ai-powered-markdown-translatorfr から ja へ gpt-5.4-mini で翻訳された記事。
AI-Powered Markdown Translator は、私が2024年から保守しているオープンソースプロジェクトです。OpenAI、Mistral AI、Claude、Geminiの4つのAIプロバイダーを通じて、任意のMarkdownファイルを14言語に翻訳するPythonスクリプトです。これは公開のたびにこのブログを支えており、ここで読むフランス語以外のページのほぼすべてはこれを通っています。さらに、本番環境では約1,800件の翻訳版がこれによって動いています。
2026年5月8日、私はv1.9を公開しました。これは75コミットをまとめたもので、2024年のv1.5以来の最大の更新です。製品面では3つの新機能があります。
- 翻訳後バリデーション(静かに失敗するのを防ぐ)
- マルチ位置の翻訳ノート(上、下、または両方)
--newsモード(ENソースの引用を保持するため)
ただし、このv1.9には、ここでぜひ共有したい特別な点があります。コードはすべてペアAIで書かれたということです。手で打った1行もありません。なので、3つの新機能に加えて、この記事では「どのようにして」きれいで安全なコードを目指すのか、つまりAIが生成したものを自分で読み返さないときに、どんなガードレールを置くのかを扱います。
文脈:日常的に使われているが、コード面の保守はあまり進んでいなかったプロジェクト
2024年9月から2026年5月まで:継続利用、コード保守は断続的
私は2024年のv1.5のソースコードを詳しく説明した記事を書いていました。当時は、スクリプト自体を記事に直接掲載していました。今では視点が変わっています。大事なのは、私が書くコードそのものではなく、それを生み出すワークフローです。
2024年9月に公開されたv1.5から2026年1月まで、このプロジェクトは動き続けていました。新しいこのブログのコンテンツはすべて翻訳されていたからです。ただし、公開コードはほとんど変わっていませんでした。2025年にプッシュされたコミットは1つだけでした。その間も、私は自分の用途のためにローカルでコードを進化させていました。特にモデルは、出てくるたびに置き換えていました。しかし、その変更は自分のマシンの中に留まっていました。GitLab上の公開版は、v1.5のデフォルト値を指し続けていたのです。
2026年の初めに、私は最初の追いつき作業をしました。2か月で3回のリリース(1月初めにv1.6とv1.7を2日違いで、3月にv1.8)で、機能面ではプロジェクトを最新化しました。2026年のモデル、Gemini対応、--eco モード、単一ファイル、引用ソース用の --news モードです。しかし、CIも自動テストも品質ゲートもないままでした。これは、私の代わりにコードを書くAIエージェントをさらに前に進めるうえで、実際に問題でした。
余暇で進めるプロジェクトのペース
なぜここまで遅れていたのか。理由は、このプロジェクトを余暇で回しているからです。家族がいて、画面の外の生活もあるので、進捗は空いた夜や週末に少しずつしか進みません。私は熱意を持って取り組んでいますし、このテーマにはかなりの時間を使っています。たくさん試し、エージェントを導き、結果を検証しています。それでも、ペースは仕事のプロジェクトのようにはいきません。
ペアAIはまさにそこを変えてくれます。熱意と、画面外の生活との配分という2つの制約のあいだで前に進めるのです。ペアAIがなければ、私は明らかにここまで、そしてこんなに速く進めません。あれば、人生をそれに捧げることなく、産業レベルのオープンソースプロジェクトを維持できます。
当初の目的:品質向上 + GitLab → GitHub 移行
2026年4月中旬、私はついに本腰を入れようと決めました。目的は2つだけです。
- 品質レイヤーを追加する(静的解析、テスト、CI)
- リポジトリをGitLabからGitHubへ移行する
それだけのはずでした。ですが、ペアAIのコードエージェントを使うと、予定どおりには終わりません。PRは最終的に75コミット、9,837追加、1,982削除、58ファイルになりました。
| バージョン | 日付 | 主な内容 |
|---|---|---|
| 1.0–1.4 | 2024年 | OpenAI、次にMistral、次にClaude |
| 1.5 | 2024年9月 | クライアントのリファクタリング、2024年モデル(gpt-4o、claude-3.5-sonnet) |
| 1.6 | 2026年1月 | 2026年モデル(gpt-5、claude-sonnet-4-5、gemini-3-pro)、Gemini、--eco モード、単一ファイル(--file) |
| 1.7 | 2026年1月 | --keep_filename、.env、インラインコードの保持 |
| 1.8 | 2026年3月 | GPT-5.4モデルをデフォルトに、引用プレースホルダー付きの --news モード |
| 1.9 | 2026年5月 | 翻訳後バリデーション、マルチ位置ノート、14フック + 229テスト + AIレビューの品質スタック |
雪だるま式の効果
