ai-powered-markdown-translatorPrzetłumaczony artykuł z fr na pl z gpt-5.4-mini.
AI-Powered Markdown Translator to projekt open-source, który utrzymuję od 2024 roku: skrypt Python, który tłumaczy dowolny plik Markdown na 14 języków za pomocą 4 dostawców AI (OpenAI, Mistral AI, Claude, Gemini). Napędza ten blog przy każdej publikacji — każda strona, którą tutaj czytasz w języku innym niż francuski, przeszła przez niego — i blisko 1 800 przetłumaczonych wersji działa dzięki niemu w produkcji.
8 maja 2026 opublikowałem v1.9, która zbiera 75 commitów i oznacza największą aktualizację od v1.5 z 2024 roku. Trzy nowości produktowe:
- Walidacja po tłumaczeniu (ochrona przed cichą porażką)
- Wielopozycyjna notatka o tłumaczeniu (na górze, na dole albo w obu miejscach)
- Tryb
--newsdo zachowania cytatów źródłowych EN
Ale ta v1.9 ma jedną szczególną cechę, o której chcę tu opowiedzieć: cały kod został napisany w duecie z AI. Ani jednej linii nie wpisałem ręcznie. Więc oprócz 3 nowości, artykuł porusza też „jak”: jakie zabezpieczenia trzeba wdrożyć, żeby celować w czysty i bezpieczny kod, gdy sam nie przeglądasz tego, co produkuje AI?
Kontekst: projekt używany codziennie, a po stronie kodu utrzymywany nieregularnie
Od września 2024 do maja 2026: ciągłe użycie, utrzymanie zrywami
Opublikowałem artykuł, który szczegółowo opisywał kod źródłowy v1.5 w 2024 roku. W tamtym czasie publikowałem skrypt bezpośrednio w artykule. Dziś kąt widzenia się zmienił: liczy się już nie tyle kod, który piszę, co przepływ pracy, który go wytwarza.
Między v1.5 opublikowaną we wrześniu 2024 a styczniem 2026 projekt dalej działał — tłumaczy każdy nowy wpis na tym blogu — ale publiczny kod prawie wcale się nie zmieniał. W 2025 roku wypchnięto tylko jeden commit. Przez cały ten czas rozwijałem kod lokalnie na własne potrzeby — przede wszystkim modele, które wymieniałem w miarę pojawiania się nowych wydań — ale te zmiany zostawały na mojej maszynie. Publiczna wersja na GitLabie nadal wskazywała domyślne wartości z v1.5.
Na początku 2026 roku wykonałem pierwszy krok porządkujący: trzy releasy w dwa miesiące (v1.6 i v1.7 w dwa dni na początku stycznia, v1.8 w marcu), które zaktualizowały projekt po stronie funkcji — modele 2026, obsługa Gemini, tryb --eco, pojedynczy plik, tryb --news dla cytatów źródłowych. Ale nadal bez CI, bez automatycznych testów, bez bramek jakości — co stanowiło dla mnie realny problem, jeśli chciałem pójść dalej z agentem AI, który koduje za mnie.
Tempo projektu realizowanego po godzinach
Dlaczego tak się to rozjeżdżało? Bo ten projekt prowadzę w czasie prywatnym. Mam rodzinę, życie poza ekranem, więc rozwój posuwa się do przodu tylko skokami, kiedy znajduję wieczory i weekendy. Jestem pasjonatem, spędzam mimo wszystko sporo czasu na tych tematach — dużo testuję, prowadzę agentów, waliduję wyniki — ale tempo nie jest jak w projekcie zawodowym.
Pair-IA zmienia właśnie to. Pozwala mi iść naprzód między dwoma ograniczeniami — pasją i dawkowaniem życia poza ekranem. Bez pair-IA zdecydowanie nie zaszedłbym tak daleko ani tak szybko. Z nim mogę utrzymywać projekt open-source na poziomie przemysłowym, nie poświęcając mu całego życia.
Początkowy cel: jakość + migracja GitLab → GitHub
W połowie kwietnia 2026 chciałem wreszcie zająć się tym porządnie. Dwa proste cele:
- Dodać warstwę jakości (analiza statyczna, testy, CI)
- Przenieść repo z GitLaba na GitHub
Nic więcej. Tyle że z agentem kodującym w duecie z AI nigdy nie pisze się dokładnie tego, co było zaplanowane. PR skończył na 75 commitach, 9 837 dodatkach, 1 982 usunięciach, 58 plikach.
| Wersja | Data | Główna zmiana |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, potem Mistral, potem Claude |
| 1.5 | wrz. 2024 | Refaktoryzacja klientów, modele 2024 (gpt-4o, claude-3.5-sonnet) |
| 1.6 | sty. 2026 | Modele 2026 (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, tryb --eco, pojedynczy plik (--file) |
| 1.7 | sty. 2026 | --keep_filename, .env, zachowany kod inline |
| 1.8 | mar. 2026 | Domyślne modele GPT-5.4, tryb --news z placeholderami cytatów |
| 1.9 | maj 2026 | Walidacja po tłumaczeniu, wielopozycyjna notatka, stos jakości: 14 hooków + 229 testów + recenzja AI |
Efekt kuli śnieżnej
Każde dodane narzędzie jakości ujawniało problemy. Codacy zgłaszał duplikacje. SonarCloud podnosił code smells (sygnały, że kod będzie się źle starzał: zbyt długie funkcje, nieużywane parametry, pokręcone struktury). /pr-review-toolkit wskazał ukryte bugi. Przy każdym zgłoszeniu agent poprawiał problem, czasem ulepszając też rzeczy poboczne.
