 229 tests, ongeveer 8 seconden lokaal
Externe CI : SonarCloud + Codacy + CodeFactor
De workflow .github/workflows/sonarcloud.yml (project key jls42_ai-powered-markdown-translator) draait bij elke PR. 11 SonarCloud-badges op de README : Quality Gate, beveiligings-/betrouwbaarheids-/onderhoudbaarheidsscore, dekking, kwetsbaarheden, bugs, code smells, duplicaties, technische schuld, LOC.
Waarom de redundantie Codacy + SonarCloud + CodeFactor ? Omdat elk andere dingen ziet. Codacy bracht duplicaties naar voren die SonarCloud niet had gemeld. SonarCloud bracht signalen van slechte kwaliteit naar voren (de beruchte code smells) die Codacy liet passeren. CodeFactor bracht complexiteitsproblemen naar voren die de andere twee negeerden. Geen enkele alleen zou voldoende zijn geweest. De marginale kost van een extra platform is nul (gratis badge, 5 minuten integratie), dus vermenigvuldigen we de invalshoeken.
Tests : unittest stdlib (geen pytest)
229 tests, 0 regressie over de 6 maanden van de PR, ~98 % dekking op de nieuwe code v1.9.
Typische verdeling:
test_silent_failure.py: 97 tests gericht op de dubbele validatietest_orchestration.py: 79 tests op de orchestrator-pipelinetest_translation_note_position.py: 38 tests op de positie × formaat-matrixtest_audit_verdict.py: 15 tests op de pip-audit-wrapper (inscripts/tests/)
Eerlijke noot : de ~98 % dekking slaat op de nieuwe code v1.9 — niet op de historische totaliteit van translate.py, die nog enkele geërfde functies bevat die door de nieuwe testset weinig worden gedekt. Ik vermeld dit expliciet omdat « 98 % dekking » over een volledig project zou misleidend zijn.
Betwistbare maar bewuste keuze : test-runner unittest (stdlib), geen pytest. Het test_-prefix is uit gewoonte, maar het is unittest dat runt. Waarom ? In een vibe coding-project geldt : elke toegevoegde afhankelijkheid = elke afhankelijkheid die de AI verkeerd kan gebruiken. Eenvoud is een doel. unittest zit in de standaardbibliotheek van Python, nul installatie, nul plugin.
Praktische tests : multi-repo + intern productgebruik (dogfooding) + controle van de visuele weergave
De 229 unittest-tests zijn niet genoeg. Ik voeg drie lagen praktische tests toe:
1. Multi-repo — het script testen op meerdere publieke repos met README’s in verschillende formaten. Dat onthult randgevallen die de fixtures niet afdekken — een README met 8 heading-niveaus, een andere met geërfde shortcodes, een derde met exotische ingebedde code. In deze fase werd het silent-failure-incident van Nieuwigheid 1 ontdekt.
2. Dogfooding op de blog — jls42.org wordt door het script zelf vertaald. Elk gepubliceerd artikel is een live test in productie. Als een randgeval door de unit-tests glipt, komt het hier uit, op de pagina die je leest. Dat is de ultieme test — wat online staat, is wat het project heeft geproduceerd.
3. Test van de visuele weergave — ik controleer dat de weergegeven vertalingen correct worden getoond, ofwel in de browser (eindwebpagina), of rechtstreeks in VSCode via een Markdown-previewplugin. Het idee: niet tevreden zijn met alleen syntactisch geldige Markdown, maar de echte render zien. Visuele renders brengen uiterlijke bugs aan het licht (kapotte tabellen, misvormde code blocks, verkeerd geïnterpreteerde frontmatter) die teksttests niet zien.
De AI’s nemen ook aan deze tests deel. /pr-review-toolkit voert de code uit in een testomgeving, en het gebruik in pair-IA omvat systematisch visuele validatierondes (« controleer dat de Duitse vertaling van pagina X goed wordt weergegeven »).
