ai-powered-markdown-translatorgpt-5.4-mini के साथ fr से hi में अनुवादित लेख।
AI-Powered Markdown Translator एक ओपन-सोर्स प्रोजेक्ट है जिसे मैं 2024 से मेंटेन कर रहा हूँ: एक Python स्क्रिप्ट जो 4 एआई प्रदाताओं (OpenAI, Mistral AI, Claude, Gemini) के जरिए किसी भी Markdown फ़ाइल का 14 भाषाओं में अनुवाद करती है। यह हर प्रकाशन पर इस ब्लॉग को शक्ति देता है — आप यहाँ जो भी पेज फ्रेंच के अलावा किसी और भाषा में पढ़ते हैं, वह इसी से होकर गुज़रा है — और लगभग 1 800 अनुवादित संस्करण प्रोडक्शन में इसके दम पर चल रहे हैं।
8 मई 2026 को, मैंने v1.9 जारी की, जिसमें 75 कमिट शामिल हैं और जो 2024 की v1.5 के बाद से सबसे बड़ा अपडेट है। तीन उत्पाद-नवाचार:
- अनुवादोत्तर वैलिडेशन (मौन विफलता-रोधी)
- बहु-स्थानिक अनुवाद नोट (ऊपर, नीचे या दोनों)
- EN स्रोत उद्धरणों को सुरक्षित रखने के लिए
--newsमोड
लेकिन इस v1.9 की एक खासियत है जिसे मैं यहाँ बताना चाहता हूँ: सारा कोड पेयर-एआई में लिखा गया है। हाथ से एक भी पंक्ति टाइप नहीं की गई। इसलिए 3 नवाचारों के अलावा, यह लेख “कैसे” पर भी बात करता है: जब हम यह नहीं पढ़ते कि एआई क्या पैदा कर रही है, तब भी साफ़ और सुरक्षित कोड लक्ष्य करने के लिए कौन-से सुरक्षा-घेर लगाए जाते हैं?
संदर्भ: रोज़ाना इस्तेमाल होने वाला प्रोजेक्ट, लेकिन कोड पक्ष पर कम मेंटेनेंस
सितंबर 2024 से मई 2026 तक: निरंतर उपयोग, बीच-बीच में रखरखाव
मैंने v1.5 के 2024 वाले स्रोत कोड का विस्तार से वर्णन करने वाला एक लेख प्रकाशित किया था। उस समय मैं स्क्रिप्ट को सीधे लेख में ही प्रकाशित करता था। आज दृष्टिकोण बदल गया है: अब जो महत्त्वपूर्ण है वह उतना नहीं कि मैं कौन-सा कोड लिखता हूँ, बल्कि वह कार्यप्रवाह है जो उसे बनाता है।
सितंबर 2024 में जारी v1.5 और जनवरी 2026 के बीच, प्रोजेक्ट चलता रहा — यह इस ब्लॉग की हर नई सामग्री का अनुवाद करता रहा — लेकिन सार्वजनिक कोड लगभग नहीं बदला। 2025 में केवल एक कमिट पुश किया गया। इस पूरे समय मैं अपनी निजी ज़रूरतों के लिए लोकल में कोड विकसित करता रहा — खासकर मॉडल, जिन्हें मैं उनकी रिलीज़ के साथ बदलता रहा — लेकिन ये बदलाव मेरी मशीन तक ही सीमित रहे। GitLab पर सार्वजनिक संस्करण अभी भी v1.5 के डिफ़ॉल्ट मानों की ओर ही इशारा करता रहा।
2026 की शुरुआत में, मैंने इसे अपडेट करने की पहली कोशिश की: दो महीनों में तीन रिलीज़ (जनवरी की शुरुआत में दो दिनों के भीतर v1.6 और v1.7, मार्च में v1.8) जिन्होंने फ़ीचर्स के लिहाज़ से प्रोजेक्ट को अपडेट किया — 2026 मॉडल, Gemini सपोर्ट, --eco मोड, एकल फ़ाइल, स्रोत उद्धरणों के लिए --news मोड। लेकिन अभी भी CI नहीं थी, स्वचालित टेस्ट नहीं थे, गुणवत्ता-गेट नहीं थे — जो मेरे लिए तब एक वास्तविक समस्या बन गया जब मैं एक ऐसे एआई एजेंट के साथ और आगे बढ़ना चाहता था जो मेरी जगह कोड लिखता है।
निजी समय पर चलने वाले प्रोजेक्ट की रफ़्तार
यह अंतर क्यों? क्योंकि मैं इस प्रोजेक्ट को अपने निजी समय पर चलाता हूँ। मेरा परिवार है, स्क्रीन के बाहर भी ज़िंदगी है, इसलिए प्रगति तभी होती है जब मुझे शामें और वीकेंड मिलते हैं। मैं जुनूनी हूँ, इन विषयों पर काफी समय भी देता हूँ — मैं बहुत टेस्ट करता हूँ, एजेंटों को गाइड करता हूँ, परिणामों को वैलिडेट करता हूँ — लेकिन रफ़्तार किसी प्रो प्रोजेक्ट जैसी नहीं है।
पेयर-एआई ठीक यही बदलता है। यह मुझे दो बाधाओं — जुनून और स्क्रीन के बाहर की ज़िंदगी के संतुलन — के बीच आगे बढ़ने देता है। पेयर-एआई के बिना, मैं स्पष्ट रूप से न तो इतनी दूर जाता और न इतनी तेज़ी से। इसके साथ, मैं अपनी पूरी ज़िंदगी इसमें झोंके बिना एक औद्योगिक-स्तर के ओपन-सोर्स प्रोजेक्ट को मेंटेन कर सकता हूँ।
प्रारंभिक लक्ष्य: गुणवत्ता + GitLab → GitHub माइग्रेशन
अप्रैल 2026 के मध्य में, मैंने आखिरकार इस पर गंभीरता से काम करने का फैसला किया। दो सरल लक्ष्य:
- गुणवत्ता की एक परत जोड़ना (स्टैटिक एनालिसिस, टेस्ट, CI)
- रिपॉज़िटरी को GitLab से GitHub पर माइग्रेट करना
बस इतना ही। लेकिन पेयर-एआई कोड एजेंट के साथ, हम कभी वही नहीं लिखते जो पहले सोचा गया था। PR अंततः 75 कमिट, 9 837 जोड़, 1 982 हटाव, 58 फ़ाइलों तक पहुँच गई।
| संस्करण | तिथि | मुख्य योगदान |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, फिर Mistral, फिर Claude |
| 1.5 | सित. 2024 | क्लाइंट्स का रिफैक्टर, 2024 मॉडल (gpt-4o, claude-3.5-sonnet) |
| 1.6 | जन. 2026 | 2026 मॉडल (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, --eco मोड, एकल फ़ाइल (--file) |
| 1.7 | जन. 2026 | --keep_filename, .env, सुरक्षित इनलाइन कोड |
| 1.8 | मार्च 2026 | डिफ़ॉल्ट रूप से GPT-5.4 मॉडल, --news मोड citation placeholders के साथ |
| 1.9 | मई 2026 | अनुवादोत्तर वैलिडेशन, बहु-स्थानिक नोट, 14 hooks + 229 tests + एआई समीक्षा वाली गुणवत्ता स्टैक |
बर्फ़ीला गोला प्रभाव
