AI-Powered Markdown Translator est un projet open-source que je maintiens depuis 2024 : un script Python qui traduit n’importe quel fichier Markdown vers 14 langues via 4 providers IA (OpenAI, Mistral AI, Claude, Gemini). Il alimente ce blog à chaque publication — toute page que vous lisez ici dans une langue autre que le français est passée par lui — et près de 1 800 versions traduites tournent grâce à lui en production.
Le 8 mai 2026, j’ai publié la v1.9, qui regroupe 75 commits et marque la plus grosse mise à jour depuis la v1.5 de 2024. Trois nouveautés produit :
- Validation post-traduction (anti-échec silencieux)
- Note de traduction multi-position (en haut, en bas ou les deux)
- Mode
--newspour préserver les citations sources EN
Mais cette v1.9 a une particularité que je veux raconter ici : tout le code a été écrit en pair-IA. Pas une ligne tapée à la main. Donc en plus des 3 nouveautés, l’article aborde le « comment » : quels garde-fous on met en place pour viser un code propre et sécurisé quand on ne relit pas soi-même ce que l’IA produit ?
Le contexte : un projet utilisé tous les jours, peu maintenu côté code
De septembre 2024 à mai 2026 : utilisation continue, maintenance par à-coups
J’avais publié un article qui détaillait le code source de la v1.5 en 2024. À l’époque, je publiais le script directement dans l’article. Aujourd’hui, l’angle a changé : ce qui compte ce n’est plus tant le code que j’écris, c’est le flux de travail qui le produit.
Entre la v1.5 publiée en septembre 2024 et janvier 2026, le projet a continué de tourner — il traduit chaque nouveau contenu de ce blog — mais le code public n’a quasiment pas bougé. Un seul commit a été poussé en 2025. Pendant tout ce temps, je faisais évoluer le code en local pour mes besoins persos — surtout les modèles, que je remplaçais au fil de leurs sorties — mais ces évolutions restaient sur ma machine. La version publique sur GitLab continuait de pointer vers les valeurs par défaut de la v1.5.
Début 2026, j’ai fait un premier effort de remise à niveau : trois releases en deux mois (v1.6 et v1.7 en deux jours début janvier, v1.8 en mars) qui ont remis le projet à jour côté fonctionnalités — modèles 2026, support Gemini, mode --eco, fichier unique, mode --news pour les citations sources. Mais toujours sans CI, sans tests automatisés, sans gates qualité — ce qui me posait un vrai problème pour pousser plus loin avec un agent IA qui code à ma place.
Le rythme d’un projet sur temps perso
Pourquoi ce décalage ? Parce que je porte ce projet sur mon temps perso. J’ai une famille, une vie en dehors de l’écran, donc l’évolution n’avance que par à-coups quand je trouve les soirées et les weekends. Je suis passionné, je passe quand même pas mal de temps sur ces sujets — je teste beaucoup, je guide les agents, je valide les résultats — mais le rythme n’est pas celui d’un projet pro.
Le pair-IA change précisément ça. Il me permet d’avancer entre deux contraintes — la passion et le dosage de la vie hors écran. Sans pair-IA, je n’irais clairement pas aussi loin ni aussi vite. Avec, je peux maintenir un projet open-source de niveau industriel sans y consacrer ma vie.
L’objectif initial : qualité + migration GitLab → GitHub
Mi-avril 2026, j’ai voulu enfin m’en occuper sérieusement. Deux objectifs simples :
- Ajouter une couche de qualité (analyse statique, tests, CI)
- Migrer le repo de GitLab vers GitHub
Pas plus. Sauf qu’avec un agent de code en pair-IA, on n’écrit jamais ce qui était prévu. La PR a fini à 75 commits, 9 837 additions, 1 982 suppressions, 58 fichiers.
| Version | Date | Apport principal |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, puis Mistral, puis Claude |
| 1.5 | sept. 2024 | Refactor clients, modèles 2024 (gpt-4o, claude-3.5-sonnet) |
| 1.6 | janv. 2026 | Modèles 2026 (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, mode --eco, fichier unique (--file) |
| 1.7 | janv. 2026 | --keep_filename, .env, code inline préservé |
| 1.8 | mars 2026 | Modèles GPT-5.4 par défaut, mode --news avec placeholders citations |
| 1.9 | mai 2026 | Validation post-traduction, note multi-position, stack qualité 14 hooks + 229 tests + revue IA |
L’effet boule de neige
Chaque outil de qualité ajouté révélait des problèmes. Codacy a remonté des duplications. SonarCloud a soulevé des code smells (signaux de code qui va mal vieillir : fonctions trop longues, paramètres non utilisés, structures alambiquées). /pr-review-toolkit a pointé des bugs cachés. À chaque remontée, l’agent corrigeait, parfois en améliorant aussi des trucs adjacents.