Zakres rozrósł się organicznie. Dokładnie tego chciałem — unowocześnić projekt — ale tempo wysiłku było dyktowane przez narzędzia, nie przeze mnie. W projekcie robionym w vibe coding to kluczowa sprawa: narzędzia jakościowe kierują pracą równie mocno, jak ją weryfikują.
Nowość 1: walidacja po tłumaczeniu (ochrona przed cichą porażką)
Incydent: to AI znalazło błąd, podczas testów
Podczas testowania PR na README z różnych publicznych repo — przypadek, którego nie obejmowała żadna fixture — AI zgłosiło to, co przeoczyłem: w niektórych językach (zwłaszcza hindi, kod ISO hi) fragmenty pozostawały w języku źródłowym pośrodku tłumaczenia. API zwróciło 200, skrypt zapisał plik, ale treść była przetłumaczona tylko częściowo. I to przechodziło przez istniejący zestaw testów jednostkowych — który nie pokrywał tego realnego, wielojęzycznego przypadku.
To dokładnie taki błąd, jaki vibe coding potrafi wygenerować i którego nikt nie widzi. Kod wygląda logicznie, fixture testowe nie obejmują przypadku, człowiek nie przegląda wyniku. A tu, testując skrypt na realnych przypadkach (multi-repo), samo AI zrobiło to, czego nie robiły fixture.
Wyciągam z tego taki wniosek: praktyczne testy multi-repo znajdują to, co omijają testy jednostkowe. I AI może też służyć do wykrywania błędów wcześniejszych agentów AI — pod warunkiem, że postawi się je wobec zróżnicowanych, realnych przypadków.
To właśnie wtedy zrozumiałem, że trzeba dodać prawdziwą walidację po tłumaczeniu. To pierwsza nowość, którą teraz opisuję: podwójna warstwa walidacji.
Podwójna warstwa walidacji
| Krok | Działanie | Jeśli nie OK |
|---|---|---|
| 1️⃣ | Wywołanie API providera | Wyjątek sieciowy → ❌ failure |
| 2️⃣ | Biała lista statusów finish_reason dla providera (lub stop_reason w Claude) | Poza białą listą → ❌ failure |
| 3️⃣ | Antywyciek: żadna sekwencja źródłowa ≥ 120 znaków dosłownie w wyjściu | Znaleziono sekwencję źródłową → ❌ failure |
| 4️⃣ | langdetect.detect_langs (prawdopodobieństwa source vs target) | Source > 0,80 I target < 0,20 → ❌ failure |
| 5️⃣ | Strażnik pustej treści + stosunek wyjścia do źródła (jeśli source ≥ 500 znaków) | Pusto lub wyjście < max(50, source/20) → ❌ failure |
| ✅ | SUCCESS | exit code 0 |
Warstwa 1 (deterministyczna) — Pierwsza siatka bezpieczeństwa: sprawdzenie statusu zwróconego przez API. Każdy provider udostępnia pole finish_reason (albo stop_reason w Claude), które mówi, dlaczego LLM przestał generować. Skrypt utrzymuje białą listę statusów akceptowalnych dla każdego providera — nazewnictwo się różni (stop w OpenAI/Mistral, STOP lub FINISH_REASON_STOP w Gemini, end_turn lub stop_sequence w Claude). Kod toleruje też None na wszelki wypadek, gdy SDK nie zwraca tego pola. Każdy inny status — na przykład length, max_tokens lub MAX_TOKENS zależnie od providera, które sygnalizują odpowiedź zatrzymaną przez limit tokenów — uruchamia natychmiastowy RuntimeError, bez próby odzyskiwania.
Druga deterministyczna siatka, bardziej subtelna: sprawdzić, czy żaden fragment tekstu źródłowego nie pojawia się dosłownie w przetłumaczonym wyjściu. Konkretnie wycinane są okna o długości 120 znaków lub więcej z tekstu źródłowego; jeśli którekolwiek z nich zostanie znalezione 1:1 w wyjściu, oznacza to, że nie zostało przetłumaczone — failure. To właśnie ten check wyłapał przypadek hindi: LLM odpowiedziało stop (czyli zakończyło „naturalnie” po stronie API), ale francuskie akapity pozostały nietknięte w wyjściu — niewidoczne dla siatki finish_reason, wykryte przez siatkę antywycieku verbatim.
Warstwa 2 (probabilistyczna) — langdetect.detect_langs analizuje język wyjścia i zwraca rozkład prawdopodobieństw dla kilku kandydackich języków. Wyciągane jest prawdopodobieństwo języka źródłowego i języka docelowego, a wynik jest odrzucany tylko wtedy, gdy prawdopodobieństwo source przekracza 0,80 i prawdopodobieństwo target spada poniżej 0,20 — próg celowo konserwatywny, żeby nie generować fałszywych alarmów przy technicznym code-switchingu (na przykład legalnych angielskich słowach w tłumaczeniu francuskim). Ta warstwa jest omijana dla języków zapisanych pismami nielatynickimi (hindi hi, arabski ar, chiński zh, japoński ja, koreański ko), gdzie sam wystarczający sygnał skryptu już potwierdza wynik. I uruchamia się tylko wtedy, gdy oczyszczone wyjście ma co najmniej 100 znaków, żeby uniknąć fałszywych alarmów przy zbyt krótkim tekście.