हर नया गुणवत्ता उपकरण समस्याएँ सामने लाता गया। Codacy ने डुप्लिकेशन दिखाए। SonarCloud ने code smells उठाए (ऐसे संकेत कि कोड आगे चलकर खराब तरह से मेंटेन होगा: बहुत लंबी फ़ंक्शनें, अप्रयुक्त पैरामीटर, उलझी हुई संरचनाएँ)। /pr-review-toolkit ने छिपे हुए बग्स की ओर इशारा किया। हर रिपोर्ट पर, एजेंट उन्हें ठीक करता, और कभी-कभी आसपास की चीज़ों को भी बेहतर बना देता।
दायरा स्वाभाविक रूप से फैलता गया। मैं बिल्कुल यही चाहता था — प्रोजेक्ट को आधुनिक बनाना — लेकिन मेहनत की मात्रा का निर्धारण मैं नहीं, बल्कि उपकरण कर रहे थे। vibe coding वाले प्रोजेक्ट के लिए यह एक महत्वपूर्ण बिंदु है: गुणवत्ता उपकरण काम को जितना सत्यापित करते हैं, उतना ही उसे दिशा भी देते हैं।
नवाचार 1: अनुवादोत्तर वैलिडेशन (मौन विफलता-रोधी)
घटना: बग एआई ने ही टेस्ट के दौरान पकड़ा
विभिन्न सार्वजनिक रिपॉज़िटरी के README पर PR का टेस्ट करते समय — एक ऐसा मामला जिसे कोई fixture कवर नहीं कर रहा था — एआई ने वह बात सामने रखी जो मेरी नज़र से छूट गई थी: कुछ भाषाओं में (खासकर हिंदी, ISO कोड hi), अनुवाद के बीच मूल भाषा के अंश रह गए थे। API ने 200 लौटाया था, स्क्रिप्ट ने फ़ाइल लिख दी थी, लेकिन सामग्री आधी-अधूरी अनुवादित थी। और यह मौजूदा यूनिट टेस्ट बैटरी से होकर निकल गया — जो इस वास्तविक बहुभाषी मामले को कवर नहीं करती थी।
यह ठीक वही तरह का बग है जो vibe coding पैदा कर सकता है और जिसे कोई नहीं देखता। कोड तार्किक लगता है, टेस्ट fixtures उस केस को कवर नहीं करते, इंसान परिणाम को नहीं पढ़ता। लेकिन यहाँ, जब स्क्रिप्ट को वास्तविक (बहु-रिपॉज़िटरी) मामलों पर टेस्ट किया गया, तो एआई ने वही किया जो fixtures नहीं कर रहे थे।
मुझे इससे यह सीख मिली: व्यावहारिक बहु-रिपॉज़िटरी टेस्ट वह पकड़ लेते हैं जिसे यूनिट टेस्ट चूक जाते हैं। और एआई का उपयोग पिछले एआई एजेंटों के बग खोजने के लिए भी किया जा सकता है — बशर्ते उसे विविध वास्तविक मामलों के सामने रखा जाए।
उसी क्षण मुझे समझ आया कि एक वास्तविक अनुवादोत्तर वैलिडेशन जोड़ना होगा। यही पहली नवाचार है जिसे मैं अब विस्तार से बताता हूँ: दोहरी वैलिडेशन परत।
दोहरी वैलिडेशन परत
| चरण | क्रिया | यदि असफल |
|---|---|---|
| 1️⃣ | प्रदाता का API कॉल | नेटवर्क अपवाद → ❌ विफलता |
| 2️⃣ | प्रदाता-वार finish_reason (या Claude में stop_reason) श्वेतसूची | श्वेतसूची से बाहर → ❌ विफलता |
| 3️⃣ | लीक-रोधी: आउटपुट में स्रोत की 120 या अधिक अक्षरों वाली कोई भी विंडो शब्दशः न हो | स्रोत विंडो मिल गई → ❌ विफलता |
| 4️⃣ | langdetect.detect_langs (स्रोत बनाम लक्ष्य प्रायिकताएँ) | स्रोत > 0,80 और लक्ष्य < 0,20 → ❌ विफलता |
| 5️⃣ | खाली-सामग्री + आउटपुट/स्रोत अनुपात (यदि स्रोत ≥ 500 अक्षर) | खाली या आउटपुट < max(50, source/20) → ❌ विफलता |
| ✅ | SUCCESS | exit code 0 |
परत 1 (नियतात्मक) — पहला सुरक्षा-जाल: API द्वारा लौटाए गए स्टेटस की जाँच करना। हर प्रदाता के पास एक finish_reason फ़ील्ड होता है (या Claude में stop_reason), जो बताता है कि LLM ने जनरेशन क्यों रोकी। स्क्रिप्ट स्वीकार्य स्टेटसों की एक प्रदाता-वार श्वेतसूची रखती है — नामकरण अलग-अलग है (stop OpenAI/Mistral में, STOP या FINISH_REASON_STOP Gemini में, end_turn या stop_sequence Claude में)। सुरक्षा के लिए कोड None को भी सहन करता है, जब SDK यह फ़ील्ड नहीं लौटाता। इसके अलावा कोई भी अन्य स्टेटस — उदाहरण के लिए प्रदाता के अनुसार length, max_tokens या MAX_TOKENS, जो टोकन सीमा से रोकी गई प्रतिक्रिया का संकेत देते हैं — तुरंत RuntimeError ट्रिगर करता है, बिना किसी पुनर्प्राप्ति प्रयास के।
दूसरा नियतात्मक सुरक्षा-जाल थोड़ा सूक्ष्म है: जाँचना कि स्रोत पाठ का कोई भी भाग अनुवादित आउटपुट में शब्दशः दिखाई न दे। व्यावहारिक रूप से, हम स्रोत पाठ से 120 अक्षर या उससे अधिक की विंडो निकालते हैं; यदि उनमें से कोई विंडो हूबहू आउटपुट में मिल जाती है, तो इसका मतलब है कि उसका अनुवाद नहीं हुआ — failure। यही जाँच हिंदी वाले मामले को पकड़ लाई: LLM ने stop जवाब दिया था (अर्थात API पक्ष पर “स्वाभाविक” समाप्ति), लेकिन कुछ फ्रेंच अनुच्छेद आउटपुट में जस के तस रह गए थे — finish_reason जाल से अदृश्य, शब्दशः लीक-रोधी जाल द्वारा पकड़े गए।
परत 2 (संभाव्यतावादी) — langdetect.detect_langs आउटपुट की भाषा का विश्लेषण करता है और कई संभावित भाषाओं पर प्रायिकताओं का वितरण लौटाता है। हम स्रोत भाषा और लक्ष्य भाषा की प्रायिकता निकालते हैं, फिर केवल तब अस्वीकार करते हैं जब स्रोत-प्रायिकता 0,80 से ऊपर हो और लक्ष्य-प्रायिकता 0,20 से नीचे गिर जाए — यह सीमा जानबूझकर संयमी रखी गई है ताकि तकनीकी कोड-स्विचिंग (उदाहरण के लिए फ्रेंच अनुवाद में वैध अंग्रेज़ी शब्द) पर झूठे सकारात्मक न आएँ। यह परत गैर-लैटिन लिपि वाली भाषाओं के लिए जल्दी बंद हो जाती है (हिंदी hi, अरबी ar, चीनी zh, जापानी ja, कोरियाई ko), जहाँ पर्याप्त लिपि-संकेत पहले ही आउटपुट को वैध ठहरा देता है। और यह केवल तभी चलती है जब साफ़ किया गया आउटपुट कम-से-कम 100 अक्षरों का हो, ताकि बहुत छोटे पाठ पर झूठे सकारात्मक न आएँ।
