ai-powered-markdown-translatorArtikel aus dem Französischen ins Deutsche übersetzt mit gpt-5.4-mini.
AI-Powered Markdown Translator ist ein Open-Source-Projekt, das ich seit 2024 pflege: ein Python-Skript, das jede beliebige Markdown-Datei über 4 KI-Provider (OpenAI, Mistral AI, Claude, Gemini) in 14 Sprachen übersetzt. Es speist diesen Blog bei jeder Veröffentlichung — jede Seite, die ihr hier in einer anderen Sprache als Französisch lest, ist darüber gelaufen — und knapp 1 800 übersetzte Versionen laufen dank ihm bereits produktiv.
Am 8. Mai 2026 habe ich die v1.9 veröffentlicht, die 75 Commits zusammenfasst und das größte Update seit v1.5 aus dem Jahr 2024 markiert. Drei Produktneuheiten:
- Post-Translation-Validierung (Schutz vor stillen Fehlschlägen)
- Mehrpositionale Übersetzungsnotiz (oben, unten oder beides)
- Modus
--newszum Bewahren der EN-Quellenzitate
Diese v1.9 hat aber eine Besonderheit, die ich hier erzählen möchte: Der gesamte Code wurde im KI-Pairing geschrieben. Keine einzige Zeile von Hand getippt. Also geht es neben den 3 Neuheiten auch um das „Wie“: Welche Leitplanken setzt man, um sauberen und sicheren Code anzustreben, wenn man nicht selbst nachprüft, was die KI erzeugt?
Der Kontext: ein Projekt, das täglich genutzt wird, aber auf Code-Seite wenig gepflegt wurde
Von September 2024 bis Mai 2026: kontinuierliche Nutzung, Pflege in Schüben
Ich hatte einen Artikel veröffentlicht, der den Quellcode von v1.5 im Jahr 2024 detailliert beschrieb. Damals veröffentlichte ich das Skript direkt im Artikel. Heute hat sich der Blickwinkel geändert: Wichtiger als der Code, den ich schreibe, ist der Arbeitsfluss, der ihn hervorbringt.
Zwischen der im September 2024 veröffentlichten v1.5 und Januar 2026 lief das Projekt weiter — es übersetzt jeden neuen Inhalt dieses Blogs —, aber der öffentliche Code hat sich kaum bewegt. 2025 wurde nur ein einziger Commit gepusht. In all dieser Zeit entwickelte ich den Code lokal für meine persönlichen Bedürfnisse weiter — vor allem die Modelle, die ich nach und nach durch neuere Releases ersetzte —, aber diese Änderungen blieben auf meiner Maschine. Die öffentliche Version auf GitLab zeigte weiterhin auf die Standardwerte von v1.5.
Anfang 2026 habe ich einen ersten Modernisierungsschub gemacht: drei Releases in zwei Monaten (v1.6 und v1.7 an zwei Tagen Anfang Januar, v1.8 im März), die das Projekt funktionsseitig wieder auf Stand brachten — 2026-Modelle, Gemini-Support, Modus --eco, Einzelfile, Modus --news für Quellzitate. Aber immer noch ohne CI, ohne automatisierte Tests, ohne Qualitäts-Gates — und genau das war für mich ein echtes Problem, um mit einem KI-Agenten weiterzugehen, der für mich codet.
Das Tempo eines Projekts in der Freizeit
Warum diese Verzögerung? Weil ich dieses Projekt in meiner Freizeit betreibe. Ich habe eine Familie, ein Leben außerhalb des Bildschirms, also geht die Entwicklung nur in Schüben voran, wenn ich abends oder am Wochenende Zeit finde. Ich bin begeistert, verbringe trotzdem ziemlich viel Zeit mit diesen Themen — ich teste viel, ich steuere die Agenten, ich validiere die Ergebnisse —, aber das Tempo ist nicht das eines professionellen Projekts.
KI-Pairing ändert genau das. Es erlaubt mir, zwischen zwei Grenzen voranzukommen — der Begeisterung und dem Maß des Lebens außerhalb des Bildschirms. Ohne KI-Pairing käme ich klar nicht so weit und so schnell. Mit ihm kann ich ein Open-Source-Projekt auf Industrieniveau pflegen, ohne mein Leben dafür aufzuwenden.
Das ursprüngliche Ziel: Qualität + Migration GitLab → GitHub
Mitte April 2026 wollte ich mich endlich ernsthaft darum kümmern. Zwei einfache Ziele:
- Eine Qualitätsschicht hinzufügen (statische Analyse, Tests, CI)
- Das Repo von GitLab nach GitHub migrieren
Nicht mehr. Aber mit einem Code-Agenten im KI-Pairing schreibt man nie genau das, was geplant war. Die PR endete bei 75 Commits, 9 837 Additionen, 1 982 Löschungen, 58 Dateien.
| Version | Datum | Wichtigster Beitrag |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, dann Mistral, dann Claude |
| 1.5 | Sept. 2024 | Refactor von Clients, 2024-Modelle (gpt-4o, claude-3.5-sonnet) |
| 1.6 | Jan. 2026 | 2026-Modelle (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, Modus --eco, Einzelfile (--file) |
| 1.7 | Jan. 2026 | --keep_filename, .env, Inline-Code beibehalten |
| 1.8 | März 2026 | GPT-5.4-Modelle standardmäßig, Modus --news mit Platzhalter-Zitaten |
| 1.9 | Mai 2026 | Post-Translation-Validierung, mehrpositionale Notiz, Qualitäts-Stack 14 Hooks + 229 Tests + KI-Review |
Der Schneeballeffekt
Jedes hinzugefügte Qualitätstool legte Probleme offen. Codacy meldete Duplikate. SonarCloud hob code smells hervor (Signale für Code, der schlecht altern wird: zu lange Funktionen, ungenutzte Parameter, verquere Strukturen). /pr-review-toolkit zeigte versteckte Bugs auf. Bei jedem Fund korrigierte der Agent — und verbesserte manchmal auch angrenzende Dinge.