品質ツールを1つ追加するたびに、別の問題が見つかりました。Codacyは重複を指摘しました。SonarCloudは code smells(将来的に劣化しやすいコードの兆候。たとえば、長すぎる関数、使われていない引数、複雑すぎる構造)を挙げました。/pr-review-toolkit は潜在的なバグを指摘しました。指摘が出るたびに、エージェントが修正し、ときには周辺の箇所まで改善していました。
スコープは自然に爆発的に広がりました。これは私が望んでいたことそのもので、つまりプロジェクトの近代化です。ただし、作業量の配分は私ではなくツールが決めていました。バイブコーディングのプロジェクトにおいて、これは重要な点です。品質ツールは、仕事を検証するのと同じくらい、仕事の方向性も決めるのです。
新機能1:翻訳後バリデーション(静かに失敗するのを防ぐ)
事件:テスト中にバグを見つけたのはAIだった
複数の公開リポジトリのREADMEでPRをテストしていたとき、つまりどのfixtureでもカバーしていなかったケースで、AIが私の見落としを指摘しました。いくつかの言語、とくにヒンディー語(ISOコード hi)では、翻訳の途中にソース言語のまま残る箇所があったのです。APIは 200 を返し、スクリプトはファイルを書き出しましたが、内容は半分しか翻訳されていませんでした。そして、それは既存のユニットテスト群をすり抜けていました。あのテスト群は、この実際の多言語ケースをカバーしていなかったのです。
まさに、バイブコーディングが生み出しうる、誰にも見えない種類のバグです。コードは論理的に見え、テストfixtureはケースをカバーしておらず、人間は結果を読み返さない。ところが今回、実際のケース(マルチリポジトリ)でスクリプトをテストしたことで、AI自身がfixtureでは拾えないものを見つけたのです。
私が学んだのはこうです。実践的なマルチリポジトリテストは、ユニットテストが取りこぼすものを見つけます。そしてAIは、前任のAIエージェントのバグを見つけるためにも使えます。ただし、さまざまな実ケースに向き合わせる必要があります。
このとき私は、ちゃんとした翻訳後バリデーションを追加すべきだと理解しました。ここから、2層のバリデーションについて説明します。
2層のバリデーション
| ステップ | アクション | NGだった場合 |
|---|---|---|
| 1️⃣ | API call provider | ネットワーク例外 → ❌ failure |
| 2️⃣ | finish_reason の provider 別ホワイトリスト(Claudeでは stop_reason) | ホワイトリスト外 → ❌ failure |
| 3️⃣ | 漏れ防止:ソース文から120文字以上の窓が出力内に verbatim で存在しないこと | ソース窓が見つかる → ❌ failure |
| 4️⃣ | langdetect.detect_langs(source と target の確率) | source > 0,80 かつ target < 0,20 → ❌ failure |
| 5️⃣ | Empty-content + 出力/ソース比率(source が 500文字以上の場合) | 空、または出力 < max(50, source/20) → ❌ failure |
| ✅ | SUCCESS | exit code 0 |
レイヤー1(決定論的) — まず最初の防波堤は、APIが返すステータスを確認することです。各プロバイダーは、LLMが生成を止めた理由を示す finish_reason フィールド(Claudeでは stop_reason)を持っています。スクリプトは、許容されるステータスのprovider別ホワイトリストを維持しています。命名はプロバイダーごとに異なります(OpenAI/Mistralでは stop、Geminiでは STOP または FINISH_REASON_STOP、Claudeでは end_turn または stop_sequence)。SDKがこのフィールドを返さない場合に備えて、None も安全側で許容します。それ以外のステータス、たとえばプロバイダーによって length、max_tokens、または MAX_TOKENS のような、トークン上限で応答が止まったことを示すものは、復旧を試みずに即座に RuntimeError を引き起こします。
もう1つの決定論的な防波堤は、ソーステキストのどの部分も翻訳結果に verbatim で現れていないことを確認することです。具体的には、ソース文から120文字以上の窓を切り出し、その窓のいずれかが出力にそのまま見つかれば、それは翻訳されていないということです。failure です。まさにこのチェックがヒンディー語のケースを拾いました。LLMは stop を返していたため、API側では「自然な」終了でしたが、フランス語の段落が出力にそのまま残っていました。finish_reason の防波堤では見えず、verbatim漏れ防止の防波堤で検出されたのです。