Le périmètre a explosé organiquement. C’est exactement ce que je voulais — moderniser le projet — mais le dosage de l’effort était dicté par les outils, pas par moi. Pour un projet en vibe coding, c’est un point clé : les outils de qualité orientent le travail autant qu’ils le vérifient.
Nouveauté 1 : la validation post-traduction (anti-échec silencieux)
L’incident : c’est l’IA qui a trouvé le bug, pendant les tests
En testant la PR sur des README de différents repos publics — un cas qu’aucune fixture ne couvrait —, l’IA a remonté ce que j’avais raté : sur certaines langues (notamment le hindi, code ISO hi), des passages restaient dans la langue source au milieu de la traduction. L’API avait renvoyé 200, le script avait écrit le fichier, mais le contenu était à moitié traduit. Et ça passait à travers la batterie de tests unitaires existante — qui ne couvrait pas ce cas réel multi-langue.
C’est exactement le genre de bug que le vibe coding peut produire et que personne ne voit. Le code semble logique, les fixtures de test ne couvrent pas le cas, l’humain ne relit pas le résultat. Sauf que là, en testant le script sur des cas réels (multi-repo), l’IA elle-même a fait ce que les fixtures ne faisaient pas.
Ce que j’en retiens : les tests pratiques multi-repo trouvent ce que les tests unitaires ratent. Et l’IA peut aussi servir à découvrir les bugs des agents IA précédents — à condition de la mettre face à des cas réels variés.
C’est à ce moment-là que j’ai compris qu’il fallait ajouter une vraie validation post-traduction. C’est cette première nouveauté que je détaille maintenant : la double couche de validation.
La double couche de validation
| Étape | Action | Si KO |
|---|---|---|
| 1️⃣ | API call provider | Exception réseau → ❌ failure |
| 2️⃣ | Whitelist par provider du finish_reason (ou stop_reason chez Claude) | Hors whitelist → ❌ failure |
| 3️⃣ | Anti-fuite : aucune fenêtre source ≥ 120 chars verbatim dans la sortie | Fenêtre source retrouvée → ❌ failure |
| 4️⃣ | langdetect.detect_langs (probas source vs target) | Source > 0,80 ET target < 0,20 → ❌ failure |
| 5️⃣ | Empty-content + ratio sortie/source (si source ≥ 500 chars) | Vide ou sortie < max(50, source/20) → ❌ failure |
| ✅ | SUCCESS | exit code 0 |
Couche 1 (déterministe) — Premier filet : vérifier le statut renvoyé par l’API. Chaque provider expose un champ finish_reason (ou stop_reason chez Claude) qui indique pourquoi le LLM a arrêté de générer. Le script maintient une whitelist par provider des statuts acceptables — la nomenclature varie (stop chez OpenAI/Mistral, STOP ou FINISH_REASON_STOP chez Gemini, end_turn ou stop_sequence chez Claude). Le code tolère aussi None par sécurité, quand le SDK ne renvoie pas ce champ. Tout autre statut — par exemple length, max_tokens ou MAX_TOKENS selon le provider, qui signalent une réponse arrêtée par la limite de tokens — déclenche un RuntimeError immédiat, sans tentative de récupération.
Second filet déterministe, plus subtil : vérifier qu’aucun passage du texte source n’apparaît verbatim dans la sortie traduite. Concrètement, on extrait des fenêtres de 120 caractères ou plus depuis le texte source ; si l’une d’elles est retrouvée telle quelle dans la sortie, c’est qu’elle n’a pas été traduite — failure. C’est précisément ce check qui a rattrapé le cas hindi : le LLM avait répondu stop (donc fin « naturelle » côté API), mais des paragraphes français étaient restés intacts dans la sortie — invisibles au filet finish_reason, détectés par le filet anti-fuite verbatim.
Couche 2 (probabiliste) — langdetect.detect_langs analyse la langue de la sortie et retourne une distribution de probabilités sur plusieurs langues candidates. On extrait la probabilité de la langue source et celle de la langue cible, puis on rejette uniquement si la prob source dépasse 0,80 et la prob target tombe sous 0,20 — un seuil délibérément conservateur pour ne pas faire de faux positifs sur du code-switching technique (mots anglais légitimes dans une traduction française, par exemple). Cette couche court-circuite pour les langues à scripts non-latins (hindi hi, arabe ar, chinois zh, japonais ja, coréen ko) où un signal de script suffisant valide déjà la sortie. Et elle ne tourne que si la sortie nettoyée fait au moins 100 caractères, pour éviter les faux positifs sur du texte trop court.
