ai-powered-markdown-translatorArticol tradus din fr în ro cu gpt-5.4-mini.
AI-Powered Markdown Translator este un proiect open-source pe care îl mențin din 2024: un script Python care traduce orice fișier Markdown în 14 limbi prin 4 provideri IA (OpenAI, Mistral AI, Claude, Gemini). El alimentează acest blog la fiecare publicare — orice pagină pe care o citești aici într-o limbă alta decât franceza a trecut prin el — și aproape 1 800 de versiuni traduse rulează datorită lui în producție.
Pe 8 mai 2026, am publicat v1.9, care adună 75 de commit-uri și marchează cea mai mare actualizare de la v1.5 din 2024. Trei noutăți de produs:
- Validare post-traducere (anti-eșec silențios)
- Notă de traducere multi-poziție (sus, jos sau ambele)
- Mod
--newspentru a păstra citatele sursă EN
Dar această v1.9 are o particularitate pe care vreau s-o spun aici: tot codul a fost scris în pair-IA. Niciun rând tastat de mână. Așadar, pe lângă cele 3 noutăți, articolul abordează și „cum”: ce măsuri de protecție pui în loc pentru a ținti un cod curat și sigur când nu mai revizuiești tu însuți ceea ce produce IA?
Contextul: un proiect folosit zilnic, întreținut puțin pe partea de cod
Din septembrie 2024 până în mai 2026: utilizare continuă, întreținere în rafale
Publicasem un articol care detalia codul sursă al v1.5 în 2024. La vremea aceea, publicam scriptul direct în articol. Azi, unghiul s-a schimbat: ceea ce contează nu mai este atât codul pe care îl scriu, cât fluxul de lucru care îl produce.
Între v1.5 publicată în septembrie 2024 și ianuarie 2026, proiectul a continuat să ruleze — traduce fiecare conținut nou al acestui blog — dar codul public aproape că nu s-a mișcat. Un singur commit a fost împins în 2025. În tot acest timp, am făcut codul să evolueze local pentru nevoile mele personale — mai ales modelele, pe care le înlocuiam pe măsură ce apăreau noi versiuni — dar aceste evoluții rămâneau pe mașina mea. Versiunea publică de pe GitLab continua să indice valorile implicite ale v1.5.
La începutul lui 2026, am făcut un prim efort de aducere la zi: trei release-uri în două luni (v1.6 și v1.7 în două zile la început de ianuarie, v1.8 în martie) care au adus proiectul la zi pe partea de funcționalități — modele 2026, suport Gemini, mod --eco, fișier unic, mod --news pentru citatele sursă. Dar tot fără CI, fără teste automate, fără gates de calitate — ceea ce îmi crea o problemă reală dacă voiam să merg mai departe cu un agent IA care codează în locul meu.
Ritmul unui proiect făcut în timpul liber
De ce această diferență? Pentru că duc proiectul acesta în timpul meu liber. Am o familie, o viață în afara ecranului, deci evoluția avansează doar în rafale când găsesc serile și weekendurile. Sunt pasionat, petrec totuși destul de mult timp pe aceste subiecte — testez mult, ghidez agenții, validez rezultatele — dar ritmul nu este cel al unui proiect profesional.
Pair-IA schimbă exact asta. Îmi permite să avansez între două constrângeri — pasiunea și dozajul vieții din afara ecranului. Fără pair-IA, clar nu aș merge atât de departe și nici atât de repede. Cu el, pot menține un proiect open-source la nivel industrial fără să-mi dedic viața lui.
Obiectivul inițial: calitate + migrarea GitLab → GitHub
La mijlocul lui aprilie 2026, am vrut în sfârșit să mă ocup serios de el. Două obiective simple:
- Să adaug un strat de calitate (analiză statică, teste, CI)
- Să migrez repo-ul din GitLab în GitHub
Nimic mai mult. Doar că, cu un agent de cod în pair-IA, nu scrii niciodată exact ce era planificat. PR-ul a ajuns la 75 de commit-uri, 9 837 de adăugiri, 1 982 de ștergeri, 58 de fișiere.
| Versiune | Dată | Contribuție principală |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, apoi Mistral, apoi Claude |
| 1.5 | sept. 2024 | Refactorizare clienți, modele 2024 (gpt-4o, claude-3.5-sonnet) |
| 1.6 | ian. 2026 | Modele 2026 (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, mod --eco, fișier unic (--file) |
| 1.7 | ian. 2026 | --keep_filename, .env, cod inline păstrat |
| 1.8 | mart. 2026 | Modele GPT-5.4 implicite, mod --news cu placeholder-e pentru citate |
| 1.9 | mai 2026 | Validare post-traducere, notă multi-poziție, stack de calitate 14 hooks + 229 teste + revizuire IA |
Efectul bulgărelui de zăpadă
Fiecare instrument de calitate adăugat scotea la iveală probleme. Codacy a raportat duplicări. SonarCloud a semnalat code smells (semne că un cod va îmbătrâni prost: funcții prea lungi, parametri nefolosiți, structuri încâlcite). /pr-review-toolkit a indicat buguri ascunse. La fiecare raport, agentul corecta, uneori îmbunătățind și lucruri adiacente.