レイヤー2(確率的) — langdetect.detect_langs は出力の言語を解析し、複数の候補言語に対する確率分布を返します。ソース言語とターゲット言語の確率を取り出し、source の確率が 0,80 を超え、かつ target が 0,20 を下回る場合にのみ拒否します。これは、技術的なコードスイッチング(たとえばフランス語訳の中に正当な英単語が混ざるケース)で誤検出しないための、意図的に保守的な閾値です。この層は、非ラテン文字の言語(ヒンディー語 hi、アラビア語 ar、中国語 zh、日本語 ja、韓国語 ko)ではショートカットされます。そこでは十分な文字種シグナルだけで出力を有効とみなせるからです。そして、この層は、誤検出を避けるために、クリーンアップ後の出力が少なくとも100文字ある場合にのみ動作します。
定量的なガードレール
この2層の上に、さらに2つのもっと素朴ですが必要なチェックがあります。
- Empty-content guard:
finish_reasonがstopのときにプロバイダーが空の出力を返したら、即座に拒否する(そうしないと、success と印が付いた空ファイルを書き出してしまう) - Sanity ratio:ソースが少なくとも500文字ある場合にだけ、出力が疑わしいほど短くないかを確認する(典型的には <
max(50, source/20))。これは一般的な長さのルールではなく、見えない切り詰めを検出するためのものです
Claudeに関しては、max_tokens がv1.9で4,096から32,768に引き上げられました(この変更は、私が症状を確認して調査を依頼した後、Claude側でコード修正として行われました)。CHANGELOGに記録された理由は、16k文字のセグメントで起こりうる潜在的な切り詰めを避けるためです。さらに、非ラテン文字スクリプトの言語(FR → JA、ZH、KO、AR、HI)では、同等のラテン文字スクリプトよりも出力で多くのトークンを消費するため、その分の余裕も必要でした。
明示的なステータス返却
ファイル単位のパイプライン(translate_markdown_file())は、今では明示的なステータスを返します。success、failure、または skipped です。CLIはこれらのステータスを集約し、少なくとも1ファイルでも失敗したら非0の終了コードで終わります。これにより、呼び出し元のスクリプトや、v1.9で追加された新しいCIから失敗を扱えるようになりました。v1.9以前は、いくつかのエラーは単に表示されるだけで、あるいは翻訳成功として通っていました。プロセスは 0 で終わっても、ファイルが存在しない、未完了、または誤って検証されていることがありました。skipped ステータス自体が、今では読みやすいシグナル(「意図的にスキップされた」)になっており、success(「翻訳が正しく書き込まれた」)とは区別されています。
📄 Python抜粋:翻訳後の2重バリデーション(translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejette新機能2:マルチ位置の翻訳ノート
目的:控えめだが情報量のあるノート
AI-Powered Markdown Translator が翻訳を書き出すとき、使用したモデルと日付を示す翻訳ノートを追加します。v1.9以前は、このノートは常にファイルの末尾に固定され、目に見える区切り線を持つレガシー形式でした。
末尾に固定する形式には、私自身の使い方では2つの問題がありました。まず、コンテンツがAIによって翻訳されたことを、読者が最後まで読まないと知れない点です。最初に知らせたほうがよく、内容への期待値も正しく設定できます。次に、脚注のようなノートは、こうした翻訳を可能にしている翻訳プロジェクト自体を際立たせません。記事を読むと、マルチリンガルな流れの出どころが目立たないのです。そこで私は、既存の使い方を壊さずに、トレーサビリティを保ったままノートを上部へ移せるようにしたかったのです。v1.9では、互換性を壊さない2つのフラグが追加されました。
--note_position {top,bottom,both}: 上、下、または両方--note_format {legacy,marker}: レガシー形式またはマーカーフォーマット(marker format)
後方互換のデフォルト:legacy + bottom。既存の翻訳ストリングの既定の挙動は一切変わりません。新しいフラグは必要なときだけ明示的に有効化します。
マーカーフォーマット:きれいなGitHub埋め込みカード(embed card)
マーカーフォーマットは、GitHub Markdownの繊細な仕組みを利用しています。つまり、未使用の link reference definitions はレンダリングで見えないのです。そこで、メタデータ(モデル、日付、ソース)をファイル上部のコメントマーカーとして埋め込めます。ブラウザ上では見えませんが、プレーンテキストとしてコピーしてもそのまま保持されます。
さらにGitHubは、翻訳ファイルへのリンクを共有したときに埋め込みカード(embed card)を生成し、そのカードにはテキストノイズなしで文書タイトルがきちんと表示されます。
top の位置にあるマーカーフォーマットの生Markdown例:
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...見た目上、読者にはタイトルとその後の本文しか見えません。マーカーはHTMLレンダリングもembedカードも汚しません。