मात्रात्मक सुरक्षा-घेर
दोनों परतों के ऊपर दो और साधारण लेकिन ज़रूरी जाँचें:
- खाली-सामग्री गार्ड: यदि प्रदाता खाली आउटपुट लौटाता है जबकि
finish_reasonstopहै, तो हम तुरंत अस्वीकार कर देते हैं (वरना हम success के रूप में चिह्नित एक खाली फ़ाइल लिख देते) - सैनिटी रेशियो: केवल यदि स्रोत कम-से-कम 500 अक्षरों का हो, हम जाँचते हैं कि आउटपुट संदिग्ध रूप से छोटा तो नहीं है (आमतौर पर <
max(50, source/20)). यह एक अदृश्य ट्रन्केशन डिटेक्टर है, कोई सामान्य लंबाई-नियम नहीं
Claude पर विशेष रूप से, max_tokens v1.9 में 4 096 से बढ़कर 32 768 हो गया (यह बदलाव कोड स्तर पर Claude ने किया, जब मैंने लक्षण देखा और जाँच करने को कहा)। CHANGELOG में दर्ज कारण: 16k अक्षर वाले सेगमेंट्स पर होने वाली छिपी हुई ट्रन्केशन से बचना, और गैर-लैटिन लिपि वाली भाषाओं (FR → JA, ZH, KO, AR, HI) के लिए अतिरिक्त मार्जिन देना, जो समकक्ष लैटिन लिपि की तुलना में आउटपुट में अधिक टोकन खपत करती हैं।
स्पष्ट स्टेटसों द्वारा लौटाव
फ़ाइल पाइपलाइन (translate_markdown_file()) अब एक स्पष्ट स्टेटस लौटाती है — success, failure या skipped। CLI इन स्टेटसों को एकत्र करता है और जैसे ही कम-से-कम एक फ़ाइल विफल होती है, non-zero exit code के साथ समाप्त होता है — जिससे विफलता को कॉल करने वाली स्क्रिप्ट या v1.9 में जोड़ी गई नई CI दोनों के लिए उपयोगी बनाया जा सकता है। इस v1.9 से पहले, कई त्रुटियाँ केवल प्रिंट होती थीं या सफल अनुवाद के रूप में चल जाती थीं: प्रोसेस 0 पर खत्म हो सकता था जबकि फ़ाइल गायब, अधूरी या गलत तरीके से वैलिडेट की गई होती थी। skipped स्टेटस खुद एक पढ़ने योग्य संकेत बन जाता है (“जानबूझकर छोड़ा गया”), जो success (“अनुवाद सही ढंग से लिखा गया”) से अलग है।
📄 Python अंश: अनुवादोत्तर दोहरी वैलिडेशन (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteनवाचार 2: बहु-स्थानिक अनुवाद नोट
ज़रूरत: एक सूक्ष्म लेकिन सूचनात्मक नोट
जब AI-Powered Markdown Translator किसी अनुवाद को लिखता है, तो वह एक अनुवाद नोट जोड़ता है जो इस्तेमाल किए गए मॉडल और तारीख को बताता है। v1.9 से पहले, यह नोट हमेशा फ़ाइल के नीचे चिपका दिया जाता था, एक पुराने (legacy) फ़ॉर्मैट में, जिसमें दृश्य सीमाएँ होती थीं।
नीचे चिपका हुआ फ़ॉर्मैट मेरी अपनी ज़रूरतों के लिए दो समस्याएँ पैदा करता था। पहली, पाठक को बहुत अंत में ही पता चलता था कि सामग्री का अनुवाद एआई ने किया है — शुरुआत में ही सूचित करना बेहतर है, इससे सामग्री के लिए सही अपेक्षा बनती है। दूसरी, फ़ुटर नोट उस अनुवाद प्रोजेक्ट को उजागर नहीं करता था जो यह सब संभव बनाता है: आप लेख पढ़ते हैं, और बहुभाषी फ़्लो की उत्पत्ति अनदेखी रह जाती है। इसलिए मैं नोट को ऊपर ले जाने में सक्षम होना चाहता था, जबकि ट्रेसबिलिटी बनी रहे — और मौजूदा उपयोगों को तोड़े बिना। v1.9 दो ऐसे फ्लैग जोड़ता है जो कुछ नहीं तोड़ते:
--note_position {top,bottom,both}: ऊपर, नीचे या दोनों--note_format {legacy,marker}: लीगेसी फ़ॉर्मैट या मार्कर फ़ॉर्मैट (marker format)
पिछड़े-संगत डिफ़ॉल्ट: legacy + bottom. कोई भी मौजूदा अनुवाद-शृंखला डिफ़ॉल्ट रूप से अपना व्यवहार नहीं बदलती — नए फ्लैग्स को आवश्यकता होने पर स्पष्ट रूप से सक्रिय किया जाता है।
मार्कर फ़ॉर्मैट: एक साफ़ GitHub एम्बेड कार्ड
मार्कर फ़ॉर्मैट Markdown GitHub की एक सूक्ष्म बारीकी का उपयोग करता है: लिंक संदर्भ परिभाषाएँ जो उपयोग में नहीं आतीं, रेंडर में अदृश्य रहती हैं। इसलिए हम फ़ाइल के ऊपर एक टिप्पणी-मार्कर में मेटाडेटा (मॉडल, तारीख, स्रोत) एन्कोड कर सकते हैं — ब्राउज़र में अदृश्य, लेकिन कच्ची कॉपी में ज्यों-का-त्यों सुरक्षित।
GitHub इसके अलावा फ़ाइल के अनुवादित लिंक को साझा करने पर एक एम्बेड कार्ड भी जनरेट करता है, और वह कार्ड दस्तावेज़ का शीर्षक बिना किसी टेक्स्ट प्रदूषण के ठीक से दिखाता है।
top स्थिति में मार्कर फ़ॉर्मैट के साथ कच्चा Markdown उदाहरण:
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...आँख से देखने पर पाठक को केवल शीर्षक और उसके बाद सामग्री दिखती है। मार्कर न तो HTML रेंडर को प्रदूषित करता है, न एम्बेड कार्ड को।
फ्रंटmatter का सचेत सम्मिलन (frontmatter-aware)
तकनीकी लेकिन निर्णायक विवरण: top में एक note जोड़ना का मतलब यह नहीं है कि « फ़ाइल की line 1 पर जोड़ो »। अगर फ़ाइल में YAML frontmatter है (और इस blog में यही case है), तो note को frontmatter के बाद insert करना चाहिए — वरना note YAML को तोड़ देता है।