Der Umfang wuchs organisch explosionsartig. Genau das wollte ich — das Projekt modernisieren —, aber das Ausmaß des Aufwands wurde von den Tools bestimmt, nicht von mir. Für ein Vibe-Coding-Projekt ist das ein Schlüsselpunk: Qualitätstools lenken die Arbeit genauso sehr, wie sie sie prüfen.
Neuheit 1: die Post-Translation-Validierung (Schutz vor stillen Fehlschlägen)
Der Vorfall: Die KI hat den Bug während der Tests gefunden
Beim Testen der PR auf README-Dateien aus verschiedenen öffentlichen Repos — ein Fall, der von keinem Fixture abgedeckt war — meldete die KI, was ich übersehen hatte: In manchen Sprachen (insbesondere Hindi, ISO-Code hi) blieben Passagen mitten in der Übersetzung in der Quellsprache. Die API hatte 200 zurückgegeben, das Skript hatte die Datei geschrieben, aber der Inhalt war nur halb übersetzt. Und das ging durch die bestehende Unit-Test-Batterie hindurch — die diesen realen Multi-Language-Fall nicht abdeckte.
Genau das ist die Art von Bug, die Vibe-Coding erzeugen kann und die niemand sieht. Der Code wirkt logisch, die Test-Fixtures decken den Fall nicht ab, der Mensch liest das Ergebnis nicht gegen. Aber hier, beim Testen des Skripts auf realen Fällen (Multi-Repo), hat die KI selbst das getan, was die Fixtures nicht getan haben.
Was ich daraus mitnehme: Praktische Multi-Repo-Tests finden, was Unit-Tests übersehen. Und KI kann auch dabei helfen, die Bugs früherer KI-Agenten zu entdecken — vorausgesetzt, man konfrontiert sie mit vielfältigen realen Fällen.
An diesem Punkt habe ich verstanden, dass ich eine echte Post-Translation-Validierung hinzufügen musste. Das ist die erste Neuheit, die ich jetzt erläutere: die doppelte Validierungsschicht.
Die doppelte Validierungsschicht
| Schritt | Aktion | Falls KO |
|---|---|---|
| 1️⃣ | API-Call des Providers | Netzwerk-Exception → ❌ Fehlschlag |
| 2️⃣ | Provider-Whitelist für finish_reason (oder stop_reason bei Claude) | Außerhalb der Whitelist → ❌ Fehlschlag |
| 3️⃣ | Leak-Schutz: kein Quellfenster ≥ 120 Zeichen wörtlich in der Ausgabe | Quellfenster gefunden → ❌ Fehlschlag |
| 4️⃣ | langdetect.detect_langs (Quell- vs. Ziel-Wahrscheinlichkeiten) | Quelle > 0,80 UND Ziel < 0,20 → ❌ Fehlschlag |
| 5️⃣ | Empty-Content + Ausgabe/Quelle-Verhältnis (wenn Quelle ≥ 500 Zeichen) | Leer oder Ausgabe < max(50, source/20) → ❌ Fehlschlag |
| ✅ | ERFOLG | Exit-Code 0 |
Schicht 1 (deterministisch) — Erste Sicherung: den vom API zurückgegebenen Status prüfen. Jeder Provider stellt ein Feld finish_reason (oder stop_reason bei Claude) bereit, das angibt, warum das LLM aufgehört hat zu generieren. Das Skript hält eine provider-spezifische Whitelist akzeptabler Statuswerte vor — die Nomenklatur variiert (stop bei OpenAI/Mistral, STOP oder FINISH_REASON_STOP bei Gemini, end_turn oder stop_sequence bei Claude). Der Code toleriert aus Sicherheitsgründen auch None, wenn das SDK dieses Feld nicht zurückgibt. Jeder andere Status — zum Beispiel length, max_tokens oder MAX_TOKENS je nach Provider, die eine durch das Token-Limit gestoppte Antwort signalisieren — löst sofort ein RuntimeError aus, ohne Versuch einer Wiederherstellung.
Zweites deterministisches Netz, subtiler: prüfen, dass kein Abschnitt des Quelltexts wörtlich in der übersetzten Ausgabe erscheint. Konkret extrahieren wir Fenster von 120 Zeichen oder mehr aus dem Quelltext; wenn eines davon unverändert in der Ausgabe wiedergefunden wird, wurde es nicht übersetzt — failure. Genau dieser Check hat den Hindi-Fall abgefangen: Das LLM hatte stop zurückgegeben (also ein „natürliches“ Ende auf API-Seite), aber französische Absätze waren in der Ausgabe intakt geblieben — für das Netz finish_reason unsichtbar, vom Verbatim-Leak-Filter erkannt.
Schicht 2 (probabilistisch) — langdetect.detect_langs analysiert die Sprache der Ausgabe und gibt eine Wahrscheinlichkeitsverteilung über mehrere Kandidatensprachen zurück. Wir extrahieren die Wahrscheinlichkeit der Quellsprache und die der Zielsprache und verwerfen nur dann, wenn die Quellwahrscheinlichkeit über 0,80 liegt und die Zielwahrscheinlichkeit unter 0,20 fällt — eine bewusst konservative Schwelle, um keine False Positives bei technischem Code-Switching zu erzeugen (z. B. legitime englische Wörter in einer deutschen Übersetzung). Diese Schicht wird für Sprachen mit nicht-lateinischen Schriftsystemen umgangen (Hindi hi, Arabisch ar, Chinesisch zh, Japanisch ja, Koreanisch ko), wo ein ausreichendes Schriftsignal die Ausgabe bereits validiert. Und sie läuft nur, wenn die bereinigte Ausgabe mindestens 100 Zeichen umfasst, um False Positives bei zu kurzem Text zu vermeiden.