frontmatter を意識した挿入(frontmatter-aware)
技術的だが極めて重要な点:top にノートを挿入することは、「ファイルの1行目に挿入する」ことを意味しません。このファイルのように frontmatter YAML がある場合は、frontmatter の後に挿入しなければなりません。さもないと、そのノートが YAML を壊してしまいます。
私は Claude に要件を伝えました(「ノートは frontmatter の後に挿入して、前には入れないで。さもないと YAML を壊すから」)。すると、オープン/クローズの --- を検出する _split_frontmatter ヘルパーが出てきました。ファイルにクローズされていない YAML fence がある場合(不正形式のケース)、そのヘルパーは黙って壊れたファイルを生成する代わりに RuntimeError を投げます。単一の巨大な関数を、分離されテスト可能な 7 個の純粋なヘルパーへ分割するのは、うまく誘導された pair-IA が素早くやり遂げる典型例です。ここでの私の役割は、要件のガイド、テスター、結果を承認する最終クライアントです。コードは書きません。このプロジェクトでは私はいくつもの役割を担っていますが、コードを書く役割だけは Claude の担当です。
| 位置 | 形式 | 典型的なユースケース |
|---|---|---|
top | marker | ブログ記事(さりげないノート、整った embed card) |
top | legacy | 可視的なトレーサビリティが重要な社内ドキュメント |
bottom | marker | フッターと整合するオープンソース README |
bottom | legacy | 後方互換なデフォルト |
both | marker | トップとボトムの両方が安心材料になる長文記事 |
both | legacy | 二重トレーサビリティが求められるレガシーケース |
📄 Python 抜粋 : _split_frontmatter ヘルパー (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")新機能 3: ソース EN の引用を保持するための --news モード
問題: 引用を壊さずに翻訳する
このブログ向けに ia-actualites 記事(複数ソースの AI ニュースを毎日/毎週まとめたもの)を書くとき、私は英語のツイート、ブログ投稿、リリース告知を頻繁に引用します。1 記事あたり複数回になることも珍しくありません。翻訳が引用に触れてしまうと、それらは誤ってしまいます。
翻訳された引用は、改変された引用です。どの言語版(EN、DE、JA など)でも、引用の英語原文をそのまま維持することを望みます。これはソースへの忠実性の要件です。そのうえで、読みやすさのためにターゲット言語の旗と、イタリック体の訳文を添えます。
解決策: <NEWSQUOTE id="N"/> プレースホルダー
| ステップ | アクション |
|---|---|
| 1️⃣ | 入力として、引用を含む FR の Markdown ソース |
| 2️⃣ | 前処理: EN 引用を抽出し、<NEWSQUOTE id="0"/>、<NEWSQUOTE id="1"/> などのプレースホルダーに置換 |
| 3️⃣ | API 翻訳(FR → target_lang) — 元の EN 引用は LLM に一切送られず、プレースホルダーだけが送られる(そのまま保持) |
| 4️⃣ | 後処理: プレースホルダーを、元の EN 引用を損なわずに復元し、ターゲット言語の旗を挿入 |
| 5️⃣ | 翻訳後の検証: すべてのプレースホルダーは復元されたか? |
| ✅ | EN の引用を保持したままのターゲット出力 |
| ❌ | プレースホルダー未復元、または引用が改変された場合は失敗 |
--news モードはこの原則に基づいています。前処理で EN の引用をすべて抽出し、<NEWSQUOTE id="0"/> 型のプレースホルダーに置き換え、残りを翻訳し、プレースホルダーをそのまま復元します。
LANG_FLAGS マッピングは target_lang(15 言語対応)に応じて旗を調整します: 🇬🇧 は英語、🇩🇪 はドイツ語、🇪🇸 はスペイン語、🇮🇹 はイタリア語、🇵🇹 はポルトガル語、🇳🇱 はオランダ語、🇵🇱 はポーランド語、🇸🇪 はスウェーデン語、🇷🇴 はルーマニア語、🇸🇦 はアラビア語、🇮🇳 はヒンディー語、🇯🇵 は日本語、🇰🇷 は韓国語、🇨🇳 は中国語、🇫🇷 はフランス語です。
翻訳後の検証では、すべてのプレースホルダーが損なわれずに復元されているかを確認します。エラーは「EN の漏れ」ではありません。EN は意図したものです。問題は プレースホルダー未復元 か 引用の改変 です。
現在のユースケースと今後の展望
現在、私は --news をブログの ia-actualites 記事にのみ使っています。将来的には、フランス語の本文と EN のソース引用が混在するあらゆる記事に広げられるかもしれません。たとえば、インタビュー、英語の研究論文を引用する実務経験談、カンファレンス発表の書き起こしなどです。
コードを再読しない前提で: なぜ安全装置を二重化する必要があるのか