मैंने Claude को जरूरत बताई (« note को frontmatter के बाद insert करो, उसके पहले नहीं — वरना तुम YAML तोड़ दोगे »), उसने _split_frontmatter नाम का एक helper निकाला जो open/closed --- fences को detect करता है। अगर फ़ाइल में बंद न हुई YAML fence हो (malformed case), तो helper चुपचाप टूटी हुई फ़ाइल बनाने के बजाय RuntimeError raise करता है। एक monolithic function से 7 pure helpers (अलग और testable) में जाना वही है जो अच्छी तरह निर्देशित pair-AI तेज़ी से कर सकता है। यहाँ मेरी भूमिका: जरूरत का guide, tester, final client जो परिणाम validate करता है। कोड नहीं लिखना। इस project पर मैं कई टोपी पहनता हूँ — सिवाय code लिखने वाली टोपी के, जो Claude के पास जाती है।
| स्थिति | Format | सामान्य उपयोग-केस |
|---|---|---|
top | marker | ब्लॉग लेख (सूक्ष्म note, साफ़ embed card) |
top | legacy | आंतरिक दस्तावेज़ जहाँ visible traceability मायने रखती है |
bottom | marker | open-source README (footer के साथ सुसंगत) |
bottom | legacy | डिफ़ॉल्ट — backward compatible |
both | marker | लंबे लेख जहाँ top + bottom आश्वस्त करते हैं |
both | legacy | legacy case जिसमें double traceability की ज़रूरत हो |
📄 Python अंश : helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")नवाचार 3 : स्रोत EN उद्धरणों को सुरक्षित रखने के लिए --news mode
समस्या : उद्धरणों को तोड़े बिना अनुवाद करना
जब मैं इस blog के लिए ia-actualites लेख लिखता हूँ (multi-source IA news daily/weekly), मैं नियमित रूप से अंग्रेज़ी tweets, blog posts, version announcements cite करता हूँ — अक्सर प्रति लेख कई। अगर translation उद्धरणों को छू ले, तो वे गलत हो जाते हैं।
अनुवादित उद्धरण एक विकृत उद्धरण है। सभी भाषाई संस्करणों (EN, DE, JA, etc.) में हम चाहते हैं कि उद्धरणों की मूल अंग्रेज़ी बनी रहे — यह स्रोतों के प्रति निष्ठा की एक आवश्यकता है — साथ में target language का flag और पढ़ने की सुविधा के लिए italic में एक translation हो।
समाधान : placeholders <NEWSQUOTE id="N"/>
| चरण | क्रिया |
|---|---|
| 1️⃣ | इनपुट में EN उद्धरणों के साथ FR source Markdown |
| 2️⃣ | पूर्व-प्रसंस्करण : EN उद्धरणों का निष्कर्षण, उन्हें <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, आदि जैसे placeholders से बदलना |
| 3️⃣ | API अनुवाद (FR → target_lang) — मूल EN उद्धरण कभी LLM को नहीं भेजे जाते, केवल placeholders भेजे जाते हैं (जैसे-के-तैसे संरक्षित) |
| 4️⃣ | पश्च-प्रसंस्करण : मूल EN उद्धरणों को जस का तस रखते हुए placeholders की बहाली + target language flag का सम्मिलन |
| 5️⃣ | अनुवाद-पश्चात सत्यापन : क्या सभी placeholders बहाल हो गए हैं? |
| ✅ | EN उद्धरणों को सुरक्षित रखते हुए target output |
| ❌ | अगर placeholder बहाल न हुआ हो या उद्धरण बदल गया हो, तो विफलता |
--news mode इसी सिद्धांत पर आधारित है : एक पूर्व-प्रसंस्करण सभी EN उद्धरणों को निकालता है, उन्हें <NEWSQUOTE id="0"/> प्रकार के placeholders से बदलता है, बाकी का अनुवाद करता है, और placeholders को बिना बदले बहाल करता है।
LANG_FLAGS mapping flag को target_lang के अनुसार ढालता है (15 भाषाएँ कवर की गई हैं) : 🇬🇧 अंग्रेज़ी के लिए, 🇩🇪 जर्मन के लिए, 🇪🇸 स्पेनिश के लिए, 🇮🇹 इतालवी के लिए, 🇵🇹 पुर्तगाली के लिए, 🇳🇱 डच के लिए, 🇵🇱 पोलिश के लिए, 🇸🇪 स्वीडिश के लिए, 🇷🇴 रोमानियाई के लिए, 🇸🇦 अरबी के लिए, 🇮🇳 हिंदी के लिए, 🇯🇵 जापानी के लिए, 🇰🇷 कोरियाई के लिए, 🇨🇳 चीनी के लिए, 🇫🇷 फ़्रेंच के लिए।
अनुवाद-पश्चात सत्यापन जाँचता है कि सभी placeholders अक्षुण्ण रूप से बहाल हुए हैं। त्रुटि कोई « EN leakage » नहीं है — EN तो जानबूझकर है — बल्कि एक अबहाल placeholder या एक विकृत उद्धरण है।
वर्तमान उपयोग-केस और संभावनाएँ
आज, मैं --news का उपयोग विशेष रूप से blog की ia-actualites articles पर करता हूँ। आगे चलकर, इसे किसी भी ऐसे लेख तक बढ़ाया जा सकता है जो फ्रेंच prose और EN स्रोत उद्धरणों को मिलाता हो — interviews, अंग्रेज़ी शोध लेखों का हवाला देने वाले अनुभव-विवरण, conference presentations के transcripts।
कोड दोबारा पढ़े बिना : guardrails को दोगुना करना क्यों ज़रूरी है
« मैं कोड नहीं पढ़ता। »
मैं कुछ भी दोबारा नहीं पढ़ता। मैं कभी-कभी एक diff पर जल्दी से नज़र डाल लेता हूँ — यह rare है, और सिर्फ़ तब जब Claude किसी बिंदु पर खुद से नहीं निकल पाता। यहाँ वह flow है जिसका मैं रोज़ाना उपयोग करता हूँ और जिसने v1.9 बनाया : Claude Code (केवल Opus) कोड लिखता है। जब Opus अटकता है या usage window भर जाती है, तब Codex काम संभालता है। GPT-5.5 reasoning extra-high में execution से पहले plans को challenge करता है। /pr-review-toolkit:review-pr हर merge से पहले PR पढ़ता है। मेरी भूमिका directions validate करने और guardrails परिभाषित करने तक सीमित है।