Die quantitativen Leitplanken
Über den beiden Schichten liegen zwei prosaischere, aber notwendige Kontrollen:
- Empty-Content-Guard: Wenn der Provider eine leere Ausgabe zurückgibt, obwohl
finish_reasonaufstopsteht, verwerfen wir sofort (sonst würden wir eine leere Datei als success schreiben) - Sanity Ratio: Nur wenn die Quelle mindestens 500 Zeichen lang ist, prüfen wir, ob die Ausgabe nicht verdächtig kurz ist (typischerweise <
max(50, source/20)). Das ist ein Detektor für unsichtbare Trunkierung, keine allgemeine Längenregel
Bei Claude speziell wurde max_tokens in v1.9 von 4 096 auf 32 768 erhöht (die Änderung wurde auf Code-Seite von Claude vorgenommen, nachdem ich das Symptom festgestellt und um Untersuchung gebeten hatte). Der dokumentierte Grund im CHANGELOG: latente Trunkierung bei 16-k-Zeichen-Segmenten vermeiden, mit zusätzlicher Reserve für Sprachen mit nicht-lateinischer Schrift (FR → JA, ZH, KO, AR, HI), die in der Ausgabe mehr Tokens verbrauchen als ein äquivalentes lateinisches Schriftsystem.
Rückgaben mit explizitem Status
Die Datei-Pipeline (translate_markdown_file()) gibt nun einen expliziten Status zurück — success, failure oder skipped. Das CLI aggregiert diese Status und beendet sich mit einem Nicht-Null-Exit-Code, sobald mindestens eine Datei fehlgeschlagen ist — dadurch wird der Fehler für ein aufrufendes Skript oder für die neue CI, die in v1.9 hinzugefügt wurde, nutzbar. Vor dieser v1.9 wurden mehrere Fehler nur ausgegeben oder liefen als erfolgreiche Übersetzung durch: Der Prozess konnte mit 0 enden, obwohl die Datei fehlte, unvollständig oder fehlerhaft validiert war. Der Status skipped wird selbst zu einem lesbaren Signal („bewusst ignoriert“), getrennt von success („Übersetzung korrekt geschrieben“).
📄 Python-Auszug: doppelte Post-Translation-Validierung (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNeuheit 2: die mehrpositionale Übersetzungsnotiz
Der Bedarf: eine dezente, aber informative Notiz
Wenn AI-Powered Markdown Translator eine Übersetzung schreibt, fügt es eine Übersetzungsnotiz hinzu, die das verwendete Modell und das Datum angibt. Vor v1.9 war diese Notiz systematisch unten an die Datei angehängt, in einem geerbten (legacy) Format mit sichtbaren Trennern.
Das unten angehängte Format hatte für meine eigenen Nutzungen zwei Probleme. Erstens wurde der Leser erst ganz am Ende darüber informiert, dass der Inhalt von einer KI übersetzt wurde — besser ist es, gleich am Anfang zu warnen, damit die Erwartung an den Inhalt stimmt. Zweitens hob die Fußnoten-Notiz das Übersetzungsprojekt, das all das überhaupt erst ermöglicht, nicht hervor: Man liest den Artikel, und die Herkunft des mehrsprachigen Flows bleibt unauffällig. Ich wollte also die Notiz nach oben verschieben können und dabei die Nachverfolgbarkeit behalten — ohne bestehende Nutzungen zu brechen. v1.9 fügt zwei Flags hinzu, die nichts kaputtmachen:
--note_position {top,bottom,both}: oben, unten oder beides--note_format {legacy,marker}: Legacy-Format oder Markierer-Format (marker format)
Rückwärtskompatible Defaults: legacy + bottom. Keine bestehende Übersetzungszeichenkette ändert standardmäßig ihr Verhalten — die neuen Flags werden bei Bedarf explizit aktiviert.
Das Markierer-Format: eine saubere eingebettete GitHub-Karte (embed card)
Das Markierer-Format nutzt ein feines Detail von GitHub Markdown: Nicht verwendete link reference definitions sind im Rendering unsichtbar. Man kann also Metadaten (Modell, Datum, Quelle) in einem Kommentar-Markierer kodieren, der oben in der Datei platziert wird — unsichtbar im Browser, aber bei rohem Kopieren unverändert erhalten.
GitHub erzeugt außerdem eine eingebettete Karte (embed card), wenn man einen Link auf die übersetzte Datei teilt, und diese Karte zeigt den Titel des Dokuments sauber an, ohne textliche Verschmutzung.
Beispiel für rohes Markdown mit Markierer-Format in Position top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...Auf den ersten Blick sieht der Leser nur den Titel, gefolgt vom Inhalt. Der Markierer verschmutzt weder das HTML-Rendering noch die Embed-Karte.
Das bewusste Einfügen des Frontmatters (frontmatter-aware)
Technisches, aber entscheidendes Detail: Eine Notiz in top einzufügen bedeutet nicht „an Zeile 1 der Datei einfügen“. Wenn die Datei ein YAML-Frontmatter hat (was bei diesem Blog der Fall ist), muss man nach dem Frontmatter einfügen — sonst zerstört die Notiz das YAML.