Les garde-fous quantitatifs
Au-dessus des deux couches, deux contrôles plus prosaïques mais nécessaires :
- Empty-content guard : si le provider renvoie une sortie vide alors que
finish_reasoneststop, on rejette tout de suite (sinon on écrirait un fichier vide marqué success) - Sanity ratio : seulement si le source fait au moins 500 caractères, on vérifie que la sortie n’est pas suspicieusement courte (typiquement <
max(50, source/20)). C’est un détecteur de troncation invisible, pas une règle générale de longueur
Sur Claude spécifiquement, max_tokens est passé de 4 096 à 32 768 dans la v1.9 (la modification a été faite côté code par Claude après que j’ai constaté le symptôme et demandé d’investiguer). La raison documentée dans le CHANGELOG : éviter la troncation latente sur les segments de 16 k caractères, avec une marge supplémentaire pour les langues à script non-latin (FR → JA, ZH, KO, AR, HI) qui consomment plus de tokens en sortie qu’un script latin équivalent.
Retours par statut explicite
Le pipeline fichier (translate_markdown_file()) renvoie désormais un statut explicite — success, failure ou skipped. Le CLI agrège ces statuts et termine avec un code de sortie non nul dès qu’au moins un fichier a échoué — ce qui rend l’échec exploitable par un script appelant ou par la nouvelle CI ajoutée en v1.9. Avant cette v1.9, plusieurs erreurs étaient seulement imprimées ou passaient comme une traduction réussie : le process pouvait finir en 0 alors que le fichier était absent, incomplet ou mal validé. Le statut skipped devient lui-même un signal lisible (« ignoré volontairement »), distinct de success (« traduction écrite correctement »).
📄 Extrait Python : double validation post-traduction (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNouveauté 2 : la note de traduction multi-position
Le besoin : une note discrète mais informative
Quand AI-Powered Markdown Translator écrit une traduction, il ajoute une note de traduction qui indique le modèle utilisé et la date. Avant la v1.9, cette note était systématiquement collée en bas du fichier, dans un format hérité (legacy) avec des délimiteurs visibles.
Le format collé en bas posait deux problèmes pour mes propres usages. D’abord, le lecteur n’était informé qu’à la toute fin que le contenu avait été traduit par IA — c’est mieux de prévenir dès le début, ça met une attente correcte sur le contenu. Ensuite, la note en bas de page ne mettait pas en valeur le projet de traduction qui rend tout ça possible : on lit l’article, et l’origine du flux multilingue passe inaperçue. Je voulais donc pouvoir basculer la note en haut tout en gardant la traçabilité — sans casser les usages existants. La v1.9 ajoute deux flags qui ne cassent rien :
--note_position {top,bottom,both}: haut, bas ou les deux--note_format {legacy,marker}: format hérité ou format marqueur (marker format)
Defaults rétro-compatibles : legacy + bottom. Aucune chaîne de traduction existante ne change de comportement par défaut — on active explicitement les nouveaux flags à la demande.
Le format marqueur : une carte embarquée (embed card) GitHub propre
Le format marqueur exploite un détail subtil du Markdown GitHub : les link reference definitions non utilisées sont invisibles au rendu. On peut donc encoder des métadonnées (modèle, date, source) dans un commentaire-marker positionné en haut du fichier — invisible dans le navigateur, mais conservé tel quel à la copie en brut.
GitHub en plus génère une carte embarquée (embed card) quand on partage un lien vers le fichier traduit, et cette carte affiche bien le titre du document sans pollution textuelle.
Exemple Markdown brut avec format marqueur en position top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...À l’œil, le lecteur ne voit que le titre suivi du contenu. Le marqueur ne pollue ni le rendu HTML ni la carte d’embed.
L’insertion consciente du frontmatter (frontmatter-aware)
Détail technique mais crucial : insérer une note en top ne signifie pas « insérer à la ligne 1 du fichier ». Si le fichier a un frontmatter YAML (ce qui est le cas pour ce blog), on doit insérer après le frontmatter — sinon la note casse le YAML.