📄 Uittreksel .pre-commit-config.yaml (belangrijkste pre-commit-hooks)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Uittreksel scripts/check-security-sast.sh
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Uittreksel .github/workflows/sonarcloud.yml
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Vangrail 2 : AI-ondersteunde review + de multi-modelstroom
Terminologische precisie : wanneer ik in deze sectie over Claude Opus spreek, bedoel ik het model dat ik gebruik om v1.9 te ontwikkelen — niet het model dat AI-Powered Markdown Translator gebruikt om te vertalen. Het project zelf ondersteunt 4 providers (OpenAI, Mistral AI, Claude, Gemini) en elk model (Sonnet, Haiku, Mistral Large, Gemini 3 Pro, enz.). Aan ontwikkelingszijde vergrendel ik op Opus. Aan uitvoeringszijde blijft het project agnostisch.
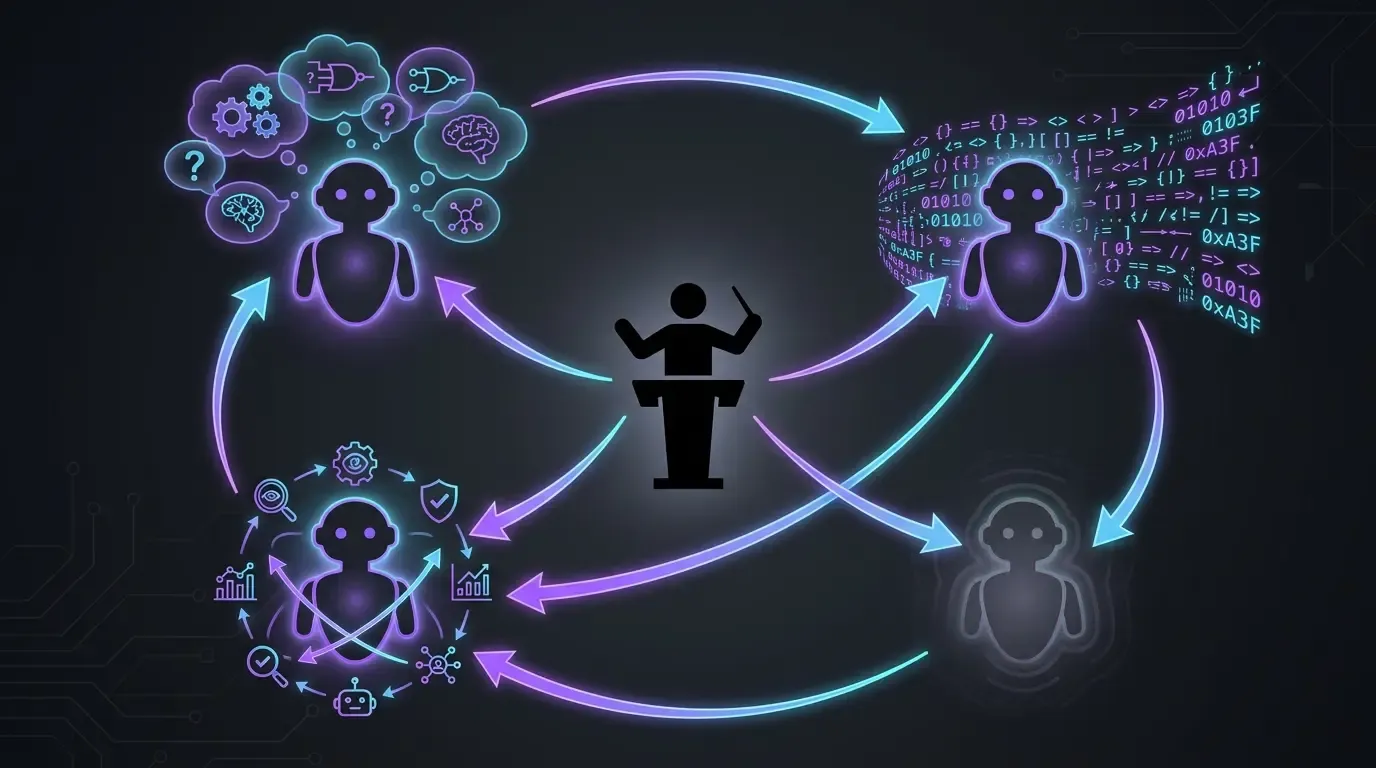
Het echte werkproces: 4 modellen, 4 rollen (om te ontwikkelen)
- Claude Code in Opus, uitsluitend (anthropic) : hoofduitvoering. Leest de context, schrijft de code, past de correcties toe. Geen Sonnet, geen Haiku, geen fast mode. Op dit project wil ik elke keer het topmodel — het idee is simpel: we zorgen ervoor dat we altijd het beste hebben om naar het best mogelijke resultaat te streven.