Perimetrul a explodat organic. Exact asta îmi doream — să modernizez proiectul — dar dozajul efortului era dictat de instrumente, nu de mine. Pentru un proiect în vibe coding, acesta este un punct-cheie: instrumentele de calitate orientează munca la fel de mult pe cât o verifică.
Noutatea 1: validarea post-traducere (anti-eșec silențios)
Incidentul: chiar IA a găsit bugul, în timpul testelor
În timp ce testam PR-ul pe README-uri din diferite repo-uri publice — un caz acoperit de nicio fixture —, IA a raportat ceea ce îmi scăpase: pentru anumite limbi (în special hindi, cod ISO hi), anumite pasaje rămâneau în limba sursă în mijlocul traducerii. API-ul returnase 200, scriptul scrisese fișierul, dar conținutul era tradus doar pe jumătate. Și asta trecea prin bateria existentă de teste unitare — care nu acoperea acest caz real multilingv.
Este exact genul de bug pe care vibe coding-ul îl poate produce și pe care nimeni nu-l vede. Codul pare logic, fixture-urile de test nu acoperă cazul, omul nu revizuiește rezultatul. Doar că aici, testând scriptul pe cazuri reale (multi-repo), chiar IA a făcut ceea ce fixture-urile nu făceau.
Ce rețin de aici: testele practice multi-repo găsesc ceea ce testele unitare ratează. Și IA poate servi și la descoperirea bugurilor agenților IA anteriori — cu condiția să o pui în fața unor cazuri reale, variate.
În acel moment am înțeles că trebuie să adaug o adevărată validare post-traducere. Aceasta este prima noutate pe care o detaliu acum: dublul strat de validare.
Dublul strat de validare
| Pas | Acțiune | Dacă eșuează |
|---|---|---|
| 1️⃣ | Apel API provider | Excepție de rețea → ❌ eșec |
| 2️⃣ | Whitelist pe provider pentru finish_reason (sau stop_reason la Claude) | În afara whitelist-ului → ❌ eșec |
| 3️⃣ | Anti-scurgere: nicio fereastră sursă de ≥ 120 caractere verbatim în output | Fereastră sursă regăsită → ❌ eșec |
| 4️⃣ | langdetect.detect_langs (probabilități sursă vs target) | Sursă > 0,80 ȘI target < 0,20 → ❌ eșec |
| 5️⃣ | Empty-content + raport output/sursă (dacă sursa ≥ 500 caractere) | Gol sau output < max(50, source/20) → ❌ eșec |
| ✅ | SUCCESS | exit code 0 |
Stratul 1 (determinist) — Primul filtru: verificarea statusului returnat de API. Fiecare provider expune un câmp finish_reason (sau stop_reason la Claude) care indică de ce LLM-ul s-a oprit din generare. Scriptul menține o whitelist pe provider pentru statusurile acceptabile — nomenclatura variază (stop la OpenAI/Mistral, STOP sau FINISH_REASON_STOP la Gemini, end_turn sau stop_sequence la Claude). Codul tolerează și None din motive de siguranță, atunci când SDK-ul nu returnează acest câmp. Orice alt status — de exemplu length, max_tokens sau MAX_TOKENS în funcție de provider, care semnalează un răspuns oprit de limita de token-uri — declanșează un RuntimeError imediat, fără nicio tentativă de recuperare.
Al doilea filtru determinist, mai subtil: verificarea faptului că nicio porțiune din textul sursă nu apare verbatim în output-ul tradus. Concret, extragem ferestre de 120 de caractere sau mai multe din textul sursă; dacă una dintre ele se regăsește identic în output, înseamnă că nu a fost tradusă — failure. Exact acest check a recuperat cazul hindi: LLM-ul răspunsese stop (deci final „natural” din partea API-ului), dar paragrafe franceze rămăseseră intacte în output — invizibile pentru filtrul finish_reason, detectate de filtrul anti-scurgere verbatim.