J’ai donné le besoin à Claude (« insère la note après le frontmatter, pas avant — sinon tu casses le YAML »), il a sorti un helper _split_frontmatter qui détecte les fences --- ouvert/fermé. Si le fichier a une fence YAML non clôturée (cas malformé), le helper lève une RuntimeError plutôt que de produire silencieusement un fichier cassé. Le passage d’une fonction monolithique à 7 helpers purs (séparés et testables) est typique de ce que pair-IA bien guidé sait faire vite. Mon rôle ici : guide du besoin, testeur, client final qui valide le résultat. Pas coder. Sur ce projet je porte plusieurs casquettes — sauf celle d’écrire le code, qui revient à Claude.
| Position | Format | Cas d’usage typique |
|---|---|---|
top | marker | Articles blog (note discrète, embed card propre) |
top | legacy | Doc interne où la traçabilité visible importe |
bottom | marker | README open-source (cohérent avec footer) |
bottom | legacy | Defaults — backward compatible |
both | marker | Articles longs où top + bottom rassurent |
both | legacy | Cas legacy avec exigence de double traçabilité |
📄 Extrait Python : helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")Nouveauté 3 : le mode --news pour préserver les citations sources EN
Le problème : traduire sans casser les citations
Quand j’écris des articles ia-actualites pour ce blog (multi-source IA news quotidiennes/hebdomadaires), je cite régulièrement des tweets, billets de blog, annonces de version en anglais — souvent plusieurs par article. Si la traduction touche aux citations, elles deviennent fausses.
Une citation traduite est une citation altérée. Dans toutes les versions linguistiques (EN, DE, JA, etc.), on veut garder l’anglais original des citations — c’est une exigence de fidélité aux sources — accompagné du drapeau de la langue cible et d’une traduction en italique pour le confort de lecture.
La solution : placeholders <NEWSQUOTE id="N"/>
| Étape | Action |
|---|---|
| 1️⃣ | Markdown source FR avec citations EN en entrée |
| 2️⃣ | Pré-traitement : extraction des citations EN, remplacement par placeholders <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, etc. |
| 3️⃣ | Traduction API (FR → target_lang) — les citations EN originales ne sont jamais envoyées au LLM, seuls les placeholders le sont (préservés tel quel) |
| 4️⃣ | Post-traitement : restauration des placeholders avec les citations EN originales intactes + insertion du drapeau de la langue cible |
| 5️⃣ | Validation post-traduction : tous les placeholders ont-ils été restaurés ? |
| ✅ | Sortie cible avec citations EN préservées |
| ❌ | Échec si placeholder non restauré ou citation altérée |
Le mode --news repose sur ce principe : un pré-traitement extrait toutes les citations EN, les remplace par des placeholders type <NEWSQUOTE id="0"/>, traduit le reste, restaure les placeholders intacts.
Le mapping LANG_FLAGS adapte le drapeau à la target_lang (15 langues couvertes) : 🇬🇧 pour l’anglais, 🇩🇪 pour l’allemand, 🇪🇸 pour l’espagnol, 🇮🇹 pour l’italien, 🇵🇹 pour le portugais, 🇳🇱 pour le néerlandais, 🇵🇱 pour le polonais, 🇸🇪 pour le suédois, 🇷🇴 pour le roumain, 🇸🇦 pour l’arabe, 🇮🇳 pour le hindi, 🇯🇵 pour le japonais, 🇰🇷 pour le coréen, 🇨🇳 pour le chinois, 🇫🇷 pour le français.
La validation post-traduction vérifie que tous les placeholders sont restaurés intacts. L’erreur n’est pas une « fuite EN » — l’EN est voulu — mais un placeholder non restauré ou une citation altérée.
Cas d’usage actuels et perspectives
Aujourd’hui, j’utilise --news exclusivement sur les articles ia-actualites du blog. À terme, ça pourrait s’étendre à n’importe quel article qui mêle prose française et citations sources EN — interviews, retours d’expérience qui citent des articles de recherche en anglais, transcriptions de présentations de conférence.
Sans relire le code : pourquoi il faut doubler les garde-fous
« Je ne lis pas le code. »
Je ne relis rien. Je regarde parfois un diff vite fait — c’est rare, et c’est uniquement quand Claude ne s’en sort pas tout seul sur un point. Voici le flux que j’utilise au quotidien et qui a produit la v1.9 : Claude Code (Opus, exclusivement) tape le code. Codex prend le relais quand Opus bloque ou que la fenêtre d’usage est saturée. GPT-5.5 en reasoning extra-high challenge les plans avant exécution. /pr-review-toolkit:review-pr relit la PR avant chaque merge. Mon rôle s’arrête à valider les directions et définir les garde-fous.
Ce mode de développement — développement au feeling (vibe coding) intégral — n’est pas un manque de rigueur. C’est un compromis explicite : moins de relecture humaine, plus de validation outillée. Les 3 nouveautés v1.9 que je viens de présenter ont toutes été produites dans ce flux. Et c’est précisément parce qu’on ne relit pas le code qu’il faut doubler les garde-fous techniques — pas les supprimer.
Voici les deux garde-fous mis en place pour rendre ce mode de développement viable en production : une stack qualité automatisée (Garde-fou 1) et une revue assistée IA en flux multi-modèle (Garde-fou 2).