Liczbowe zabezpieczenia
Ponad tymi dwiema warstwami są jeszcze dwa bardziej przyziemne, ale konieczne kontrole:
- Strażnik pustej treści: jeśli provider zwraca pusty wynik, a
finish_reasonma wartośćstop, odrzucamy wynik od razu (inaczej zapisany zostałby pusty plik oznaczony jako success) - Wskaźnik zdrowego rozsądku: tylko jeśli source ma co najmniej 500 znaków, sprawdzamy, czy wyjście nie jest podejrzanie krótkie (zwykle <
max(50, source/20)). To wykrywacz niewidocznego ucięcia, a nie ogólna reguła długości
W przypadku Claude konkretnie max_tokens wzrosło z 4 096 do 32 768 w v1.9 (zmiana została wykonana po stronie kodu przez Claude’a, gdy zauważyłem objaw i poprosiłem o zbadanie sprawy). Powód udokumentowany w CHANGELOG-u: uniknięcie ukrytego ucinania na segmentach 16 k znaków, z dodatkowym marginesem dla języków zapisanych nielatynickim pismem (FR → JA, ZH, KO, AR, HI), które zużywają więcej tokenów w wyjściu niż równoważne pismo łacińskie.
Zwroty przez jawny status
Pipeline pliku (translate_markdown_file()) zwraca teraz jawny status — success, failure albo skipped. CLI agreguje te statusy i kończy się niezerowym kodem wyjścia, gdy choć jeden plik zakończył się niepowodzeniem — dzięki temu błąd może zostać wykorzystany przez wywołujący skrypt albo przez nowy CI dodany w v1.9. Przed tą v1.9 kilka błędów było tylko wypisywanych albo przechodziło jak udane tłumaczenie: proces mógł zakończyć się z 0, mimo że plik był nieobecny, niekompletny albo źle zweryfikowany. Status skipped sam staje się czytelnym sygnałem („celowo zignorowano”), odrębnym od success („tłumaczenie zapisane poprawnie”).
📄 Fragment Pythona: podwójna walidacja po tłumaczeniu (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNowość 2: wielopozycyjna notatka o tłumaczeniu
Potrzeba: dyskretna, ale informacyjna notatka
Gdy AI-Powered Markdown Translator zapisuje tłumaczenie, dodaje notatkę o tłumaczeniu, która wskazuje użyty model i datę. Przed v1.9 ta notatka była zawsze doklejana na dole pliku, w odziedziczonym (legacy) formacie z widocznymi separatorami.
Format doklejany na dole sprawiał mi w praktyce dwa problemy. Po pierwsze, czytelnik dowiadywał się dopiero na samym końcu, że treść została przetłumaczona przez AI — lepiej uprzedzić od początku, bo ustawia to właściwe oczekiwania wobec treści. Po drugie, przypis na dole strony nie eksponował projektu tłumaczeniowego, który to wszystko umożliwia: czytasz artykuł, a pochodzenie wielojęzycznego strumienia umyka uwadze. Chciałem więc móc przenieść notatkę na górę, zachowując jednocześnie śledzenie pochodzenia — bez psucia istniejących zastosowań. v1.9 dodaje dwa flagi, które niczego nie psują:
--note_position {top,bottom,both}: góra, dół albo oba miejsca--note_format {legacy,marker}: format odziedziczony lub format markera (marker format)
Wsteczne domyślne ustawienia: legacy + bottom. Żaden istniejący ciąg tłumaczeniowy nie zmienia domyślnego zachowania — nowe flagi włączane są jawnie na żądanie.
Format markera: czysta karta osadzona (embed card) GitHuba
Format markera wykorzystuje subtelny szczegół Markdowna GitHuba: link reference definitions nieużyte w treści są niewidoczne w renderze. Można więc zakodować metadane (model, data, źródło) w komentarzu-markerze umieszczonym na górze pliku — niewidocznym w przeglądarce, ale zachowanym 1:1 przy kopiowaniu surowego tekstu.
GitHub dodatkowo generuje kartę osadzoną (embed card), gdy udostępniasz link do przetłumaczonego pliku, a ta karta pokazuje tytuł dokumentu bez zanieczyszczenia tekstem.
Surowy przykład Markdown z formatem markera w pozycji top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...Na oko czytelnik widzi tylko tytuł, a potem treść. Marker nie zanieczyszcza ani renderu HTML, ani karty embed.
Świadome wstawianie frontmatteru (frontmatter-aware)
Drobny, ale kluczowy szczegół techniczny: wstawienie notatki za pomocą top nie oznacza „wstaw na linię 1 pliku”. Jeśli plik ma frontmatter YAML (a w tym blogu tak właśnie jest), trzeba wstawić po frontmatterze — inaczej notatka psuje YAML.