- OpenAI Codex als fallback (fallback) : gebruikt in twee specifieke gevallen :
- Wanneer Opus op een onderwerp vastloopt (zeldzaam maar bestaand — bijvoorbeeld bij correcties die externe agents zoals Codacy of SonarCloud vragen, convergeert Claude soms niet en verplaats ik het onderwerp naar Codex om het te deblokkeren)
- Wanneer het Anthropic-gebruiksvenster verzadigd is. Codex maakt het mogelijk om het momentum niet te verliezen terwijl we wachten op de quota-reset.
- GPT-5.5 reasoning extra-high (
xhigh) : daagt plannen vóór uitvoering uit. Voordat ik Claude Code op een onderwerp loslaat, leg ik het plan voor aan GPT-5.5 in reasoning extra-high. Hij stelt de juiste vragen, legt de blinde vlekken bloot. Zo voorkom je dat je in de verkeerde richting vertrekt die je later moet rechtzetten. /pr-review-toolkit:review-pr(skill-plugin van Claude Code) : review vóór merge met gespecialiseerde agents (beveiliging, kwaliteit, tests, commentaar, typeontwerp). De skill draait op de PR voordat ik merge — het is de laatste AI-lijn voor de code inmainterechtkomt.
Geen van deze modellen volstaat op zichzelf. Elk speelt een andere rol — de topklasse-uitvoerder, de capaciteitsvervanger, de uitdager van plannen, de veelzijdige reviewer.
/pr-review-toolkit : wat ik niet zou hebben gezien
Alles. Ik kijk niet naar de code. De skill haalt alles naar boven — verborgen bugs, beveiligingsproblemen, inconsistenties in tests, tests die slagen maar niets testen.
Op PR #2 (75 commits, 9 837 toevoegingen, 1 982 verwijderingen, 58 bestanden) zou een mens alleen uit vermoeidheid 80 % van de PR overslaan. De skill slaat niets over. Hij leest elke diff, elke test, elke opmerking. En vooral: hij daagt uit — hij weigert de patronen die hij als slecht herkent, en stelt alternatieven voor.
De mens als dirigent, niet als muzikant
Mijn rol bestrijkt de hele keten — behalve het schrijven van de code. Ik draag de petten van productmanager (nadenken over features, prioriteren, afwegen), QA (testen op echte gevallen, de weergave visueel valideren), tech lead (plannen uitdagen met GPT-5.5 reasoning extra-high), eindklant (het resultaat beoordelen op mijn eigen dagelijkse gebruikservaring op de blog). De enige rol die ik niet opneem, is die van coder. De rest ben ik.
Ik ben producent geworden, niet muzikant.
Ten dienste van de blog: hij vertaalt zichzelf (bijna 1.800 vertalingen)
AI-Powered Markdown Translator genereert zijn eigen README in 14 talen, en het is hij die alle buitenlandse versies van de inhoud van jls42.org produceert. Concreet: bijna 1.800 vertaalde versies voeden de blog (25 artikelen + 4 projecten + 98 AI-nieuwsitems × 14 talen, zonder FR-bronnen — dus 1 778 versies op het moment dat ik dit schrijf). Elke pagina die u hier in een andere taal dan het Frans bekijkt, is via dit project gegaan.
Dat is intern productgebruik (dogfooding) tot het uiterste doorgetrokken — en het zet de vertaling van het artikel dat over vertaling gaat onder druk. Als wat u leest in ar, hi of ko consistent is, dan houdt het vangnet van Nieuwigheid 1 (validatie na vertaling) stand ; als de vertaalnotitie correct bovenaan verschijnt, dan werkt Nieuwigheid 2 (notitie op meerdere posities) ; als de EN-citaten bewaard blijven in de taalversies, dan werkt Nieuwigheid 3 (modus --news) ook.