Ich habe Claude die Anforderung gegeben („füge die Notiz nach dem Frontmatter ein, nicht davor — sonst zerlegst du das YAML“), und er hat einen _split_frontmatter-Helper geliefert, der die offenen/geschlossenen ----Fences erkennt. Wenn die Datei eine nicht geschlossene YAML-Fence hat (ein fehlerhafter Fall), wirft der Helper eine RuntimeError, statt stillschweigend eine kaputte Datei zu erzeugen. Der Übergang von einer monolithischen Funktion zu 7 reinen, separaten und testbaren Helpern ist typisch dafür, was gut angeleitetes Pair-IA schnell leisten kann. Meine Rolle hier: Anforderungsgeber, Tester, Endkunde, der das Ergebnis validiert. Nicht programmieren. In diesem Projekt trage ich mehrere Hüte — außer dem, Code zu schreiben, das übernimmt Claude.
| Position | Format | Typischer Anwendungsfall |
|---|---|---|
top | marker | Blogartikel (diskrete Notiz, saubere Embed-Karte) |
top | legacy | Interne Doku, wo sichtbare Nachvollziehbarkeit zählt |
bottom | marker | Open-Source-README (stimmig mit Footer) |
bottom | legacy | Vorgaben — abwärtskompatibel |
both | marker | Lange Artikel, bei denen oben + unten beruhigen |
both | legacy | Legacy-Fälle mit Anforderung an doppelte Nachvollziehbarkeit |
📄 Python-Auszug: Helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")Neuheit 3: der Modus --news zum Bewahren von EN-Quellenzitaten
Das Problem: übersetzen, ohne die Zitate zu zerstören
Wenn ich ia-actualites-Artikel für diesen Blog schreibe (tägliche/wöchentliche KI-News aus mehreren Quellen), zitiere ich regelmäßig Tweets, Blogbeiträge und Versionsankündigungen auf Englisch — oft mehrere pro Artikel. Wenn die Übersetzung die Zitate anfasst, werden sie falsch.
Ein übersetztes Zitat ist ein verfälschtes Zitat. In allen Sprachversionen (EN, DE, JA usw.) wollen wir das englische Original der Zitate beibehalten — das ist eine Anforderung an die Treue zu den Quellen — begleitet vom Flag der Zielsprache und einer kursiven Übersetzung für den Lesekomfort.
Die Lösung: Platzhalter <NEWSQUOTE id="N"/>
| Schritt | Aktion |
|---|---|
| 1️⃣ | FR-Quell-Markdown mit EN-Zitaten als Eingabe |
| 2️⃣ | Vorverarbeitung: Extraktion der EN-Zitate, Ersetzung durch Platzhalter <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, usw. |
| 3️⃣ | API-Übersetzung (FR → target_lang) — die ursprünglichen EN-Zitate werden niemals an das LLM gesendet, nur die Platzhalter (unverändert beibehalten) |
| 4️⃣ | Nachverarbeitung: Wiederherstellung der Platzhalter mit den ursprünglichen EN-Zitaten intakt + Einfügen des Flags der Zielsprache |
| 5️⃣ | Validierung nach der Übersetzung: Sind alle Platzhalter wiederhergestellt worden? |
| ✅ | Zielausgabe mit beibehaltenen EN-Zitaten |
| ❌ | Fehler, wenn ein Platzhalter nicht wiederhergestellt oder ein Zitat verfälscht wurde |
Der Modus --news beruht auf diesem Prinzip: Eine Vorverarbeitung extrahiert alle EN-Zitate, ersetzt sie durch Platzhalter vom Typ <NEWSQUOTE id="0"/>, übersetzt den Rest und stellt die Platzhalter unverändert wieder her.
Das Mapping LANG_FLAGS passt das Flag an die target_lang an (15 abgedeckte Sprachen): 🇬🇧 für Englisch, 🇩🇪 für Deutsch, 🇪🇸 für Spanisch, 🇮🇹 für Italienisch, 🇵🇹 für Portugiesisch, 🇳🇱 für Niederländisch, 🇵🇱 für Polnisch, 🇸🇪 für Schwedisch, 🇷🇴 für Rumänisch, 🇸🇦 für Arabisch, 🇮🇳 für Hindi, 🇯🇵 für Japanisch, 🇰🇷 für Koreanisch, 🇨🇳 für Chinesisch, 🇫🇷 für Französisch.
Die Validierung nach der Übersetzung prüft, dass alle Platzhalter unverändert wiederhergestellt wurden. Der Fehler ist kein „EN-Leak“ — das EN ist gewollt — sondern ein nicht wiederhergestellter Platzhalter oder ein verfälschtes Zitat.
Aktuelle Anwendungsfälle und Perspektiven
Heute verwende ich --news ausschließlich auf ia-actualites-Artikeln des Blogs. Langfristig könnte das auf jeden Artikel ausgeweitet werden, der französische Prosa und EN-Quellenzitate mischt — Interviews, Erfahrungsberichte, die englischsprachige Forschungsartikel zitieren, Transkripte von Konferenzvorträgen.
Ohne den Code zu lesen: warum man die Schutzgeländer verdoppeln muss
„Ich lese den Code nicht.“
Ich lese nichts noch einmal. Ich schaue mir manchmal kurz einen Diff an — das ist selten, und nur dann, wenn Claude bei einem Punkt allein nicht weiterkommt. Hier ist der Ablauf, den ich täglich nutze und der v1.9 hervorgebracht hat: Claude Code (ausschließlich Opus) tippt den Code. Codex übernimmt, wenn Opus blockiert oder das Nutzungskontingent erschöpft ist. GPT-5.5 im reasoning extra-high challengt die Pläne vor der Ausführung. /pr-review-toolkit:review-pr liest die PR vor jedem Merge gegen. Meine Rolle endet damit, die Richtungen zu validieren und die Schutzgeländer festzulegen.