Dałem Claude wymaganie („wstaw notatkę po frontmatterze, nie przed — inaczej zepsujesz YAML”), a on wygenerował helper _split_frontmatter, który wykrywa otwarte/zamknięte fences ---. Jeśli plik ma niezamknięty fence YAML (przypadek wadliwy), helper rzuca RuntimeError zamiast po cichu produkować uszkodzony plik. Przejście z funkcji monolitycznej do 7 czystych helperów (oddzielnych i testowalnych) jest typowe dla tego, co dobrze poprowadzony pair-IA potrafi zrobić szybko. Moja rola tutaj: guide od wymagań, tester, klient końcowy, który zatwierdza wynik. Nie koduję. W tym projekcie noszę kilka czapek — poza tą od pisania kodu, bo to robi Claude.
| Pozycja | Format | Typowy przypadek użycia |
|---|---|---|
top | marker | Artykuły blogowe (dyskretna nota, estetyczna embed card) |
top | legacy | Wewnętrzna dokumentacja, gdzie liczy się widoczna śledzalność |
bottom | marker | README open-source (spójne ze stopką) |
bottom | legacy | Domyślne — zgodne wstecz |
both | marker | Długie artykuły, gdzie góra + dół uspokajają |
both | legacy | Przypadki legacy z wymogiem podwójnej śledzalności |
📄 Fragment Pythona : helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")Nowość 3: tryb --news do zachowania cytatów źródłowych EN
Problem: tłumaczyć bez psucia cytatów
Gdy piszę dla tego bloga artykuły ia-actualites (codzienne/tygodniowe newsy AI z wielu źródeł), regularnie cytuję tweety, wpisy na blogach, ogłoszenia wersji po angielsku — często po kilka na artykuł. Jeśli tłumaczenie dotknie cytatów, stają się fałszywe.
Przetłumaczony cytat jest cytatem zniekształconym. We wszystkich wersjach językowych (EN, DE, JA itd.) chcemy zachować oryginalny angielski cytatów — to wymóg wierności źródłom — wraz z flagą języka docelowego i tłumaczeniem kursywą dla wygody czytania.
Rozwiązanie: placeholdery <NEWSQUOTE id="N"/>
| Etap | Działanie |
|---|---|
| 1️⃣ | Źródłowy Markdown FR z cytatami EN jako wejście |
| 2️⃣ | Pre-processing: ekstrakcja cytatów EN, zastąpienie ich placeholderami <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, itd. |
| 3️⃣ | Tłumaczenie API (FR → target_lang) — oryginalne cytaty EN nigdy nie są wysyłane do LLM, wysyłane są wyłącznie placeholdery (zachowane bez zmian) |
| 4️⃣ | Post-processing: przywrócenie placeholderów z nienaruszonymi oryginalnymi cytatami EN + wstawienie flagi języka docelowego |
| 5️⃣ | Walidacja po tłumaczeniu: czy wszystkie placeholdery zostały przywrócone? |
| ✅ | Wynik docelowy z zachowanymi cytatami EN |
| ❌ | Niepowodzenie, jeśli placeholder nie został przywrócony lub cytat został zniekształcony |
Tryb --news opiera się na tej zasadzie: pre-processing wyciąga wszystkie cytaty EN, zastępuje je placeholderami typu <NEWSQUOTE id="0"/>, tłumaczy resztę, a potem przywraca placeholdery bez zmian.
Mapowanie LANG_FLAGS dopasowuje flagę do target_lang (obsługiwanych jest 15 języków): 🇬🇧 dla angielskiego, 🇩🇪 dla niemieckiego, 🇪🇸 dla hiszpańskiego, 🇮🇹 dla włoskiego, 🇵🇹 dla portugalskiego, 🇳🇱 dla niderlandzkiego, 🇵🇱 dla polskiego, 🇸🇪 dla szwedzkiego, 🇷🇴 dla rumuńskiego, 🇸🇦 dla arabskiego, 🇮🇳 dla hindi, 🇯🇵 dla japońskiego, 🇰🇷 dla koreańskiego, 🇨🇳 dla chińskiego, 🇫🇷 dla francuskiego.
Walidacja po tłumaczeniu sprawdza, czy wszystkie placeholdery zostały przywrócone bez zmian. Błąd nie polega na „wycieku EN” — EN jest zamierzony — lecz na nieprzywróconym placeholderze albo zniekształconym cytacie.
Obecne zastosowania i perspektywy
Dziś używam --news wyłącznie w artykułach ia-actualites na blogu. Docelowo może to objąć każdy artykuł, który miesza francuską prozę i cytaty źródłowe EN — wywiady, relacje z doświadczeń cytujące angielskie artykuły naukowe, transkrypcje prezentacji konferencyjnych.
Bez czytania kodu: dlaczego trzeba podwoić zabezpieczenia
„Nie czytam kodu.”
Nie czytam niczego ponownie. Czasem rzucam okiem na diff — to rzadkie i zdarza się tylko wtedy, gdy Claude sam nie daje rady w jakimś punkcie. Oto przepływ, z którego korzystam na co dzień i który doprowadził do v1.9: Claude Code (wyłącznie Opus) pisze kod. Codex przejmuje, gdy Opus się blokuje albo okno użycia jest wyczerpane. GPT-5.5 w reasoning extra-high podważa plany przed wykonaniem. /pr-review-toolkit:review-pr czyta PR przed każdym mergem. Moja rola kończy się na zatwierdzaniu kierunków i definiowaniu zabezpieczeń.