यह development mode — पूर्ण, सहज-आधारित (vibe coding) विकास — अनुशासन की कमी नहीं है। यह एक स्पष्ट समझौता है : कम human re-reading, अधिक tool-based validation। अभी-अभी जिन 3 v1.9 नवाचारों का मैंने परिचय दिया, वे सभी इसी flow में बने हैं। और ठीक इसलिए कि कोड दोबारा नहीं पढ़ा जाता, तकनीकी guardrails को दोगुना करना पड़ता है — उन्हें हटाना नहीं।
यहाँ production में इस development mode को viable बनाने के लिए लगाए गए दो guardrails हैं : एक automated quality stack (Guardrail 1) और multi-model flow में IA-assisted review (Guardrail 2)।
Guardrail 1 : automated quality stack (14 hooks + व्यावहारिक tests)
समग्र दृश्य
| सुरक्षा-जाल | उपकरण | सामान्य लागत | विफल होने पर अवरोधक |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hooks), detect-secrets, Lizard CCN | < 10 s | हाँ |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | हाँ, सिवाय प्रारंभिक reporting में pip-audit के |
| बाहरी CI | SonarCloud, Codacy, CodeFactor | समानांतर में | स्थानीय रूप से non-blocking, PR badges |
v1.9 के आँकड़े : 14 hooks, stdlib unittest के 229 tests, v1.9 के नए code पर ~98 % coverage, SonarCloud के 11 badges, 3 बाहरी platforms।
Pre-commit : तेज़ सुरक्षा-जाल
| # | उपकरण | Version | भूमिका |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Shell lint |
| 2 | ruff (lint) | 0.8.6 | Python lint |
| 3 | ruff (format) | 0.8.6 | Python formatting |
| 4 | prettier | 3.1.0 | Markdown / JSON / YAML formatting |
| 5 | trailing-whitespace | 5.0.0 | पंक्ति के अंत के spaces हटाना |
| 6 | end-of-file-fixer | 5.0.0 | अनिवार्य अंतिम newline |
| 7 | check-yaml | 5.0.0 | YAML syntax validation |
| 8 | check-toml | 5.0.0 | TOML syntax validation |
| 9 | check-added-large-files | 5.0.0 | दुर्घटनावश जोड़े गए बड़े binaries रोकता है |
| 10 | check-merge-conflict | 5.0.0 | Git conflict markers का पता लगाता है |
| 11 | check-executables-have-shebangs | 5.0.0 | जाँचता है कि executables में shebang है |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | जाँचता है कि shebang वाले scripts executable हैं |
| 13 | detect-secrets | 1.5.0 | API keys और secrets का पता लगाना |
| 14 | check-complexity (Lizard) | local | नए code पर cyclomatic complexity की सीमा |
मापा गया कुल : पूरे repo पर लगभग 2 से 3 सेकंड (warm cache पर, pre-commit run --all-files ने ~2,4 s पर timed किया)। एक औसत commit जो सिर्फ़ कुछ files को छूता है, उस पर यह और भी तेज़ है। मैं जो thumb rule लागू करता हूँ: 10 s से ऊपर, developers bypass करते हैं (pair-AI भी) — इसलिए इस तेज़ सुरक्षा-जाल को हमेशा चालू रखना चाहिए।
Pre-push : भारी सुरक्षा-जाल
- mypy lax mode में : कोई total strict नहीं (translate.py का ऐतिहासिक code पास नहीं होता), लेकिन नए code पर प्रगति की जाँच
- Opengrep SAST :
p/security-audit p/default p/python— injections, eval, unsafe deserialization को scan करने में लगभग 30 सेकंड - pip-audit जिसे
scripts/check-pip-audit.shने wrap किया है : JSON output capture करता है, transport errors (network, PyPI down) को shell स्तर पर वर्गीकृत करता है ताकि vulnerability और unavailability को भ्रमित न किया जाए, और vulnerabilities report करता है। v1.9 के लिए प्रारंभिक reporting mode में (warn + exit 0) — obsolete dependencies bump करने वाली PR के बाद इसे blocking तक सख्त किया जाएगा। - unittest discovery :
python -m unittest discoverपरtests/फिरscripts/tests/— 229 tests, स्थानीय रूप से लगभग 8 सेकंड
बाहरी CI : SonarCloud + Codacy + CodeFactor
.github/workflows/sonarcloud.yml workflow (project key jls42_ai-powered-markdown-translator) हर PR पर चलता है। README पर प्रदर्शित 11 SonarCloud badges : Quality Gate, Security/Reliability/Maintainability Rating, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC।
Codacy + SonarCloud + CodeFactor की redundancy क्यों? क्योंकि हर एक अलग चीज़ें देखता है। Codacy ने ऐसी duplications उजागर कीं जिन्हें SonarCloud ने नहीं बताया था। SonarCloud ने खराब गुणवत्ता के संकेत (मशहूर code smells) पकड़े जिन्हें Codacy ने छोड़ दिया। CodeFactor ने complexity की समस्याएँ सामने रखीं जिन्हें बाकी दोनों ने अनदेखा कर दिया। अकेला कोई भी पर्याप्त नहीं होता। एक अतिरिक्त platform की marginal cost शून्य है (मुफ़्त badge, 5 मिनट का integration), इसलिए हम दृष्टिकोणों की संख्या बढ़ाते हैं।
Tests : unittest stdlib (pytest नहीं)
229 tests, PR के 6 महीनों में 0 regression, v1.9 के नए code पर ~98 % coverage.