「私はコードを読みません。」
私は何も再読しません。たまに diff をざっと見ることはありますが、それも稀です。Claude がひとりではうまくいかないポイントがあるときだけです。ここに、私が日々使っていて v1.9 を生み出した流れを示します。Claude Code(Opus 専用)がコードを書く。Opus が詰まるか使用枠がいっぱいになると Codex が引き継ぐ。GPT-5.5 の reasoning extra-high が実行前に計画を挑む。/pr-review-toolkit:review-pr は各 merge の前に PR を再読する。私の役割は、方向性の承認と安全装置の定義までです。
この開発モード — 完全な感覚主導開発(vibe coding)— は、規律がないことを意味しません。これは明確なトレードオフです。人間による再読を減らし、ツールによる検証を増やす。私が先ほど紹介した v1.9 の 3 つの新機能は、すべてこの流れで作られました。そして、まさにコードを再読しないからこそ、技術的な安全装置を二重化しなければなりません。削るのではなく、増やすのです。
この開発モードを本番で成立させるために用意した 2 つの安全装置があります。自動化された品質スタック(安全装置 1)と、マルチモデル流の AI 支援レビュー(安全装置 2)です。
安全装置 1: 自動化された品質スタック(14 hook + 実践テスト)
概要
| ネット | ツール | 典型コスト | 失敗時にブロック |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks(8 sub-hook), detect-secrets, Lizard CCN | < 10 s | はい |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | はい、ただし pip-audit の初回レポートは除く |
| 外部 CI | SonarCloud, Codacy, CodeFactor | 並列 | ローカルではブロックしない、PR バッジ |
v1.9 の数値: 14 hook、229 tests の unittest stdlib、約 98 % のカバレッジ(v1.9 の新規コード対象)、11 個の SonarCloud バッジ、3 つの外部プラットフォーム。
Pre-commit: 速いネット
| # | ツール | バージョン | 役割 |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | shell の lint |
| 2 | ruff (lint) | 0.8.6 | Python の lint |
| 3 | ruff (format) | 0.8.6 | Python の整形 |
| 4 | prettier | 3.1.0 | Markdown / JSON / YAML の整形 |
| 5 | trailing-whitespace | 5.0.0 | 行末スペースの削除 |
| 6 | end-of-file-fixer | 5.0.0 | ファイル末尾の newline を必須化 |
| 7 | check-yaml | 5.0.0 | YAML 構文の検証 |
| 8 | check-toml | 5.0.0 | TOML 構文の検証 |
| 9 | check-added-large-files | 5.0.0 | うっかり追加された巨大バイナリをブロック |
| 10 | check-merge-conflict | 5.0.0 | Git コンフリクトマーカーの検出 |
| 11 | check-executables-have-shebangs | 5.0.0 | 実行ファイルに shebang があるか確認 |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | shebang 付きスクリプトが実行可能か確認 |
| 13 | detect-secrets | 1.5.0 | API キーとシークレットの検出 |
| 14 | check-complexity (Lizard) | local | 新規コードの循環的複雑度の上限 |
実測の合計: リポジトリ全体で 約 2〜3 秒(ウォーム状態、pre-commit run --all-files では約 2.4 s を計測)。数ファイルしか触らない平均的なコミットでは、さらに速くなります。私が適用している経験則はこうです。10 秒を超えると、開発者は回避します(pair-IA も同じです)— だからこそ、この速いネットは常時維持しなければなりません。
Pre-push: 重いネット
- mypy は緩めのモード: 全体 strict ではない(translate.py の歴史的コードが通らないため)が、新規コードの進捗チェックは行う
- Opengrep SAST:
p/security-audit p/default p/python— インジェクション、eval、安全でないデシリアライズをスキャンするのに約 30 秒 - pip-audit は