Ten tryb rozwoju — pełny vibe coding — nie jest brakiem rygoru. To jawny kompromis: mniej ludzkiej relektury, więcej walidacji narzędziowej. 3 nowości v1.9, które właśnie przedstawiłem, powstały wszystkie w tym przepływie. I właśnie dlatego, że nie czytamy kodu, trzeba podwoić techniczne zabezpieczenia — nie je usuwać.
Oto dwa zabezpieczenia wdrożone po to, by uczynić ten tryb rozwoju wykonalnym w produkcji: zautomatyzowany stack jakościowy (zabezpieczenie 1) oraz wspomagana przez AI recenzja w wielomodelowym przepływie (zabezpieczenie 2).
Zabezpieczenie 1: automatyczny stack jakości (14 hooków + testy praktyczne)
Przegląd
| Siatka | Narzędzia | Typowy koszt | Blokujące w razie niepowodzenia |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hooks), detect-secrets, Lizard CCN | < 10 s | Tak |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Tak, z wyjątkiem pip-audit w początkowym trybie raportowania |
| CI zewnętrzne | SonarCloud, Codacy, CodeFactor | równolegle | Nieblojące lokalnie, badge PR |
Wyniki v1.9: 14 hooków, 229 testów unittest stdlib, ~98 % pokrycia nowego kodu v1.9, 11 odznak SonarCloud, 3 zewnętrzne platformy.
Pre-commit: szybkie zabezpieczenie
| # | Narzędzie | Wersja | Rola |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Lintowanie shella |
| 2 | ruff (lint) | 0.8.6 | Lintowanie Python |
| 3 | ruff (format) | 0.8.6 | Formatowanie Python |
| 4 | prettier | 3.1.0 | Formatowanie Markdown / JSON / YAML |
| 5 | trailing-whitespace | 5.0.0 | Usuwanie spacji na końcu linii |
| 6 | end-of-file-fixer | 5.0.0 | Wymagany końcowy newline |
| 7 | check-yaml | 5.0.0 | Walidacja składni YAML |
| 8 | check-toml | 5.0.0 | Walidacja składni TOML |
| 9 | check-added-large-files | 5.0.0 | Blokuje przypadkowo dodane duże binaria |
| 10 | check-merge-conflict | 5.0.0 | Wykrywanie znaczników konfliktu Git |
| 11 | check-executables-have-shebangs | 5.0.0 | Sprawdza, czy pliki wykonywalne mają shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Sprawdza, czy skrypty z shebangiem są wykonywalne |
| 13 | detect-secrets | 1.5.0 | Wykrywanie kluczy API i sekretów |
| 14 | check-complexity (Lizard) | local | Limit złożoności cyklomatycznej w nowym kodzie |
Łącznie zmierzone: około 2 do 3 sekund na całym repo (na ciepło, pre-commit run --all-files zmierzone na ~2,4 s). Na przeciętnym commicie, który dotyka tylko kilku plików, jest jeszcze szybciej. Zasada, którą stosuję: powyżej 10 s deweloperzy obchodzą zabezpieczenie (pair-IA też) — trzeba więc stale utrzymywać to szybkie sito.
Pre-push: ciężkie zabezpieczenie
- mypy w trybie liberalnym: bez pełnego strict (historyczny kod translate.py by nie przeszedł), ale z kontrolą postępu na nowym kodzie
- Opengrep SAST:
p/security-audit p/default p/python— około 30 sekund na skanowanie iniekcji, eval, niebezpiecznej deserializacji - pip-audit opakowany przez
scripts/check-pip-audit.sh: przechwytuje wyjście JSON, po stronie shella klasyfikuje błędy transportu (sieć, niedostępne PyPI), żeby nie mylić podatności z niedostępnością, i raportuje podatności. W początkowym trybie raportowania dla v1.9 (warn + exit 0) — do zaostrzenia do blokowania po PR z podbiciem przestarzałych zależności. - unittest discovery :
python -m unittest discovernatests/a następniescripts/tests/— 229 testów, około 8 sekund lokalnie
Zewnętrzne CI: SonarCloud + Codacy + CodeFactor
Workflow .github/workflows/sonarcloud.yml (klucz projektu jls42_ai-powered-markdown-translator) działa przy każdym PR. 11 odznak SonarCloud wyświetlanych w README: Quality Gate, Security/Reliability/Maintainability Rating, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC.
Dlaczego redundancja Codacy + SonarCloud + CodeFactor? Bo każde narzędzie widzi coś innego. Codacy zgłosiło duplikacje, których SonarCloud nie wskazał. SonarCloud zgłosił sygnały słabej jakości (słynne code smells), które Codacy przepuszczało. CodeFactor zgłosił problemy ze złożonością, które dwa pozostałe ignorowały. Żadne z nich nie wystarczyłoby samo. Marginalny koszt dodatkowej platformy jest zerowy (darmowy badge, 5 minut integracji), więc mnożymy perspektywy.
Testy: unittest stdlib (nie pytest)
229 testów, 0 regresji w ciągu 6 miesięcy PR, ~98 % pokrycia nowego kodu v1.9.