सामान्य विवरण:
test_silent_failure.py: दोहरे सत्यापन को लक्ष्य करने वाले 97 teststest_orchestration.py: orchestrator pipeline पर 79 teststest_translation_note_position.py: स्थिति × format matrix पर 38 teststest_audit_verdict.py: pip-audit wrapper पर 15 tests (scripts/tests/में)
ईमानदारी की नोट : ~98 % coverage v1.9 के नए code पर लागू होती है — translate.py के पूरे ऐतिहासिक सेट पर नहीं, जिसमें अभी भी कुछ inherited functions हैं जिनकी coverage नई test battery से कम है। मैं इसे स्पष्ट रूप से इसलिए कहता हूँ क्योंकि पूरे project पर « 98 % coverage » कहना भ्रामक होगा।
एक विवादास्पद लेकिन स्वीकार किया गया चुनाव: टेस्ट runner unittest (stdlib) है, pytest नहीं। test_ उपसर्ग आदत के कारण है, लेकिन चलाता unittest है। क्यों? vibe coding वाले project में, जो भी dependency जोड़ी जाती है = वह हर dependency जिसे IA गलत तरीके से इस्तेमाल कर सकती है। सरलता एक लक्ष्य है। unittest Python की standard library में है, शून्य installation, शून्य plugin।
व्यावहारिक tests : multi-repo + उत्पाद का आंतरिक उपयोग (dogfooding) + visual rendering की जाँच
229 unittest tests पर्याप्त नहीं हैं। मैं व्यावहारिक test की तीन परतें जोड़ता हूँ:
1. Multi-repo — कई public repos पर script को अलग-अलग formats वाले README के साथ test करना। इससे ऐसे edge cases सामने आते हैं जिन्हें fixtures कवर नहीं करते — 8 स्तर के heading वाला README, दूसरा inherited shortcodes के साथ, तीसरा अजीब embedded code के साथ। इसी चरण में Nouveauté 1 का silent-failure incident पकड़ा गया था।
2. Blog पर dogfooding — jls42.org का अनुवाद स्वयं script करता है। प्रकाशित हर article production में एक live test है। अगर कोई edge case unit tests के बीच से निकल जाता है, तो वह यहाँ, उस page पर दिखाई देगा जिसे आप पढ़ रहे हैं। यही ultimate test है — जो online है, वही project ने बनाया है।
3. Visual rendering test — मैं जाँचता हूँ कि rendered translations सही दिख रही हैं, या तो browser में (final web page), या सीधे VSCode में Markdown preview plugin के जरिए। विचार यह है: केवल syntax-wise valid Markdown से संतुष्ट न रहें, बल्कि वास्तविक rendering देखें। Visual renders ऐसे appearance bugs उजागर करते हैं (टूटे हुए tables, malformed code blocks, गलत व्याख्या किया गया frontmatter) जिन्हें text tests नहीं पकड़ते।
IAs भी इन tests में भाग लेती हैं। /pr-review-toolkit test environment में code चलाता है, और pair-IA usage में systematic visual validation passes शामिल होते हैं (« जाँचो कि page X का German translation ठीक से दिख रहा है »)।
📄 Python अंश : helper _split_frontmatter (translate.py)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 .pre-commit-config.yaml अंश (मुख्य pre-commit hooks)
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 scripts/check-security-sast.sh अंश
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}📄 .github/workflows/sonarcloud.yml अंश
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Guardrail 2 : IA-assisted review + multi-model flow
शब्दावली की स्पष्टता : जब मैं इस section में Claude Opus की बात करता हूँ, तो मैं उस model की बात कर रहा हूँ जिसका उपयोग मैं v1.9 विकसित करने के लिए करता हूँ — न कि उस model की जिसका उपयोग AI-Powered Markdown Translator अनुवाद के लिए करता है। स्वयं project 4 providers (OpenAI, Mistral AI, Claude, Gemini) और किसी भी model (Sonnet, Haiku, Mistral Large, Gemini 3 Pro, आदि) का समर्थन करता है। विकास की तरफ, मैं Opus पर lock करता हूँ। runtime usage की तरफ, project agnostic रहता है।
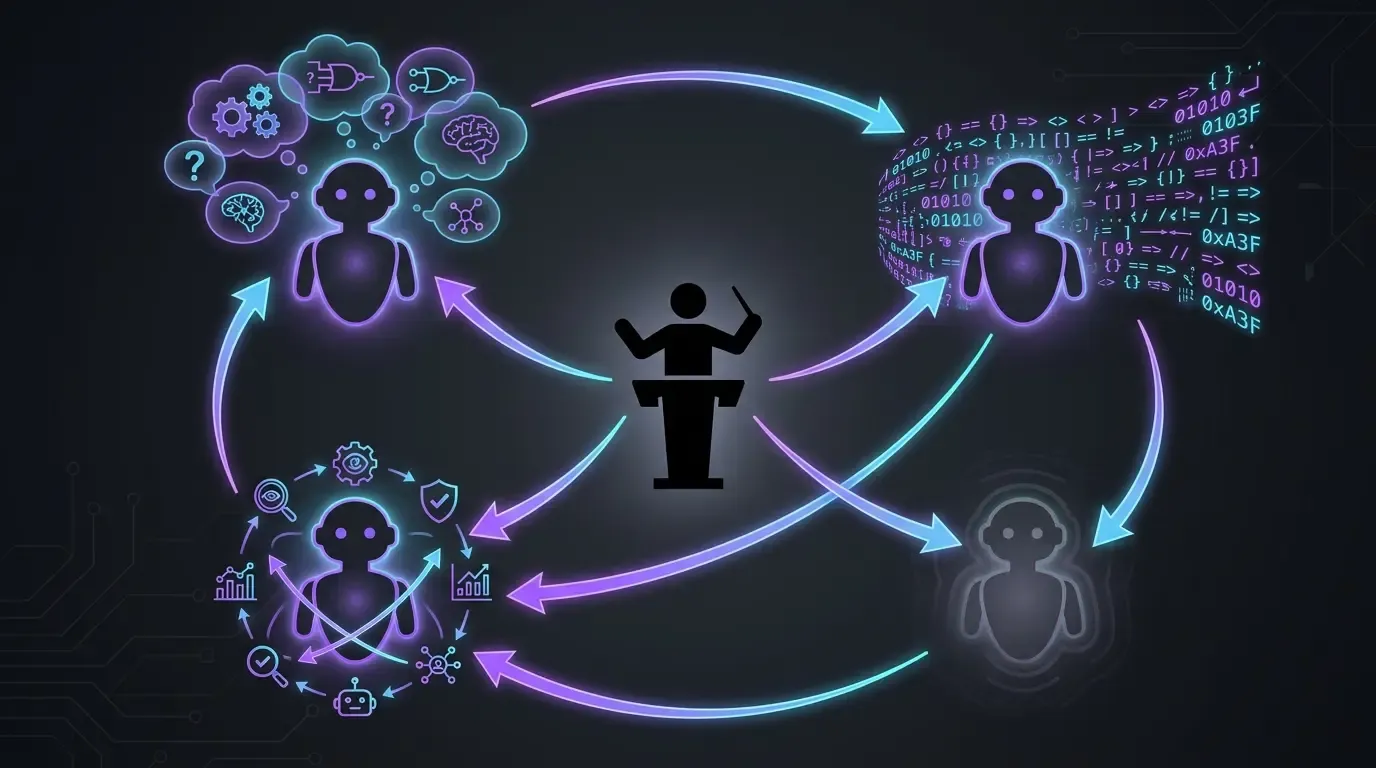
वास्तविक कार्यप्रवाह: 4 मॉडल, 4 भूमिकाएँ (विकास के लिए)