Garde-fou 1 : la stack qualité automatisée (14 hooks + tests pratiques)
Vue d’ensemble
| Filet | Outils | Coût typique | Bloquant si échec |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hooks), detect-secrets, Lizard CCN | < 10 s | Oui |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Oui, sauf pip-audit en reporting initial |
| CI externe | SonarCloud, Codacy, CodeFactor | en parallèle | Non bloquant local, badges PR |
Chiffres v1.9 : 14 hooks, 229 tests unittest stdlib, ~98 % de couverture sur le nouveau code v1.9, 11 badges SonarCloud, 3 plateformes externes.
Pre-commit : le filet rapide
| # | Outil | Version | Rôle |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Lint shell |
| 2 | ruff (lint) | 0.8.6 | Lint Python |
| 3 | ruff (format) | 0.8.6 | Formatage Python |
| 4 | prettier | 3.1.0 | Formatage Markdown / JSON / YAML |
| 5 | trailing-whitespace | 5.0.0 | Suppression des espaces de fin de ligne |
| 6 | end-of-file-fixer | 5.0.0 | Newline finale obligatoire |
| 7 | check-yaml | 5.0.0 | Validation syntaxe YAML |
| 8 | check-toml | 5.0.0 | Validation syntaxe TOML |
| 9 | check-added-large-files | 5.0.0 | Bloque les gros binaires ajoutés par accident |
| 10 | check-merge-conflict | 5.0.0 | Détection des marqueurs de conflit Git |
| 11 | check-executables-have-shebangs | 5.0.0 | Vérifie que les exécutables ont un shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Vérifie que les scripts à shebang sont exécutables |
| 13 | detect-secrets | 1.5.0 | Détection de clés API et secrets |
| 14 | check-complexity (Lizard) | local | Plafond de complexité cyclomatique sur le nouveau code |
Total mesuré : environ 2 à 3 secondes sur l’ensemble du repo (à chaud, pre-commit run --all-files chronométré à ~2,4 s). Sur un commit moyen qui ne touche que quelques fichiers, c’est encore plus rapide. La règle de pouce que j’applique : au-dessus de 10 s, les développeurs contournent (le pair-IA aussi) — il faut donc garder ce filet rapide en permanence.
Pre-push : le filet lourd
- mypy en mode lax : pas de strict total (le code historique de translate.py ne passerait pas), mais une vérif de progression sur le nouveau code
- Opengrep SAST :
p/security-audit p/default p/python— environ 30 secondes pour scanner injections, eval, désérialisation non-sûre - pip-audit wrappé par
scripts/check-pip-audit.sh: capture la sortie JSON, classifie côté shell les erreurs de transport (réseau, PyPI down) pour ne pas confondre vulnérabilité et indisponibilité, et reporte les vulnérabilités. En mode reporting initial pour la v1.9 (warn + exit 0) — à durcir en bloquant après une PR de bump des dépendances obsolètes. - unittest discovery :
python -m unittest discoversurtests/puisscripts/tests/— 229 tests, environ 8 secondes en local
CI externe : SonarCloud + Codacy + CodeFactor
Le workflow .github/workflows/sonarcloud.yml (project key jls42_ai-powered-markdown-translator) tourne sur chaque PR. 11 badges SonarCloud affichés sur le README : Quality Gate, Security/Reliability/Maintainability Rating, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC.
Pourquoi la redondance Codacy + SonarCloud + CodeFactor ? Parce que chacun voit des choses différentes. Codacy a remonté des duplications que SonarCloud n’avait pas signalées. SonarCloud a remonté des signaux de mauvaise qualité (les fameux code smells) que Codacy laissait passer. CodeFactor a remonté des problèmes de complexité que les deux autres ignoraient. Aucun n’aurait suffi seul. Le coût marginal d’une plateforme supplémentaire est nul (badge gratuit, intégration de 5 minutes), donc on multiplie les angles.
Tests : unittest stdlib (pas pytest)
229 tests, 0 régression sur les 6 mois de la PR, ~98 % de couverture sur le nouveau code v1.9.
Détail typique :
test_silent_failure.py: 97 tests ciblant la double validationtest_orchestration.py: 79 tests sur le pipeline orchestrateurtest_translation_note_position.py: 38 tests sur la matrice position × formattest_audit_verdict.py: 15 tests sur le wrapper pip-audit (dansscripts/tests/)
Note d’honnêteté : la couverture ~98 % concerne le nouveau code v1.9 — pas l’ensemble historique de translate.py, qui contient encore quelques fonctions héritées peu couvertes par la nouvelle batterie de tests. Je le mentionne explicitement parce qu’annoncer « 98 % de couverture » sur un projet entier serait trompeur.