Typowy szczegół:
test_silent_failure.py: 97 testów ukierunkowanych na podwójną walidacjętest_orchestration.py: 79 testów na pipeline orkiestrującytest_translation_note_position.py: 38 testów na macierz pozycja × formattest_audit_verdict.py: 15 testów na wrapper pip-audit (wscripts/tests/)
Uczciwa uwaga: pokrycie ~98 % dotyczy nowego kodu v1.9 — nie całej historycznej bazy translate.py, która nadal zawiera kilka odziedziczonych funkcji słabo pokrytych przez nowy zestaw testów. Mówię o tym wprost, bo ogłoszenie „98 % pokrycia” dla całego projektu byłoby mylące.
Wybór dyskusyjny, ale świadomy: wykonawca testów unittest (stdlib), nie pytest. Prefiks test_ jest z przyzwyczajenia, ale to unittest uruchamia. Dlaczego? W projekcie opartym na vibe coding każda dodana zależność = każda zależność, której AI może użyć źle. Prostota jest celem. unittest jest w standardowej bibliotece Pythona, zero instalacji, zero pluginów.
Testy praktyczne: multi-repo + użycie produktu wewnętrznie (dogfooding) + weryfikacja renderu wizualnego
229 testów unittest nie wystarcza. Dodaję trzy warstwy testów praktycznych:
1. Multi-repo — testowanie skryptu na kilku publicznych repozytoriach z README w różnych formatach. To ujawnia przypadki brzegowe, których fixture’y nie obejmują — README z 8 poziomami nagłówków, inne z odziedziczonymi shortcode’ami, trzecie z egzotycznie osadzonym kodem. To właśnie w tej fazie odkryto incydent silent-failure z Nowości 1.
2. Dogfooding na blogu — jls42.org jest tłumaczony przez sam skrypt. Każdy opublikowany artykuł to test na żywo w produkcji. Jeśli jakiś przypadek brzegowy prześlizgnie się przez testy jednostkowe, wyjdzie tutaj, na stronie, którą czytasz. To test ostateczny — to, co jest online, jest tym, co projekt wytworzył.
3. Test renderu wizualnego — sprawdzam, czy wyrenderowane tłumaczenia wyświetlają się poprawnie, albo w przeglądarce (końcowa strona WWW), albo bezpośrednio w VSCode przez plugin podglądu Markdown. Chodzi o to, by nie poprzestawać na składniowo poprawnym Markdownie, lecz zobaczyć rzeczywisty render. Render wizualny wyłapuje błędy wyglądu (zepsute tabele, źle sformatowane bloki kodu, błędnie zinterpretowany frontmatter), których testy tekstowe nie widzą.
AI też uczestniczą w tych testach. /pr-review-toolkit uruchamia kod w środowisku testowym, a użycie w pair-IA zawsze obejmuje też przejścia walidacji wizualnej („sprawdź, czy niemieckie tłumaczenie strony X wyświetla się poprawnie”).
📄 Fragment .pre-commit-config.yaml (główne hooki pre-commit)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Fragment scripts/check-security-sast.sh
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Fragment .github/workflows/sonarcloud.yml
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Zabezpieczenie 2: recenzja wspomagana przez AI + przepływ wielomodelowy
Doprecyzowanie terminologii: gdy w tej sekcji mówię o Claude Opus, mam na myśli model, którego używam do tworzenia v1.9 — nie model, którego AI-Powered Markdown Translator używa do tłumaczenia. Sam projekt obsługuje 4 providerów (OpenAI, Mistral AI, Claude, Gemini) i dowolny model (Sonnet, Haiku, Mistral Large, Gemini 3 Pro itd.). Po stronie rozwoju blokuję się na Opus. Po stronie użycia w czasie wykonywania projekt pozostaje agnostyczny.