Conclusie: rigoureuze AI-pairing, geen slordige AI-pairing
Ontwikkelen op gevoel heeft om goede redenen een slechte reputatie. Het is juist daartegen dat ik werk. Vier concrete lessen komen uit deze v1.9 naar voren:
-
Stilzwijgende mislukkingen zijn vijand nummer één. De AI produceert code die OK lijkt en door de unit tests glipt. Systematische validatie aan de client-kant. En een andere AI gebruiken om de echte productie te herlezen, niet alleen de code.
-
Pre-commit hooks < 10 s anders worden ze omzeild ; pre-push kunnen 30 s+ duren. De AI voegt graag tools toe zonder rekening te houden met hun kostprijs. Handmatig afbakenen, hetzij in het plan, hetzij achteraf — het belangrijkste is dat de hooks uiteindelijk goed zijn ingesteld en dagelijks ook echt worden gebruikt.
-
Dekking zonder sterke assertie = theater. De AI kan 200 tests genereren die slagen en niets testen. unittest + precieze asserties > pytest met een heleboel mocks. Controleer de geretourneerde waarde, niet alleen dat de code niet is gecrasht.
-
AI-PR-review is geen optie. Wanneer de menselijke auteur niet heeft nagelezen, is de AI-reviewer geen franje — het is het uitbestede oog.
Goed uitgevoerde vibe coding betekent ook accepteren dat je de code niet leest en de kritische lezing delegeren aan andere IAs die dat echt doen.
Wat dit project onthult
Deze v1.9 illustreert verschillende aspecten van hoe ik werk:
- De menselijke rol bestrijkt de hele keten behalve de code : product (nadenken over features, prioriteren), QA (testen op echte gevallen, visueel valideren), tech lead (plannen uitdagen met een LLM in reasoning extra-high), eindklant (beoordelen op echt gebruik). De enige rol die ik niet opneem, is coder.
- Vangnetten verdubbelen, niet verwijderen : minder menselijke review = meer geautomatiseerde validatie. Bewuste afweging, geen gebrek aan rigueur. Als ik de herlezing weglaat, moet ik de vangnetten verdubbelen, niet blind op de AI vertrouwen.
- AI om de bugs van AI te ontdekken : de stilzwijgende fout is gevonden door Claude tijdens de praktische multi-repo-tests. Volledige delegatie: we kunnen ook de kritische review delegeren.
- AI-pairing als vermenigvuldiger op persoonlijke tijd : ik draag dit project op mijn avonden en weekends. Zonder AI-pairing zou ik duidelijk niet zo ver of zo snel komen. Met AI-pairing kan ik een open-sourceproject op industrieel niveau onderhouden naast mijn andere verplichtingen. Dat is wat vibe coding mogelijk maakt — niet de ontwikkelaar vervangen, maar hem in staat stellen te doen wat hij alleen niet zou kunnen.
- Itereren in plaats van alles opnieuw doen : 9 versies, incrementele refactoring (1 functie → 7 helpers), achterwaartse compatibiliteit behouden. AI-pairing helpt snel itereren zonder alles te herschrijven.
Bronnen
- AI-Powered Markdown Translator op GitHub
- Uitgave v1.9
- PR #2 — 75 commits, migratie + kwaliteit
- Volledige CHANGELOG
- Projectpagina op deze blog
- Artikel 2024 — v1.5 (release-notes-stijl) — om de toon te vergelijken
- Diepe duik AWS-diagram — ander artikel uit de reeks
Als u AI-Powered Markdown Translator op uw eigen Markdown wilt uitproberen — open-source README, blogartikelen, technische documentatie —, de code staat op GitHub. Installatie in een paar minuten, 4 ondersteunde providers, modus --eco om de kosten te verlagen, modus --news om de broncitaten te behouden, en inmiddels een kwaliteitsstack v1.9 die u als template kunt hergebruiken voor uw eigen projecten in AI-pairing.
Als u uw persoonlijke projecten ontwikkelt met gevoel (vibe coding), ga dan op het vlak van kwaliteit niet voor de simpelste optie. Betrouwbaarheid is de prijs van snelheid — neem beide samen aan.