Dieser Entwicklungsmodus — vollständige gefühlsbasierte Entwicklung (vibe coding) — ist kein Mangel an Strenge. Es ist ein expliziter Kompromiss: weniger menschliche Nachprüfung, mehr instrumentierte Validierung. Die 3 v1.9-Neuheiten, die ich gerade vorgestellt habe, wurden alle in diesem Ablauf produziert. Und gerade weil wir den Code nicht lesen, muss man die technischen Schutzgeländer verdoppeln — nicht sie entfernen.
Hier sind die beiden Schutzgeländer, die eingerichtet wurden, um diesen Entwicklungsmodus produktionsfähig zu machen: ein automatisierter Qualitäts-Stack (Schutzgeländer 1) und eine KI-gestützte Review in einem Multi-Modell-Flow (Schutzgeländer 2).
Schutzgeländer 1: der automatisierte Qualitäts-Stack (14 Hooks + Praxistests)
Überblick
| Netz | Werkzeuge | Typische Kosten | Blockierend bei Fehler |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 Sub-Hooks), detect-secrets, Lizard CCN | < 10 s | Ja |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Ja, außer pip-audit im initialen Reporting |
| externe CI | SonarCloud, Codacy, CodeFactor | parallel | Lokal nicht blockierend, PR-Badges |
Kennzahlen v1.9: 14 Hooks, 229 unittest-Stdlib-Tests, ~98 % Abdeckung für den neuen v1.9-Code, 11 SonarCloud-Badges, 3 externe Plattformen.
Pre-commit: das schnelle Netz
| # | Werkzeug | Version | Rolle |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Shell-Lint |
| 2 | ruff (lint) | 0.8.6 | Python-Lint |
| 3 | ruff (format) | 0.8.6 | Python-Formatierung |
| 4 | prettier | 3.1.0 | Markdown-/JSON-/YAML-Formatierung |
| 5 | trailing-whitespace | 5.0.0 | Entfernen von Leerzeichen am Zeilenende |
| 6 | end-of-file-fixer | 5.0.0 | Verpflichtende finale Newline |
| 7 | check-yaml | 5.0.0 | YAML-Syntaxvalidierung |
| 8 | check-toml | 5.0.0 | TOML-Syntaxvalidierung |
| 9 | check-added-large-files | 5.0.0 | Blockiert versehentlich hinzugefügte große Binärdateien |
| 10 | check-merge-conflict | 5.0.0 | Erkennung von Git-Konfliktmarkern |
| 11 | check-executables-have-shebangs | 5.0.0 | Prüft, dass ausführbare Dateien einen Shebang haben |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Prüft, dass Skripte mit Shebang ausführbar sind |
| 13 | detect-secrets | 1.5.0 | Erkennung von API-Schlüsseln und Secrets |
| 14 | check-complexity (Lizard) | local | Schwelle für zyklomatische Komplexität im neuen Code |
Gemessenes Total: etwa 2 bis 3 Sekunden für das gesamte Repo (warm, pre-commit run --all-files auf ~2,4 s gestoppt). Bei einem durchschnittlichen Commit, der nur ein paar Dateien betrifft, ist es noch schneller. Die Faustregel, die ich anwende: Über 10 s weichen Entwickler aus (auch das Pair-IA) — deshalb muss dieses schnelle Netz dauerhaft aktiv bleiben.
Pre-push: das schwere Netz
- mypy im lockeren Modus: kein vollständiges Strictness, der historische translate.py-Code würde sonst nicht durchkommen, aber eine Fortschrittsprüfung für den neuen Code
- Opengrep SAST:
p/security-audit p/default p/python— etwa 30 Sekunden, um Injektionen, eval und unsichere Deserialisierung zu scannen - pip-audit umhüllt von
scripts/check-pip-audit.sh: fängt die JSON-Ausgabe ab, klassifiziert auf Shell-Seite Transportfehler (Netzwerk, PyPI down), damit man Schwachstelle und Nichtverfügbarkeit nicht verwechselt, und meldet die Schwachstellen. Im initialen Reporting-Modus für v1.9 (warn + exit 0) — später zu verschärfen und blockierend zu machen, nach einer PR zum Bump veralteter Abhängigkeiten. - unittest discovery:
python -m unittest discoverauftests/dannscripts/tests/— 229 Tests, lokal etwa 8 Sekunden
Externe CI: SonarCloud + Codacy + CodeFactor
Der Workflow .github/workflows/sonarcloud.yml (Project Key jls42_ai-powered-markdown-translator) läuft bei jeder PR. 11 SonarCloud-Badges werden im README angezeigt: Quality Gate, Security/Reliability/Maintainability Rating, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC.
Warum die Redundanz Codacy + SonarCloud + CodeFactor? Weil jede Plattform andere Dinge sieht. Codacy hat Duplikate gemeldet, die SonarCloud nicht markiert hatte. SonarCloud hat Signale für schlechte Qualität gemeldet (die berühmten code smells), die Codacy durchließ. CodeFactor hat Probleme mit der Komplexität gemeldet, die die beiden anderen ignorierten. Keines davon hätte allein gereicht. Die marginalen Kosten einer zusätzlichen Plattform sind null (kostenloses Badge, 5 Minuten Integration), also multiplizieren wir die Blickwinkel.