Choix discutable mais assumé : exécuteur de tests unittest (stdlib), pas pytest. Le préfixe test_ est par habitude, mais c’est unittest qui exécute. Pourquoi ? Sur un projet en vibe coding, chaque dépendance ajoutée = chaque dépendance que l’IA peut mal utiliser. La simplicité est un objectif. unittest est dans la bibliothèque standard de Python, zéro installation, zéro plugin.
Tests pratiques : multi-repo + utilisation interne du produit (dogfooding) + vérification du rendu visuel
Les 229 tests unittest ne suffisent pas. J’ajoute trois couches de test pratique :
1. Multi-repo — tester le script sur plusieurs repos publics avec des README en différents formats. Ça révèle des cas limites que les fixtures ne couvrent pas — un README avec 8 niveaux de heading, un autre avec des shortcodes hérités, un troisième avec du code embarqué exotique. C’est dans cette phase que l’incident silent-failure de la Nouveauté 1 a été découvert.
2. Dogfooding sur le blog — jls42.org est traduit par le script lui-même. Chaque article publié est un test live en production. Si un cas limite passe à travers les tests unitaires, il sortira ici, sur la page que vous lisez. C’est le test ultime — ce qui est en ligne, c’est ce que le projet a produit.
3. Test du rendu visuel — je vérifie que les traductions rendues s’affichent correctement, soit dans le navigateur (page web finale), soit directement dans VSCode via un plugin de prévisualisation Markdown. L’idée : ne pas se contenter d’un Markdown syntaxiquement valide, mais voir le rendu réel. Les rendus visuels remontent des bugs d’apparence (tableaux cassés, code blocks malformés, frontmatter mal interprété) que les tests texte ne voient pas.
Les IAs participent à ces tests aussi. /pr-review-toolkit exécute le code en environnement de test, et l’usage en pair-IA inclut systématiquement des passes de validation visuelle (« vérifie que la traduction allemande de la page X s’affiche bien »).
📄 Extrait .pre-commit-config.yaml (hooks pre-commit principaux)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Extrait scripts/check-security-sast.sh
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Extrait .github/workflows/sonarcloud.yml
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Garde-fou 2 : la revue assistée IA + le flux multi-modèle
Précision de vocabulaire : quand je parle de Claude Opus dans cette section, je parle du modèle que j’utilise pour développer la v1.9 — pas du modèle qu’AI-Powered Markdown Translator utilise pour traduire. Le projet lui-même supporte 4 providers (OpenAI, Mistral AI, Claude, Gemini) et n’importe quel modèle (Sonnet, Haiku, Mistral Large, Gemini 3 Pro, etc.). Côté développement, je verrouille sur Opus. Côté usage à l’exécution, le projet reste agnostique.