- Claude Code, सिर्फ़ Opus में (anthropic) : मुख्य निष्पादन। संदर्भ पढ़ता है, कोड लिखता है, सुधार लागू करता है। Sonnet नहीं, Haiku नहीं, fast mode नहीं। इस प्रोजेक्ट पर, मैं हर बार सबसे उच्च-स्तरीय मॉडल चाहता हूँ — विचार सीधा है: हम सबसे अच्छा चुनते हैं ताकि सर्वोत्तम संभव परिणाम हासिल कर सकें।
- OpenAI Codex, बैकअप समाधान (fallback) के रूप में : इसका उपयोग दो विशिष्ट मामलों में किया जाता है:
- जब Opus किसी विषय पर अटक जाता है (दुर्लभ है लेकिन होता है — उदाहरण के लिए Codacy या SonarCloud जैसे बाहरी एजेंटों द्वारा मांगे गए सुधारों पर, Claude कभी-कभी निष्कर्ष तक नहीं पहुँचता और मैं विषय को अनलॉक करने के लिए Codex पर शिफ्ट कर देता हूँ)
- जब Anthropic की उपयोग-सीमा भर जाती है। कोटा रीसेट होने तक गति बनाए रखने के लिए Codex मदद करता है।
- GPT-5.5 reasoning extra-high (
xhigh) : निष्पादन से पहले योजनाओं को चुनौती देता है। Claude Code को किसी विषय पर काम शुरू करने देने से पहले, मैं योजना को GPT-5.5 में reasoning extra-high के साथ भेजता हूँ। वह सही सवाल पूछता है, छूटे हुए पहलुओं को सामने लाता है। इससे गलत दिशा में जाने से बचाव होता है, जिसे बाद में सुधारना पड़ता। /pr-review-toolkit:review-pr(Claude Code skill plugin) : विशेष एजेंटों के साथ merge से पहले समीक्षा (सुरक्षा, गुणवत्ता, टेस्ट, टिप्पणियाँ, टाइप डिज़ाइन)। यह skill PR पर तब चलता है जब मैं merge करने वाला होता हूँ — कोड केmainमें प्रवेश करने से पहले यह आख़िरी AI सुरक्षा-जाल है।
इनमें से कोई भी मॉडल अकेले पर्याप्त नहीं है। हर एक की भूमिका अलग है — उच्च-स्तरीय निष्पादक, क्षमता-आधारित विकल्प, योजनाओं को चुनौती देने वाला, बहु-कोणीय पुनरीक्षक (reviewer)।
/pr-review-toolkit : वह जो मैं नहीं देख पाता
सब कुछ। मैं कोड नहीं देखता। skill सब कुछ ऊपर लाता है — छिपे हुए बग, सुरक्षा समस्याएँ, टेस्ट की असंगतियाँ, ऐसे टेस्ट जो पास हो जाते हैं लेकिन कुछ टेस्ट ही नहीं करते।
PR #2 (75 commits, 9 837 additions, 1 982 suppressions, 58 files) पर, थकान के कारण एक अकेला इंसान PR का 80 % skip कर देता। skill कुछ भी skip नहीं करता। वह हर diff, हर test, हर टिप्पणी पढ़ता है। और सबसे अहम, वह चुनौती देता है — जिन patterns को वह खराब पहचानता है, उन्हें वह अस्वीकार करता है, और विकल्प सुझाता है।
इंसान एक ऑर्केस्ट्रा संचालक के रूप में, संगीतकार के रूप में नहीं
मेरी भूमिका पूरी श्रृंखला को कवर करती है — सिवाय कोड लिखने के। मैं product manager (features पर सोचना, प्राथमिकता देना, निर्णय करना), QA (वास्तविक मामलों पर परीक्षण करना, रेंडरिंग को दृश्य रूप से मान्य करना), tech lead (GPT-5.5 reasoning extra-high के साथ योजनाओं को चुनौती देना), अंतिम ग्राहक (ब्लॉग पर अपनी रोज़मर्रा की उपयोग-प्रक्रिया के अनुभव के आधार पर परिणाम का आकलन करना) की भूमिकाएँ निभाता हूँ। एकमात्र टोपी जो मैं नहीं पहनता, वह है कोड करने की। बाकी सब मैं ही हूँ।
मैं निर्माता बन गया हूँ, संगीतकार नहीं।
ब्लॉग की सेवा में: यह खुद का अनुवाद करता है (लगभग 1 800 अनुवाद)
AI-Powered Markdown Translator अपना README 14 भाषाओं में खुद बनाता है, और यही jls42.org की सभी विदेशी भाषा वाली सामग्री तैयार करता है। व्यावहारिक रूप से: लगभग 1 800 अनूदित संस्करण ब्लॉग को पोषित करते हैं (25 लेख + 4 प्रोजेक्ट + 98 AI समाचार × 14 भाषाएँ, FR स्रोतों को छोड़कर — यानी जब मैं यह लिख रहा हूँ तब 1 778 संस्करण)। यहाँ आप जिस भी पेज को फ्रेंच के अलावा किसी और भाषा में देख रहे हैं, वह इस प्रोजेक्ट से होकर गुज़रा है।
यह उत्पाद के आंतरिक उपयोग (dogfooding) को चरम तक ले जाना है — और यह अनुवाद पर, उसी लेख में, जहाँ अनुवाद की बात हो रही है, तनाव-परीक्षण करता है। अगर आप ar, hi या ko में जो पढ़ रहे हैं वह सुसंगत है, तो इसका मतलब है कि नवीनता 1 (अनुवादोत्तर सत्यापन) का सुरक्षा-जाल काम कर रहा है; अगर अनुवाद नोट ऊपर सही तरीके से दिख रहा है, तो इसका मतलब है कि नवीनता 2 (बहु-स्थान नोट) काम कर रही है; अगर EN उद्धरण भाषाई संस्करणों में सुरक्षित हैं, तो इसका मतलब है कि नवीनता 3 ( --news मोड) भी काम कर रहा है।