scripts/check-pip-audit.shでラップ: JSON 出力を取得し、ネットワークや PyPI ダウンなどの輸送系エラーを shell 側で分類して脆弱性と可用性問題を混同しないようにし、脆弱性を報告する。v1.9 では 初回レポートモード(warn + exit 0)。依存関係の陳腐化に対する bump PR の後で、ブロッキングに強化する予定。 - unittest discovery:
python -m unittest discoverをtests/で実行し、その後scripts/tests/— 229 tests、ローカルで約 8 秒
外部 CI: SonarCloud + Codacy + CodeFactor
ワークフロー .github/workflows/sonarcloud.yml(project key jls42_ai-powered-markdown-translator)は各 PR で実行されます。README には 11 個の SonarCloud バッジが表示されています: Quality Gate, Security/Reliability/Maintainability Rating, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC。
なぜ Codacy + SonarCloud + CodeFactor を重ねるのか? それは、それぞれが違うものを見るからです。Codacy は SonarCloud が指摘しなかった重複を拾いました。SonarCloud は Codacy が見逃した品質不良のシグナル(いわゆる code smells)を拾いました。CodeFactor は、他の 2 つが無視した複雑度の問題を拾いました。1 つだけでは十分ではありません。追加のプラットフォーム 1 つあたりの限界コストはゼロです(無料バッジ、5 分の統合)から、視点を増やします。
テスト: unittest stdlib(pytest ではない)
229 tests、PR の 6 か月間でリグレッション 0、v1.9 の新規コードで約 98 % のカバレッジ。
典型的な内訳:
test_silent_failure.py: 二重検証を狙った 97 teststest_orchestration.py: オーケストレーターパイプラインで 79 teststest_translation_note_position.py: position × format マトリクスで 38 teststest_audit_verdict.py: pip-audit ラッパーで 15 tests(scripts/tests/内)
正直な注記: 約 98 % のカバレッジは v1.9 の新規コードに対するものです。translate.py 全体ではなく、そこには今でも新しいテスト群で十分に覆われていない、継承された関数がいくつか残っています。これは明示しておきます。「プロジェクト全体で 98 % のカバレッジ」と言うのは誤解を招くからです。
議論の余地はあるが、私はこう決めました: テスト実行器は unittest(stdlib)であって、pytest ではない。test_ という接頭辞は習慣ですが、実際に実行するのは unittest です。なぜか? vibe coding のプロジェクトでは、依存関係を 1 つ増やす = AI がその依存関係を誤って使う余地を 1 つ増やすからです。単純さは目標です。unittest は Python 標準ライブラリに含まれており、インストールもプラグインも不要です。
実践テスト: 複数リポジトリ + 製品の自家使用(dogfooding)+ 視覚レンダリング確認
229 件の unittest だけでは足りません。私は 3 層の実践テストを追加します。
1. 複数リポジトリ — 異なる形式の README を持つ複数の公開リポジトリ上でスクリプトをテストする。これにより、fixture では拾えない境界ケースが見つかります。たとえば、8 階層の heading を持つ README、継承された shortcode を含む別の README、異種の埋め込みコードを含む 3 つ目の README です。Nouveauté 1 の silent-failure 事故が見つかったのも、この段階でした。
2. ブログでの dogfooding — jls42.org はそのスクリプト自身で翻訳されます。公開された各記事は、本番環境でのライブテストです。ユニットテストをすり抜けた境界ケースがあれば、あなたが今読んでいるこのページ上に現れます。これが究極のテストです。オンラインにあるものこそ、このプロジェクトが生み出したものです。
3. 視覚レンダリングテスト — レンダリングされた翻訳が正しく表示されるかを確認します。ブラウザ(最終ページ)で、または Markdown プレビュー用プラグインを使って VSCode で直接確認します。狙いは、構文上有効な Markdown に満足せず、実際のレンダリングを見ることです。視覚レンダリングは、テキストテストでは見えない見た目のバグ(壊れた表、壊れた code block、誤解釈された frontmatter)を炙り出します。
AI もこのテストに参加します。/pr-review-toolkit はテスト環境でコードを実行し、pair-IA の利用には視覚検証のパスが常に含まれます(「X ページのドイツ語訳がきちんと表示されるか確認して」)。