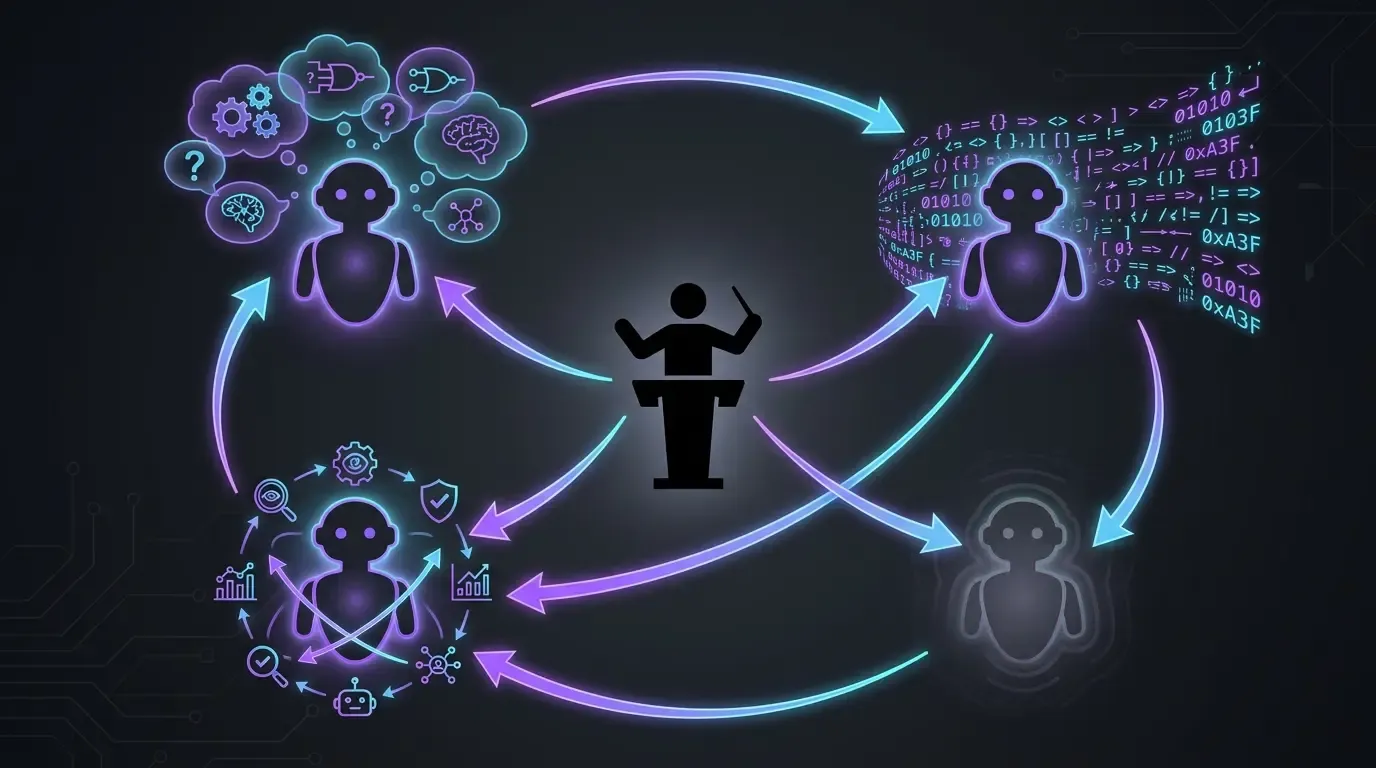
Le flux de travail réel : 4 modèles, 4 rôles (pour développer)
- Claude Code en Opus, exclusivement (anthropic) : exécution principale. Lit le contexte, écrit le code, applique les corrections. Pas de Sonnet, pas de Haiku, pas de fast mode. Sur ce projet, je veux le modèle haut-de-gamme à chaque fois — l’idée est simple : on s’assure d’avoir le meilleur pour viser le meilleur résultat possible.
- OpenAI Codex en solution de repli (fallback) : utilisé dans deux cas précis :
- Quand Opus se plante sur un sujet (rare mais existant — par exemple sur des corrections demandées par les agents externes type Codacy ou SonarCloud, Claude ne converge parfois pas et je bascule le sujet sur Codex pour débloquer)
- Quand la fenêtre d’usage Anthropic est saturée. Codex permet de ne pas perdre l’élan en attendant le reset de quota.
- GPT-5.5 reasoning extra-high (
xhigh) : challenge des plans avant exécution. Avant de laisser Claude Code attaquer un sujet, je passe le plan à GPT-5.5 en reasoning extra-high. Il pose les bonnes questions, soulève les angles morts. Ça évite de partir dans une mauvaise direction qu’il faudra rattraper plus tard. /pr-review-toolkit:review-pr(skill plugin Claude Code) : revue avant merge avec des agents spécialisés (sécurité, qualité, tests, commentaires, conception des types). Le skill tourne sur la PR avant que je merge — c’est le dernier filet IA avant que le code n’entre dansmain.
Aucun de ces modèles ne suffit seul. Chacun joue un rôle différent — l’exécutant haut-de-gamme, le suppléant de capacité, le challenger de plans, le relecteur (reviewer) multi-angles.
/pr-review-toolkit : ce que je n’aurais pas vu
Tout. Je ne regarde pas le code. Le skill remonte tout — bugs cachés, problèmes de sécurité, incohérences de tests, tests qui passent mais ne testent rien.
Sur la PR #2 (75 commits, 9 837 additions, 1 982 suppressions, 58 fichiers), un humain seul aurait skip 80 % de la PR par fatigue. Le skill ne skip rien. Il lit chaque diff, chaque test, chaque commentaire. Et surtout, il challenge — il refuse les patterns qu’il identifie comme mauvais, et il propose des alternatives.
L’humain comme chef d’orchestre, pas comme musicien
Mon rôle couvre toute la chaîne — sauf l’écriture du code. Je joue les casquettes de chef de produit (réfléchir aux features, prioriser, arbitrer), QA (tester sur des cas réels, valider visuellement le rendu), tech lead (challenger les plans avec GPT-5.5 reasoning extra-high), client final (juger le résultat sur ma propre expérience d’usage au quotidien sur le blog). La seule casquette que je ne porte pas, c’est celle de coder. Le reste, c’est moi.
Je suis devenu producteur, pas musicien.