Tests: unittest stdlib (nicht pytest)
229 Tests, 0 Regressionen über die 6 Monate der PR, ~98 % Abdeckung für den neuen v1.9-Code.
Typisches Detail:
test_silent_failure.py: 97 Tests zur gezielten Doppelvalidierungtest_orchestration.py: 79 Tests auf der Orchestrator-Pipelinetest_translation_note_position.py: 38 Tests auf der Matrix Position × Formattest_audit_verdict.py: 15 Tests auf dem pip-audit-Wrapper (inscripts/tests/)
Ehrlichkeitshinweis: Die ~98 % Abdeckung betrifft den neuen v1.9-Code — nicht den gesamten historischen Umfang von translate.py, der noch einige geerbte Funktionen enthält, die von der neuen Testbatterie nur wenig abgedeckt sind. Ich erwähne das ausdrücklich, weil „98 % Abdeckung“ auf ein gesamtes Projekt zu behaupten irreführend wäre.
Diskutable, aber bewusste Wahl: Test-Runner unittest (stdlib), nicht pytest. Das Präfix test_ ist Gewohnheit, aber tatsächlich ist es unittest, das ausführt. Warum? In einem Projekt mit vibe coding gilt: jede hinzugefügte Abhängigkeit = jede Abhängigkeit, die die KI falsch benutzen kann. Einfachheit ist ein Ziel. unittest steckt in der Python-Standardbibliothek, keine Installation, kein Plugin.
Praxistests: Multi-Repo + interne Produktnutzung (dogfooding) + Prüfung des visuellen Renderings
Die 229 unittest-Tests reichen nicht aus. Ich füge drei Schichten Praxistest hinzu:
1. Multi-Repo — das Skript an mehreren öffentlichen Repos mit READMEs in verschiedenen Formaten testen. Das deckt Grenzfälle auf, die die Fixtures nicht abbilden — ein README mit 8 Heading-Ebenen, ein anderes mit geerbten Shortcodes, ein drittes mit exotisch eingebettetem Code. In dieser Phase wurde der silent-failure-Zwischenfall der Neuheit 1 entdeckt.
2. Dogfooding auf dem Blog — jls42.org wird vom Skript selbst übersetzt. Jeder veröffentlichte Artikel ist ein Live-Test in Produktion. Wenn ein Grenzfall durch die Unit-Tests rutscht, taucht er hier auf, auf der Seite, die Sie gerade lesen. Das ist der ultimative Test — was online ist, ist das, was das Projekt produziert hat.
3. Test des visuellen Renderings — ich prüfe, dass die gerenderten Übersetzungen korrekt angezeigt werden, entweder im Browser (finale Webseite) oder direkt in VSCode über ein Markdown-Vorschau-Plugin. Die Idee: sich nicht nur mit syntaktisch validem Markdown zufriedenzugeben, sondern das tatsächliche Rendering zu sehen. Visuelle Renderings bringen Darstellungsfehler ans Licht (kaputte Tabellen, fehlerhaft formatierte Codeblöcke, falsch interpretiertes Frontmatter), die textuelle Tests nicht sehen.
Auch die IAs beteiligen sich an diesen Tests. /pr-review-toolkit führt den Code in der Testumgebung aus, und die Nutzung im Pair-IA umfasst systematisch visuelle Validierungsdurchläufe („prüfe, ob die deutsche Übersetzung von Seite X korrekt angezeigt wird“).
📄 Auszug aus .pre-commit-config.yaml (Haupt-Pre-commit-Hooks)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Auszug aus scripts/check-security-sast.sh
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Auszug aus .github/workflows/sonarcloud.yml
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Schutzgeländer 2: die KI-gestützte Review + der Multi-Modell-Flow
Präzisierung des Vokabulars: Wenn ich in diesem Abschnitt von Claude Opus spreche, meine ich das Modell, das ich verwende, um v1.9 zu entwickeln — nicht das Modell, das AI-Powered Markdown Translator zum Übersetzen verwendet. Das Projekt selbst unterstützt 4 Provider (OpenAI, Mistral AI, Claude, Gemini) und jedes Modell (Sonnet, Haiku, Mistral Large, Gemini 3 Pro usw.). Auf Entwicklungsseite bin ich auf Opus festgelegt. Zur Laufzeit bleibt das Projekt agnostisch.