Stratul 2 (probabilistic) — langdetect.detect_langs analizează limba output-ului și returnează o distribuție de probabilități pentru mai multe limbi candidate. Extragem probabilitatea limbii sursă și pe cea a limbii țintă, apoi respingem numai dacă probabilitatea sursă depășește 0,80 și probabilitatea țintă cade sub 0,20 — un prag deliberat conservator, pentru a nu produce false pozitive pe code-switching tehnic (de exemplu, cuvinte englezești legitime într-o traducere franceză). Acest strat se oprește pentru limbile cu scripturi non-latine (hindi hi, arabă ar, chineză zh, japoneză ja, coreeană ko), unde un semnal de script suficient validează deja output-ul. Și rulează doar dacă output-ul curățat are cel puțin 100 de caractere, pentru a evita false pozitive pe text prea scurt.
Barierele cantitative
Peste cele două straturi, două controale mai prozaice, dar necesare:
- Protecție pentru conținut gol: dacă providerul returnează un output gol deși
finish_reasonestestop, respingem imediat totul (altfel am scrie un fișier gol marcat ca success) - Raport de siguranță: doar dacă sursa are cel puțin 500 de caractere, verificăm că output-ul nu este suspect de scurt (de obicei <
max(50, source/20)). Este un detector de trunchiere invizibilă, nu o regulă generală de lungime
Pe Claude în mod specific, max_tokens a trecut de la 4 096 la 32 768 în v1.9 (modificarea a fost făcută în cod de Claude după ce am constatat simptomul și am cerut investigarea). Motivul documentat în CHANGELOG: evitarea trunchierii latente pe segmente de 16 k caractere, cu o marjă suplimentară pentru limbile cu script non-latin (FR → JA, ZH, KO, AR, HI), care consumă mai multe token-uri la ieșire decât un script latin echivalent.
Răspunsuri prin statut explicit
Pipeline-ul pe fișier (translate_markdown_file()) returnează acum un statut explicit — success, failure sau skipped. CLI-ul agregă aceste statusuri și se încheie cu un cod de ieșire nenul de îndată ce cel puțin un fișier a eșuat — ceea ce face eșecul exploatabil de un script apelant sau de noul CI adăugat în v1.9. Înainte de această v1.9, mai multe erori erau doar afișate sau treceau ca și cum traducerea ar fi reușit: procesul putea să se termine în 0 chiar dacă fișierul lipsea, era incomplet sau fusese validat greșit. Statutul skipped devine el însuși un semnal lizibil („ignorat intenționat”), distinct de success („traducere scrisă corect”).
📄 Fragment Python: dublă validare post-traducere (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNoutatea 2: nota de traducere multi-poziție
Nevoia: o notă discretă, dar informativă
Când AI-Powered Markdown Translator scrie o traducere, adaugă o notă de traducere care indică modelul folosit și data. Înainte de v1.9, această notă era lipită sistematic jos în fișier, într-un format moștenit (legacy) cu delimitatori vizibili.
Formatul lipit jos crea două probleme pentru utilizările mele. Mai întâi, cititorul era informat abia la final că respectivul conținut fusese tradus de IA — e mai bine să avertizezi de la început, astfel setezi corect așteptarea privind conținutul. Apoi, nota de la subsol nu punea în valoare proiectul de traducere care face totul posibil: citești articolul, iar originea fluxului multilingv trece neobservată. Voiam deci să pot muta nota sus, păstrând în același timp trasabilitatea — fără să stric utilizările existente. v1.9 adaugă două flag-uri care nu strică nimic:
--note_position {top,bottom,both}: sus, jos sau ambele--note_format {legacy,marker}: format moștenit sau format marker (marker format)
Implicit, retrocompatibil: legacy + bottom. Niciun șir de traducere existent nu își schimbă comportamentul implicit — activăm explicit noile flag-uri la cerere.
Formatul marker: o carte încorporată (embed card) GitHub curată
Formatul marker exploatează un detaliu subtil al Markdown-ului GitHub: link reference definitions nefolosite sunt invizibile în randare. Putem deci codifica metadate (model, dată, sursă) într-un comentariu-marker poziționat în partea de sus a fișierului — invizibil în browser, dar păstrat identic la copierea brută.
În plus, GitHub generează o carte încorporată (embed card) când partajezi un link către fișierul tradus, iar această carte afișează corect titlul documentului fără poluare textuală.
Exemplu de Markdown brut cu format marker în poziția top :
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...La vedere, cititorul nu vede decât titlul urmat de conținut. Markerul nu poluează nici randarea HTML, nici cartea de embed.
Inserarea conștientă a frontmatter-ului (frontmatter-aware)
Detaliu tehnic, dar crucial: a insera o notă în top nu înseamnă « a insera pe linia 1 a fișierului ». Dacă fișierul are un frontmatter YAML (ceea ce este cazul pentru acest blog), trebuie să inserăm după frontmatter — altfel nota strică YAML-ul.