Au service du blog : il se traduit lui-même (près de 1 800 traductions)
AI-Powered Markdown Translator génère son propre README en 14 langues, et c’est lui qui produit toutes les versions étrangères des contenus de jls42.org. Concrètement : près de 1 800 versions traduites alimentent le blog (25 articles + 4 projets + 98 actualités IA × 14 langues, hors sources FR — soit 1 778 versions au moment où j’écris). Toute page que vous parcourez ici dans une langue autre que le français est passée par ce projet.
C’est de l’utilisation interne du produit (dogfooding) poussée à l’extrême — et ça stresse-teste la traduction sur l’article qui parle de la traduction. Si ce que vous lisez en ar, hi ou ko est cohérent, c’est que le filet de la Nouveauté 1 (validation post-traduction) tient ; si la note de traduction s’affiche correctement en haut, c’est que la Nouveauté 2 (note multi-position) fonctionne ; si les citations EN sont préservées dans les versions linguistiques, c’est que la Nouveauté 3 (mode --news) marche aussi.
Bilan : pair-IA rigoureux, pas pair-IA bâclé
Le développement au feeling a mauvaise presse pour de bonnes raisons. C’est précisément contre elles que je travaille. Quatre leçons concrètes ressortent de cette v1.9 :
-
Les échecs silencieux sont l’ennemi numéro un. L’IA produit du code qui semble OK et passe à travers les tests unitaires. Validation côté client systématique. Et utiliser une autre IA pour relire la production réelle, pas seulement le code.
-
Hooks pre-commit < 10 s sinon contournés ; pre-push peuvent prendre 30 s+. L’IA ajoute volontiers des outils sans considérer leur coût. À cadrer manuellement, soit dans le plan, soit après coup — l’important est qu’au final les hooks soient bien réglés et effectivement utilisés au quotidien.
-
Couverture sans assertion forte = théâtre. L’IA peut générer 200 tests qui passent et qui ne testent rien. unittest + assertions précises > pytest avec mocks à la pelle. Vérifier la valeur retournée, pas juste que le code n’a pas crashé.
-
La revue (PR review) IA n’est pas une option. Quand l’auteur humain n’a pas relu, le relecteur IA n’est pas du gadget — c’est l’œil délégué.
Le vibe coding bien fait, c’est aussi accepter qu’on ne lit pas le code et déléguer la lecture critique à d’autres IAs qui le font vraiment.
Ce que ce projet révèle
Cette v1.9 illustre plusieurs aspects de ma façon de travailler :
- Le rôle humain couvre toute la chaîne sauf le code : produit (réfléchir aux features, prioriser), QA (tester sur des cas réels, valider visuellement), tech lead (challenger les plans avec un LLM en reasoning extra-high), client final (juger sur l’usage réel). La seule casquette que je ne porte pas, c’est coder.
- Doubler les filets, pas les supprimer : moins de relecture humaine = plus de validation outillée. Compromis assumé, pas manque de rigueur. Si je supprime la relecture, je dois doubler les filets, pas faire confiance aveuglément à l’IA.
- L’IA pour découvrir les bugs de l’IA : l’échec silencieux a été trouvé par Claude pendant les tests pratiques multi-repo. Délégation complète : on peut aussi déléguer la relecture critique.
- Le pair-IA comme multiplicateur sur temps perso : je porte ce projet sur mes soirées et weekends. Sans pair-IA, je n’irais clairement pas aussi loin ni aussi vite. Avec, je peux maintenir un projet open-source au niveau industriel en marge de mes autres obligations. C’est ce que le vibe coding rend possible — pas remplacer le développeur, mais lui permettre de faire ce qu’il ne pourrait pas seul.
- Itérer plutôt que tout refaire : 9 versions, refactoring incrémental (1 fonction → 7 helpers), rétrocompatibilité préservée. Le pair-IA aide à itérer vite sans tout réécrire.
Ressources
- AI-Powered Markdown Translator sur GitHub
- Release v1.9
- PR #2 — 75 commits, migration + qualité
- CHANGELOG complet
- Page projet sur ce blog
- Article 2024 — v1.5 (style release notes) — pour comparer le ton
- Deep Dive AWS Diagram — autre article de la série
Si vous voulez tester AI-Powered Markdown Translator sur vos propres Markdown — README open-source, articles de blog, doc technique —, le code est sur GitHub. Installation en quelques minutes, 4 providers supportés, mode --eco pour réduire le coût, mode --news pour préserver les citations sources, et désormais une stack qualité v1.9 que vous pouvez réutiliser comme template pour vos propres projets en pair-IA.
Si vous développez au feeling (vibe coding) vos projets perso, n’allez pas au plus simple côté qualité. La fiabilité est le prix de la rapidité — assumez les deux ensemble.