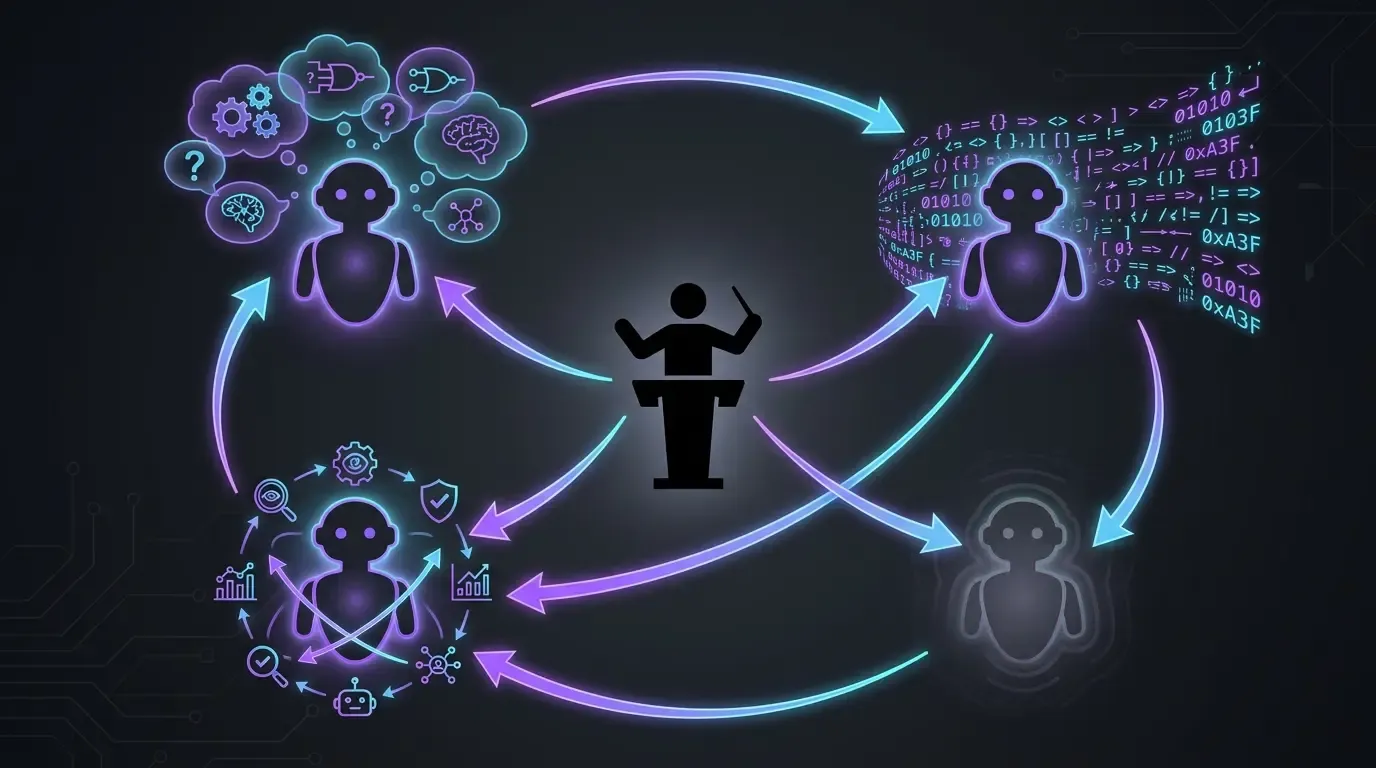
Der reale Arbeitsablauf: 4 Modelle, 4 Rollen (zum Entwickeln)
- Claude Code in Opus, ausschließlich (Anthropic): Hauptausführung. Liest den Kontext, schreibt den Code, wendet die Korrekturen an. Kein Sonnet, kein Haiku, kein fast mode. In diesem Projekt will ich jedes Mal das Spitzenmodell — die Idee ist einfach: Wir stellen sicher, dass wir das Beste haben, um das bestmögliche Ergebnis anzustreben.
- OpenAI Codex als Fallback (fallback): wird in zwei präzisen Fällen eingesetzt:
- Wenn Opus bei einem Thema scheitert (selten, aber es kommt vor — zum Beispiel bei Korrekturen, die von externen Agents wie Codacy oder SonarCloud angefordert werden; Claude kommt dann manchmal nicht zum Ziel, und ich verlagere das Thema auf Codex, um es zu lösen)
- Wenn das Anthropic-Nutzungskontingent erschöpft ist. Codex sorgt dafür, dass der Schwung nicht verloren geht, während ich auf das Zurücksetzen des Kontingents warte.
- GPT-5.5 reasoning extra-high (
xhigh): hinterfragt Pläne vor der Ausführung. Bevor ich Claude Code auf ein Thema loslasse, gebe ich den Plan an GPT-5.5 in reasoning extra-high. Es stellt die richtigen Fragen und deckt blinde Flecken auf. So vermeiden wir, in die falsche Richtung zu gehen und das später wieder einfangen zu müssen. /pr-review-toolkit:review-pr(Claude Code Skill-Plugin): Review vor dem Merge mit spezialisierten Agents (Sicherheit, Qualität, Tests, Kommentare, Typdesign). Der Skill läuft auf der PR, bevor ich merge — das ist das letzte KI-Sicherheitsnetz, bevor der Code inmainlandet.
Keines dieser Modelle reicht allein aus. Jedes spielt eine andere Rolle — der High-End-Ausführer, der Kapazitätsersatz, der Plan-Herausforderer, der Reviewer mit mehreren Blickwinkeln.
/pr-review-toolkit: Was ich nicht gesehen hätte
Alles. Ich schaue mir den Code nicht an. Der Skill bringt alles ans Licht — versteckte Bugs, Sicherheitsprobleme, Inkonsistenzen in den Tests, Tests, die grün sind, aber nichts testen.
Auf PR #2 (75 Commits, 9 837 Additions, 1 982 Deletions, 58 Dateien) hätte ein Mensch allein aus Müdigkeit 80 % der PR übersprungen. Der Skill überspringt nichts. Er liest jedes Diff, jeden Test, jeden Kommentar. Und vor allem hinterfragt er — er lehnt Muster ab, die er als schlecht einstuft, und schlägt Alternativen vor.
Der Mensch als Dirigent, nicht als Musiker
Meine Rolle deckt die gesamte Kette ab — außer dem Schreiben des Codes. Ich übernehme die Hüte Produktmanager (über Features nachdenken, priorisieren, abwägen), QA (auf realen Fällen testen, das Rendering visuell validieren), Tech Lead (Pläne mit GPT-5.5 reasoning extra-high hinterfragen), Endkunde (das Ergebnis an meiner eigenen täglichen Blog-Nutzung beurteilen). Der einzige Hut, den ich nicht trage, ist der des Codens. Der Rest bin ich.
Ich bin Produzent geworden, nicht Musiker.
Im Dienst des Blogs: Er übersetzt sich selbst (fast 1 800 Übersetzungen)
AI-Powered Markdown Translator generiert sein eigenes README in 14 Sprachen, und er ist es, der alle fremdsprachigen Versionen der Inhalte von jls42.org produziert. Konkret: fast 1 800 übersetzte Versionen versorgen den Blog (25 Artikel + 4 Projekte + 98 KI-News × 14 Sprachen, ohne FR-Quellen — also 1 778 Versionen zum Zeitpunkt, an dem ich schreibe). Jede Seite, die Sie hier in einer anderen Sprache als Französisch lesen, wurde durch dieses Projekt verarbeitet.