📄 .pre-commit-config.yaml 抜粋(主要な pre-commit hooks)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 scripts/check-security-sast.sh 抜粋
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 .github/workflows/sonarcloud.yml 抜粋
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}安全装置 2: AI 支援レビュー + マルチモデルの流れ
用語の補足: このセクションで Claude Opus について話すとき、私は v1.9 を開発するために使っているモデルを指しています。AI-Powered Markdown Translator が翻訳に使うモデルのことではありません。プロジェクト自体は 4 つの provider(OpenAI, Mistral AI, Claude, Gemini)をサポートしており、どんなモデル(Sonnet, Haiku, Mistral Large, Gemini 3 Pro など)でも使えます。開発側では Opus に固定します。実行時の利用では、プロジェクトは agnostic のままです。
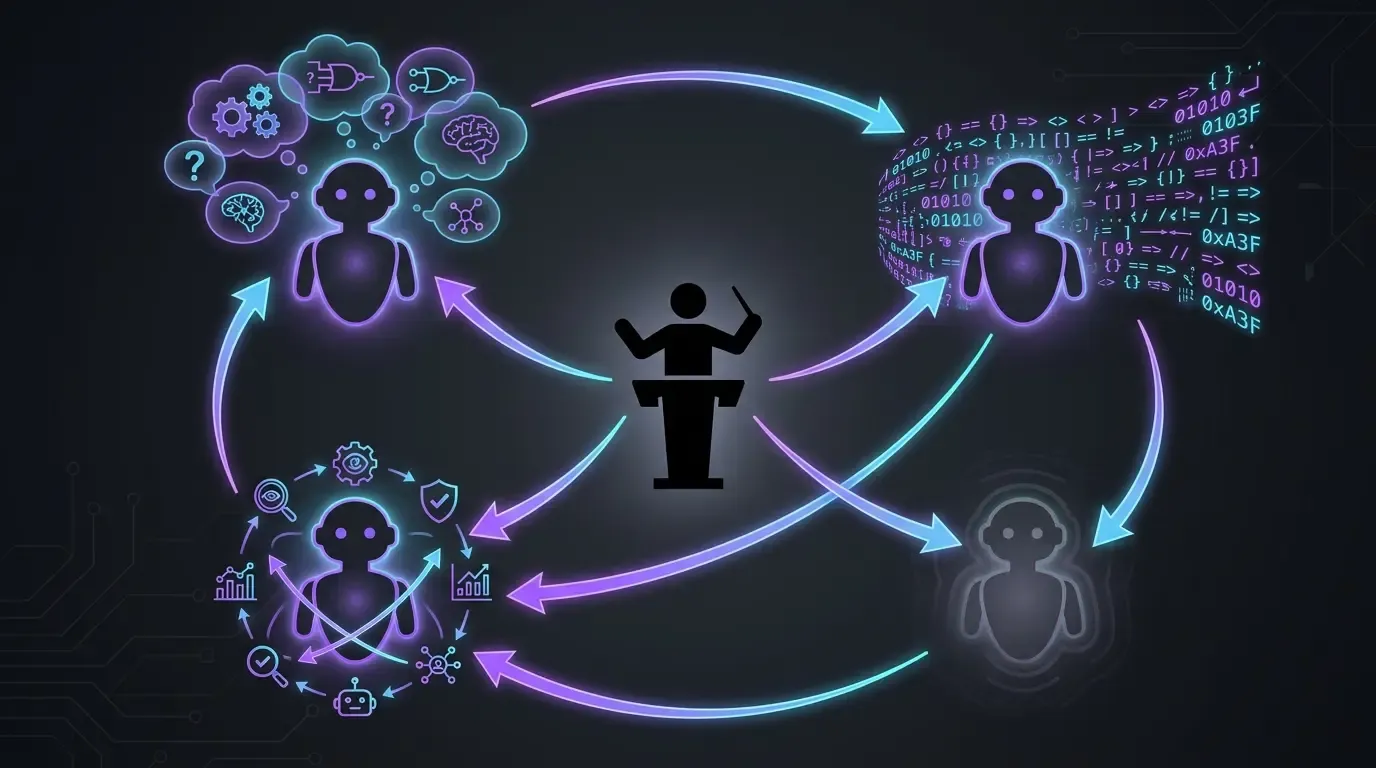
実際のワークフロー:4つのモデル、4つの役割(開発向け)
- Opus の Claude Code のみを使用(anthropic):主担当の実行役。コンテキストを読み、コードを書き、修正を適用する。Sonnet も Haiku も fast mode もなし。このプロジェクトでは、毎回ハイエンドのモデルを使いたい。考え方はシンプルで、最良の結果を目指すなら最良のものを使う、ということです。
- **OpenAI Codex は代替(fallback)**として使用:次の 2 つの明確なケースで使います。
- Opus があるテーマで行き詰まったとき(まれですが実際にあります。たとえば Codacy や SonarCloud のような外部エージェントから求められた修正では、Claude が収束しないことがあり、そういうときは詰まりを解消するために Codex に切り替えます)
- Anthropic の利用枠が飽和したとき。Codex があれば、クォータのリセットを待っている間も流れを止めずに済みます。
- GPT-5.5 reasoning extra-high (
xhigh):実行前の計画の挑戦役。Claude Code にあるテーマを任せる前に、計画を GPT-5.5 の reasoning extra-high に通します。適切な問いを投げ、盲点を浮かび上がらせてくれるので、後から修正が必要になるような悪い方向へ進むのを防げます。 /pr-review-toolkit:review-pr(Claude Code の skill プラグイン):専門エージェント(セキュリティ、品質、テスト、コメント、型設計)によるマージ前レビュー。skill は PR 上で回り、私がマージする前にチェックを入れます。コードがmainに入る前の、最後の AI の安全網です。
これらのモデルのどれか一つだけでは不十分です。それぞれが異なる役割を担っています。つまり、ハイエンドの実行役、代替のキャパシティ担当、計画の挑戦役、そして多角的な視点を持つレビュー担当(reviewer)です。
/pr-review-toolkit:自分では見えなかったもの
すべてです。私はコードを見ません。skill がすべて拾ってくれます。隠れたバグ、セキュリティ上の問題、テストの不整合、通ってはいるが何も検証していないテストまで。
PR #2(75 commits、9 837 additions、1 982 suppressions、58 files)では、人間一人なら疲労で PR の 80 % を skip していたはずです。skill は何も skip しません。すべての diff、すべてのテスト、すべてのコメントを読みます。そして何より、挑戦します。悪いと判断したパターンは拒否し、代替案を提案します。
音楽家ではなく、指揮者としての人間
私の役割は、コードを書くことを除くすべての工程をカバーします。私は プロダクトオーナー(機能を考え、優先順位を付け、取捨選択する)、QA(実際のケースでテストし、表示を目視で確認する)、tech lead(GPT-5.5 reasoning extra-high で計画を挑戦する)、最終顧客(ブログ上での日々の実使用体験にもとづいて結果を判断する)という役割を担っています。私が持たない唯一の帽子は、コーダーの帽子です。残りは全部、私です。
私は演奏者ではなく、プロデューサーになったのです。
ブログのために:自分自身を翻訳する(約 1,800 件の翻訳)
AI-Powered Markdown Translator は、自分自身の README を 14 言語で生成し、jls42.org の外国語版コンテンツをすべて作っています。具体的には、約 1,800 の翻訳版がブログを支えています(25 記事 + 4 プロジェクト + 98 AI ニュース × 14 言語、FR 原文を除く — つまり、これを書いている時点で 1,778 版)。ここでご覧のページのうち、フランス語以外の言語のものはすべて、このプロジェクトを通っています。