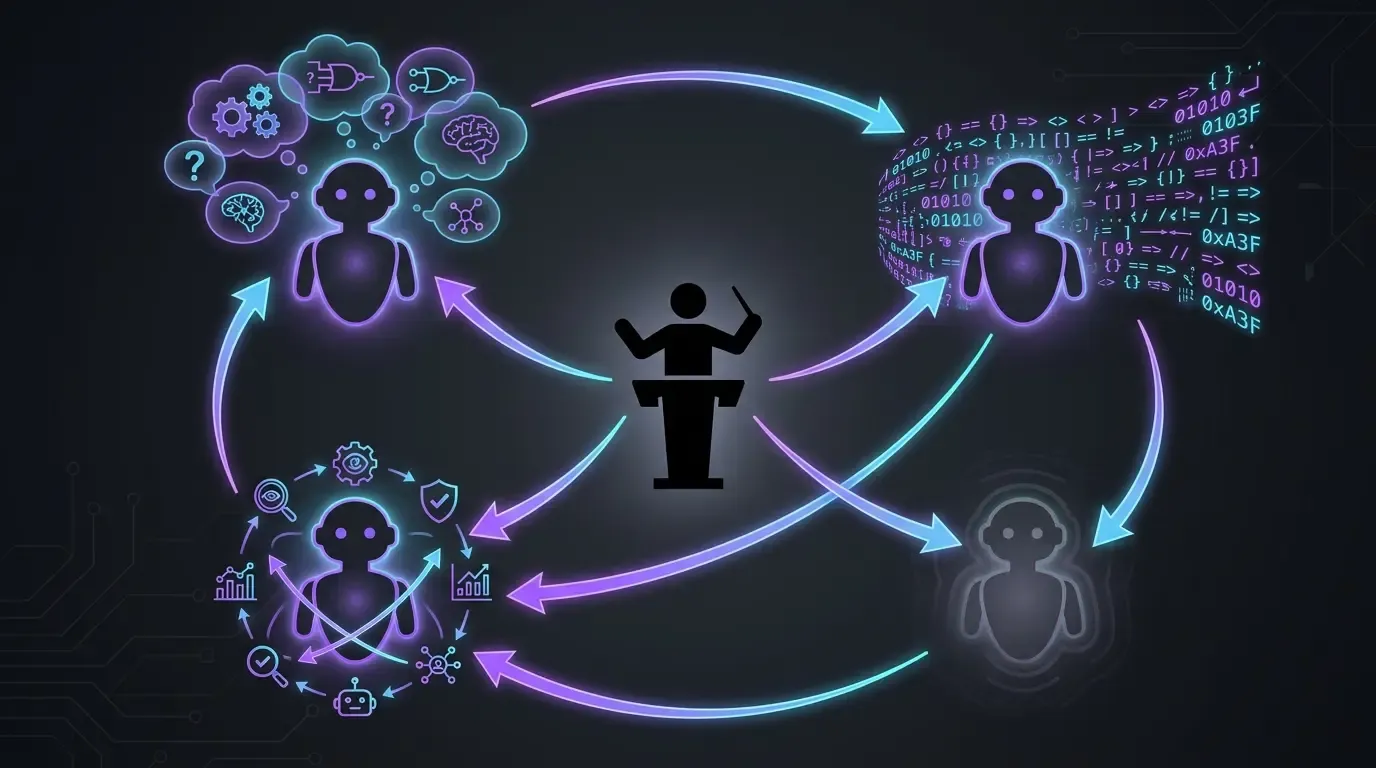
Rzeczywisty workflow: 4 modele, 4 role (do rozwoju)
- Claude Code w Opus, wyłącznie (Anthropic) : główne wykonanie. Czyta kontekst, pisze kod, wdraża poprawki. Bez Sonnet, bez Haiku, bez fast mode. W tym projekcie za każdym razem chcę model z najwyższej półki — idea jest prosta: upewniamy się, że mamy to, co najlepsze, żeby celować w możliwie najlepszy rezultat.
- OpenAI Codex jako rozwiązanie zapasowe (fallback) : używany w dwóch konkretnych przypadkach:
- Gdy Opus wysypuje się na jakimś temacie (rzadko, ale się zdarza — na przykład przy poprawkach wymaganych przez zewnętrzne agenty typu Codacy albo SonarCloud, Claude czasem nie dochodzi do rozwiązania i przerzucam temat na Codex, żeby go odblokować)
- Gdy okno użycia Anthropic jest zapchane. Codex pozwala nie tracić impetu, czekając na reset limitu.
- GPT-5.5 reasoning extra-high (
xhigh) : kwestionowanie planów przed wykonaniem. Zanim pozwolę Claude Code ruszyć z tematem, przepuszczam plan przez GPT-5.5 w reasoning extra-high. Zadaje właściwe pytania, wskazuje martwe pola. To pozwala uniknąć pójścia w złą stronę, którą trzeba by potem odkręcać. /pr-review-toolkit:review-pr(skill plugin Claude Code) : przegląd przed merge’em z wyspecjalizowanymi agentami (bezpieczeństwo, jakość, testy, komentarze, projektowanie typów). Skill działa na PR przed moim merge’em — to ostatnia AI-owa siatka bezpieczeństwa, zanim kod trafi domain.
Żaden z tych modeli nie wystarcza sam. Każdy pełni inną rolę — wysokiej klasy wykonawca, zastępca przy ograniczonej przepustowości, challenger planów, wieloaspektowy reviewer.
/pr-review-toolkit : czego bym nie zauważył
Wszystko. Nie patrzę na kod. Skill wyciąga wszystko — ukryte bugi, problemy bezpieczeństwa, niespójności testów, testy, które przechodzą, ale niczego nie testują.
Na PR #2 (75 commitów, 9 837 dodanych linii, 1 982 usunięte linie, 58 plików), człowiek sam odpuściłby 80% PR ze zmęczenia. Skill niczego nie odpuszcza. Czyta każdy diff, każdy test, każdy komentarz. I przede wszystkim kwestionuje — odrzuca wzorce, które uzna za złe, i proponuje alternatywy.
Człowiek jako dyrygent, nie muzyk
Moja rola obejmuje cały łańcuch — poza pisaniem kodu. Zakładam czapki producenta (myślenie o funkcjach, priorytetyzacja, arbitraż), QA (testowanie na rzeczywistych przypadkach, wizualna walidacja efektu), tech leada (kwestionowanie planów z GPT-5.5 reasoning extra-high), klienta końcowego (ocena rezultatu na podstawie własnego codziennego doświadczenia z blogiem). Jedyna czapka, której nie noszę, to kodowanie. Reszta to ja.
Stałem się producentem, nie muzykiem.