Das ist Produkt-Internal-Usage (dogfooding) bis zum Äußersten getrieben — und es stresst die Übersetzung auf dem Artikel, der über die Übersetzung spricht. Wenn das, was Sie in ar, hi oder ko lesen, stimmig ist, dann hält das Sicherheitsnetz von Neuerung 1 (Validierung nach der Übersetzung); wenn der Übersetzungshinweis korrekt oben angezeigt wird, funktioniert Neuerung 2 (Hinweis an mehreren Positionen); wenn die EN-Zitate in den Sprachversionen erhalten bleiben, dann funktioniert auch Neuerung 3 (Modus --news).
Fazit: rigoroses KI-Pairing, kein schlampiges KI-Pairing
Entwicklung aus dem Bauch heraus hat aus guten Gründen einen schlechten Ruf. Genau dagegen arbeite ich an. Vier konkrete Lehren lassen sich aus dieser v1.9 ableiten:
-
Stille Fehlschläge sind der Feind Nummer eins. Die KI erzeugt Code, der okay aussieht und die Unit-Tests passiert. Systematische Validierung auf Client-Seite. Und eine andere KI nutzen, um die echte Ausgabe zu prüfen, nicht nur den Code.
-
Pre-commit-Hooks unter 10 s, sonst werden sie umgangen; pre-push dürfen 30 s+ dauern. Die KI fügt gern Tools hinzu, ohne ihre Kosten zu berücksichtigen. Das muss man manuell rahmen, entweder im Plan oder im Nachhinein — wichtig ist, dass die Hooks am Ende richtig eingestellt sind und im Alltag auch tatsächlich genutzt werden.
-
Abdeckung ohne starke Assertion ist Theater. Die KI kann 200 Tests erzeugen, die grün sind und nichts testen. unittest + präzise Assertions > pytest mit Unmengen an Mocks. Die zurückgegebene(n) Werte prüfen, nicht nur, dass der Code nicht abgestürzt ist.
-
KI-PR-Review ist keine Option. Wenn der menschliche Autor nicht gegengelesen hat, ist der KI-Reviewer kein Gimmick — er ist das delegierte Auge.
Vibe Coding richtig gemacht heißt auch, zu akzeptieren, dass man den Code nicht liest, und die kritische Lektüre anderen IAs zu überlassen, die das wirklich tun.
Was dieses Projekt offenbart
Diese v1.9 zeigt mehrere Aspekte meiner Arbeitsweise:
- Die menschliche Rolle deckt die ganze Kette außer dem Code ab: Produkt (über Features nachdenken, priorisieren), QA (auf realen Fällen testen, visuell validieren), Tech Lead (Pläne mit einem LLM in reasoning extra-high hinterfragen), Endkunde (an der realen Nutzung beurteilen). Der einzige Hut, den ich nicht trage, ist Codieren.
- Die Sicherheitsnetze verdoppeln, nicht abschaffen: weniger menschliches Review = mehr instrumentierte Validierung. Ein bewusster Kompromiss, kein Mangel an Strenge. Wenn ich das Review entferne, muss ich die Sicherheitsnetze verdoppeln, nicht blind der KI vertrauen.
- KI nutzen, um die Bugs der KI zu entdecken: Der stille Fehlschlag wurde von Claude während der praktischen Multi-Repo-Tests gefunden. Vollständige Delegation: Man kann auch die kritische Nachprüfung delegieren.
- KI-Pairing als Multiplikator für die private Zeit: Ich trage dieses Projekt an meinen Abenden und Wochenenden. Ohne KI-Pairing würde ich ganz klar weder so weit noch so schnell kommen. Mit ihm kann ich ein Open-Source-Projekt auf Industrieniveau neben meinen anderen Verpflichtungen aufrechterhalten. Das ist es, was Vibe Coding möglich macht — nicht den Entwickler zu ersetzen, sondern ihm zu ermöglichen, das zu tun, was er allein nicht könnte.
- Iterieren statt alles neu machen: 9 Versionen, inkrementelles Refactoring (1 Funktion → 7 Helfer), Rückwärtskompatibilität bewahrt. Das KI-Pairing hilft, schnell zu iterieren, ohne alles neu zu schreiben.
Ressourcen
- AI-Powered Markdown Translator auf GitHub
- Version v1.9
- PR #2 — 75 Commits, Migration + Qualität
- Vollständiges CHANGELOG
- Projektseite in diesem Blog
- Artikel 2024 — v1.5 (Stil der Release Notes) — zum Vergleich des Tons
- Deep Dive AWS-Diagramm — ein weiterer Artikel der Serie
Wenn Sie AI-Powered Markdown Translator mit Ihren eigenen Markdown-Dateien testen möchten — Open-Source-README, Blogartikel, technische Dokumentation —, der Code ist auf GitHub. Installation in wenigen Minuten, 4 unterstützte Provider, Modus --eco zur Kostensenkung, Modus --news zum Erhalt der Quellzitate, und inzwischen ein Qualitäts-Stack v1.9, den Sie als Vorlage für Ihre eigenen KI-Pairing-Projekte wiederverwenden können.
Wenn Sie Ihre persönlichen Projekte aus dem Bauch heraus (Vibe Coding) entwickeln, sparen Sie nicht ausgerechnet an der Qualität. Zuverlässigkeit ist der Preis der Geschwindigkeit — stehen Sie zu beidem zugleich.