これは製品の内部利用(dogfooding)を極限まで押し進めたものであり、翻訳について語る記事そのものを翻訳でストレステストしています。もし ar、hi、ko で読んでいる内容に整合性があるなら、新機能 1(翻訳後検証)の安全網が機能しているということです。もし翻訳メモが上部に正しく表示されているなら、新機能 2(多配置メモ)が動いているということです。もし EN の引用が各言語版でも維持されているなら、新機能 3(--news モード)も機能しているということです。
総括:雑な AI ペアではなく、厳密な AI ペアを
感覚だけで開発することには、もっともな理由で悪評があります。まさにその点に対して、私は取り組んでいます。この v1.9 から得られた具体的な教訓は 4 つです。
-
サイレントな失敗が最大の敵です。 AI は、一見問題なさそうで単体テストも通るコードを出します。クライアント側の検証は必須です。そして、実際の成果物を別の AI にレビューさせること。コードだけではありません。
-
pre-commit hooks は 10 秒未満、さもなくば迂回される;pre-push は 30 秒以上かかってもよい。 AI は、コストを考えずにツールを増やしがちです。計画の段階か、後からでもよいので、人間がきちんと枠を決める必要があります。重要なのは、最終的に hooks が適切に調整され、日常的に実際に使われることです。
-
強い assertion のないカバレッジは演劇です。 AI は、200 個のテストを生成して、それらが何も検証していないのに通してしまうことがあります。unittest + 正確な assertion は、mock を大量に使った pytest より優れています。コードが落ちなかったかだけでなく、返り値を確認してください。
-
AI によるレビュー(PR review)はオプションではありません。 人間の作者がレビューしきれなかったとき、AI のレビュアーは飾りではありません。委譲された目なのです。
うまくやる vibe coding とは、コードを読まないことを受け入れ、その批判的な読み取りを、本当にそれをやってくれる別の AI に委ねることでもある。
このプロジェクトが示していること
この v1.9 は、私の働き方のいくつかの側面を示しています。
- 人間の役割はコード以外の全工程をカバーする:プロダクト(機能を考え、優先順位を付ける)、QA(実ケースでテストし、視覚的に検証する)、tech lead(reasoning extra-high の LLM で計画を挑戦する)、最終顧客(実際の使用で判断する)。私が持たない唯一の役割は、コードを書くことです。
- 安全網を削るのではなく、重ねる:人間によるレビューを減らすほど、ツールによる検証を増やす。これは妥協ではなく、規律の欠如でもありません。もしレビューを外すなら、AI を盲信するのではなく、安全網を二重にする必要があります。
- AI のバグを見つけるために AI を使う:サイレントな失敗は、マルチリポジトリの実践テストの最中に Claude が見つけました。完全な委譲です。批判的なレビューも委譲できます。
- 時間制約のある個人開発における増幅器としての AI ペア:このプロジェクトは、夜や週末に進めています。AI ペアがなければ、ここまで遠くへも速くも行けなかったのは明らかです。あるからこそ、他の責務の合間でも、オープンソースのプロジェクトを産業レベルで維持できます。vibe coding が可能にするのは、開発者の代替ではなく、単独ではできないことをできるようにすることです。
- すべてを作り直すのではなく、反復する:9 つのバージョン、段階的なリファクタリング(1 関数 → 7 helpers)、後方互換性の維持。AI ペアは、すべてを書き直さずに素早く反復するのに役立ちます。
リソース
- GitHub 上の AI-Powered Markdown Translator
- Release v1.9
- PR #2 — 75 commits、migration + quality
- 完全な CHANGELOG
- このブログ上のプロジェクトページ
- 2024 年の記事 — v1.5(release notes 風) — トーンの比較用
- Deep Dive AWS Diagram — シリーズの別記事
AI-Powered Markdown Translator を、自分の Markdown — オープンソースの README、ブログ記事、技術文書 — で試したい方は、コードは GitHub にあります。数分で導入でき、4 つの provider をサポートし、コスト削減のための --eco モード、元の引用を保持する --news モード、そして今では、AI ペア開発の自分のプロジェクトでもテンプレートとして再利用できる v1.9 の品質スタックがあります。
もしあなたが個人プロジェクトを感覚だけで開発(vibe coding)しているなら、品質面では最も簡単な道を選ばないでください。信頼性はスピードの対価です。その両方を一緒に受け入れてください。