Na usługach bloga: tłumaczy się sam (blisko 1 800 tłumaczeń)
AI-Powered Markdown Translator generuje własny README w 14 językach i to on tworzy wszystkie obcojęzyczne wersje treści jls42.org. Konkretnie: blisko 1 800 przetłumaczonych wersji zasila blog (25 artykułów + 4 projekty + 98 aktualności AI × 14 języków, bez źródeł FR — czyli 1 778 wersji w chwili, gdy to piszę). Każda strona, którą tu przeglądasz w języku innym niż francuski, przeszła przez ten projekt.
To dogfooding produktu doprowadzony do skrajności — i stresuje to tłumaczenie na artykule o tłumaczeniu. Jeśli to, co czytasz w ar, hi lub ko, jest spójne, to siatka bezpieczeństwa Nowości 1 (walidacja po tłumaczeniu) działa; jeśli notka tłumaczeniowa wyświetla się poprawnie u góry, to Nowość 2 (notka wielopozycyjna) działa; jeśli cytaty EN są zachowane w wersjach językowych, to Nowość 3 (tryb --news) też działa.
Wniosek: rygorystyczny pair-IA, nie niedbały pair-IA
Programowanie na wyczucie ma złą prasę z dobrych powodów. Właśnie z nimi pracuję. Z tej v1.9 wynikają cztery konkretne lekcje:
-
Ciche porażki są wrogiem numer jeden. AI generuje kod, który wygląda OK i przechodzi przez testy jednostkowe. Systematyczna walidacja po stronie klienta. I używanie innej AI do przeglądu rzeczywistej produkcji, nie tylko kodu.
-
Hooki pre-commit < 10 s, inaczej są omijane; pre-push mogą trwać 30 s+. AI chętnie dodaje narzędzia, nie biorąc pod uwagę ich kosztu. Trzeba to ręcznie ustawić, albo w planie, albo po fakcie — ważne jest, żeby finalnie hooki były dobrze skonfigurowane i faktycznie używane na co dzień.
-
Pokrycie bez mocnej asercji = teatr. AI może wygenerować 200 testów, które przechodzą i niczego nie testują. unittest + precyzyjne asercje > pytest z masą mocków. Sprawdzać wartość zwracaną, a nie tylko to, że kod się nie wywalił.
-
Przegląd (PR review) AI nie jest opcją. Kiedy ludzki autor nie zrobił przeglądu, AI reviewer nie jest gadżetem — to delegowane oko.
Dobrze zrobione vibe coding to też zaakceptowanie, że nie czytamy kodu i delegujemy krytyczną lekturę innym AI, które naprawdę to robią.
Co ten projekt ujawnia
Ta v1.9 pokazuje kilka aspektów mojego sposobu pracy:
- Rola ludzka obejmuje cały łańcuch poza kodem : produkt (myślenie o funkcjach, priorytetyzacja), QA (testowanie na rzeczywistych przypadkach, wizualna walidacja), tech lead (kwestionowanie planów z LLM w reasoning extra-high), klient końcowy (ocena na podstawie realnego użycia). Jedyna czapka, której nie noszę, to kodowanie.
- Dublować siatki bezpieczeństwa, nie usuwać ich : mniej ludzkiego przeglądu = więcej walidacji narzędziowej. Kompromis świadomy, nie brak rygoru. Jeśli usuwam przegląd, muszę podwoić siatki bezpieczeństwa, a nie ślepo ufać AI.
- AI do odkrywania bugów AI : cichy błąd został znaleziony przez Claude podczas praktycznych testów multi-repo. Pełna delegacja: można też delegować krytyczny przegląd.
- pair-IA jako mnożnik czasu prywatnego : ciągnę ten projekt wieczorami i w weekendy. Bez pair-IA z pewnością nie zaszedłbym tak daleko ani tak szybko. Dzięki niemu mogę utrzymywać projekt open-source na poziomie przemysłowym obok innych obowiązków. To właśnie umożliwia vibe coding — nie po to, by zastąpić developera, ale by pozwolić mu robić to, czego sam nie byłby w stanie.
- Iterować zamiast przepisywać wszystko od nowa : 9 wersji, inkrementalny refactoring (1 funkcja → 7 helperów), zachowana kompatybilność wsteczna. pair-IA pomaga iterować szybko bez przepisywania wszystkiego.
Zasoby
- AI-Powered Markdown Translator na GitHubie
- Wydanie v1.9
- PR #2 — 75 commitów, migracja + jakość
- Pełny CHANGELOG
- Strona projektu na tym blogu
- Artykuł 2024 — v1.5 (w stylu release notes) — do porównania tonu
- Dogłębne omówienie AWS Diagram — inny artykuł z tej serii
Jeśli chcecie przetestować AI-Powered Markdown Translator na własnych Markdownach — open-source README, artykułach blogowych, dokumentacji technicznej —, kod jest na GitHubie. Instalacja w kilka minut, 4 wspierane providery, tryb --eco do obniżenia kosztu, tryb --news do zachowania cytatów źródłowych i od teraz stos jakości v1.9, który możecie ponownie wykorzystać jako szablon do własnych projektów w pair-IA.
Skoro rozwijacie swoje projekty osobiste metodą vibe coding, nie idźcie na łatwiznę po stronie jakości. Niezawodność jest ceną szybkości — zaakceptujcie oba naraz.