निष्कर्ष : सख्त पेयर-एआई, ढीला पेयर-एआई नहीं
फीलिंग के आधार पर विकास को अच्छी वजहों से खराब नज़र से देखा जाता है। मैं ठीक उन्हीं वजहों के खिलाफ काम कर रहा हूँ। इस v1.9 से चार ठोस सीखें निकलती हैं:
-
मौन विफलताएँ नंबर एक दुश्मन हैं। AI ऐसा कोड बनाता है जो ठीक लगता है और यूनिट टेस्ट से निकल जाता है। क्लाइंट-साइड सत्यापन अनिवार्य। और उत्पादन को पुनः पढ़ने के लिए किसी दूसरी AI का इस्तेमाल करना, सिर्फ़ कोड का नहीं।
-
pre-commit hooks 10 सेकंड से कम होने चाहिए, वरना उन्हें bypass कर दिया जाता है; pre-push 30 सेकंड+ ले सकते हैं। AI आसानी से ऐसे टूल जोड़ देती है बिना उनकी लागत पर विचार किए। इसे मैन्युअल रूप से सीमित करना चाहिए, या तो योजना में या बाद में — अहम यह है कि अंत में hooks सही तरह सेट हों और रोज़मर्रा में सचमुच इस्तेमाल हों।
-
मजबूत assertion के बिना coverage = नाटक। AI 200 ऐसे टेस्ट बना सकती है जो पास हो जाएँ और कुछ टेस्ट न करें। unittest + सटीक assertions > pytest with plenty of mocks. लौटाई गई value की जाँच करें, सिर्फ़ यह नहीं कि कोड क्रैश नहीं हुआ।
-
AI (PR review) समीक्षा विकल्प नहीं है। जब मानव लेखक ने पुनरीक्षण नहीं किया हो, तब AI reviewer कोई फालतू चीज़ नहीं है — वह delegated आँख है।
ठीक तरह से किया गया vibe coding, यह भी मानना है कि हम कोड नहीं पढ़ते और आलोचनात्मक पढ़ाई उन दूसरी AIs को सौंप देते हैं जो सचमुच यह करती हैं।
यह परियोजना क्या उजागर करती है
यह v1.9 मेरे काम करने के तरीके के कई पहलुओं को दिखाती है:
- मानव की भूमिका कोड को छोड़कर पूरी श्रृंखला को कवर करती है : उत्पाद (features पर सोचना, प्राथमिकता देना), QA (वास्तविक मामलों पर परीक्षण करना, दृश्य रूप से मान्य करना), tech lead (एक LLM के साथ योजनाओं को challenge करना, reasoning extra-high में), अंतिम ग्राहक (वास्तविक उपयोग पर आकलन करना)। एकमात्र टोपी जो मैं नहीं पहनता, वह है कोड करना।
- सुरक्षा-जालों को दोगुना करना, हटाना नहीं : कम मानव-पुनरीक्षण = अधिक औज़ार-आधारित सत्यापन। यह समझौता जानबूझकर है, कठोरता की कमी नहीं। अगर मैं पुनरीक्षण हटाता हूँ, तो मुझे सुरक्षा-जाल दोगुने करने होंगे, AI पर आँख मूँदकर भरोसा नहीं।
- AI के बग खोजने के लिए AI : मौन विफलता Claude ने multi-repo व्यावहारिक परीक्षणों के दौरान पकड़ी थी। पूर्ण प्रतिनिधि-निर्माण : आलोचनात्मक पुनरीक्षण भी सौंपा जा सकता है।
- पेयर-एआई निजी समय का गुणक है : मैं इस प्रोजेक्ट को अपनी शामों और वीकेंड पर चलाता हूँ। पेयर-एआई के बिना, मैं स्पष्ट रूप से न इतना दूर जाता और न इतना तेज़। इसके साथ, मैं अपनी दूसरी जिम्मेदारियों के बीच open-source प्रोजेक्ट को औद्योगिक स्तर पर बनाए रख सकता हूँ। यही vibe coding को संभव बनाता है — डेवलपर को बदलना नहीं, बल्कि उसे वह करने देना जो वह अकेले नहीं कर सकता।
- सब कुछ फिर से बनाने के बजाय iterating : 9 versions, क्रमिक refactoring (1 function → 7 helpers), backward compatibility सुरक्षित। पेयर-एआई तेज़ी से iterate करने में मदद करती है बिना सब कुछ दोबारा लिखे।
संसाधन
- GitHub पर AI-Powered Markdown Translator
- v1.9 रिलीज़
- PR #2 — 75 commits, migration + गुणवत्ता
- पूरा CHANGELOG
- इस ब्लॉग पर प्रोजेक्ट पेज
- 2024 लेख — v1.5 (release notes शैली) — टोन की तुलना के लिए
- AWS Diagram पर गहन पड़ताल — श्रृंखला का एक और लेख
अगर आप अपने खुद के Markdown — open-source README, ब्लॉग लेख, तकनीकी दस्तावेज़ — पर AI-Powered Markdown Translator का परीक्षण करना चाहते हैं, तो कोड GitHub पर है। कुछ ही मिनटों में इंस्टॉलेशन, 4 समर्थित providers, लागत घटाने के लिए --eco मोड, स्रोत उद्धरणों को सुरक्षित रखने के लिए --news मोड, और अब v1.9 गुणवत्ता स्टैक जिसे आप पेयर-एआई में अपने खुद के प्रोजेक्ट्स के लिए template की तरह फिर से उपयोग कर सकते हैं।
अगर आप अपने निजी प्रोजेक्ट्स पर भावना के आधार पर (vibe coding) काम कर रहे हैं, तो गुणवत्ता के मामले में सबसे आसान रास्ता मत चुनिए। विश्वसनीयता ही गति की कीमत है — दोनों को एक साथ स्वीकार कीजिए।