I-am dat lui Claude cerința (« inserează nota după frontmatter, nu înainte — altfel strici YAML-ul »), iar el a scos un helper _split_frontmatter care detectează fence-urile --- deschis/închis. Dacă fișierul are un fence YAML neînchis (caz malformat), helperul aruncă o RuntimeError în loc să producă în liniște un fișier stricat. Trecerea de la o funcție monolitică la 7 helpers puri (separați și testabili) este tipică pentru ceea ce pair-IA bine ghidat știe să facă repede. Rolul meu aici: ghid al cerinței, tester, client final care validează rezultatul. Nu scriu cod. Pe acest proiect port mai multe pălării — în afară de aceea de a scrie codul, care îi revine lui Claude.
| Poziție | Format | Caz de utilizare tipic |
|---|---|---|
top | marker | Articole de blog (notă discretă, card embed curat) |
top | legacy | Document intern unde trasabilitatea vizibilă contează |
bottom | marker | README open-source (coerent cu footer-ul) |
bottom | legacy | Implicit — compatibil cu versiunile anterioare |
both | marker | Articole lungi în care top + bottom liniștesc |
both | legacy | Caz legacy cu cerință de dublă trasabilitate |
📄 Fragment Python: helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")Noutatea 3: modul --news pentru a păstra citatele-sursă în EN
Problema: a traduce fără a strica citatele
Când scriu articole ia-actualites pentru acest blog (știri IA multi-sursă zilnice/săptămânale), citez regulat tweet-uri, articole de blog, anunțuri de versiune în engleză — adesea mai multe pe articol. Dacă traducerea atinge citatele, ele devin false.
Un citat tradus este un citat alterat. În toate versiunile lingvistice (EN, DE, JA, etc.), vrem să păstrăm engleza originală a citatelor — aceasta este o cerință de fidelitate față de surse — însoțită de drapelul limbii țintă și de o traducere în italice pentru confortul lecturii.
Soluția: placeholder-ele <NEWSQUOTE id="N"/>
| Pas | Acțiune |
|---|---|
| 1️⃣ | Markdown sursă FR cu citate EN la intrare |
| 2️⃣ | Pre-procesare: extragerea citatelor EN, înlocuire cu placeholder-e <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, etc. |
| 3️⃣ | Traducere API (FR → target_lang) — citatele EN originale nu sunt niciodată trimise la LLM, doar placeholder-ele sunt (păstrate exact așa) |
| 4️⃣ | Post-procesare: restaurarea placeholder-elor cu citatele EN originale intacte + inserarea drapelului limbii țintă |
| 5️⃣ | Validare post-traducere: au fost restaurate toate placeholder-ele? |
| ✅ | Ieșire țintă cu citatele EN păstrate |
| ❌ | Eșec dacă un placeholder nu este restaurat sau dacă un citat este alterat |
Modul --news se bazează pe acest principiu: o pre-procesare extrage toate citatele EN, le înlocuiește cu placeholder-e de tip <NEWSQUOTE id="0"/>, traduce restul, restaurează placeholder-ele intacte.
Mapping-ul LANG_FLAGS adaptează drapelul la target_lang (15 limbi acoperite): 🇬🇧 pentru engleză, 🇩🇪 pentru germană, 🇪🇸 pentru spaniolă, 🇮🇹 pentru italiană, 🇵🇹 pentru portugheză, 🇳🇱 pentru neerlandeză, 🇵🇱 pentru poloneză, 🇸🇪 pentru suedeză, 🇷🇴 pentru română, 🇸🇦 pentru arabă, 🇮🇳 pentru hindi, 🇯🇵 pentru japoneză, 🇰🇷 pentru coreeană, 🇨🇳 pentru chineză, 🇫🇷 pentru franceză.
Validarea post-traducere verifică faptul că toate placeholder-ele sunt restaurate intacte. Eroarea nu este o « scurgere EN » — EN-ul este dorit — ci un placeholder nerestaurat sau un citat alterat.
Cazuri de utilizare actuale și perspective
Astăzi, folosesc --news exclusiv pe articolele ia-actualites ale blogului. Pe termen lung, asta ar putea fi extins la orice articol care îmbină proză franceză și citate-sursă EN — interviuri, feedback-uri de experiență care citează articole de cercetare în engleză, transcrieri ale prezentărilor de conferință.
Fără a reciti codul: de ce trebuie dublate măsurile de siguranță
« Nu citesc codul. »
Nu recitesc nimic. Uneori mă uit rapid la un diff — se întâmplă rar, și doar când Claude nu se descurcă singur pe un punct. Iată fluxul pe care îl folosesc zilnic și care a produs v1.9: Claude Code (exclusiv Opus) tastează codul. Codex preia ștafeta când Opus se blochează sau când fereastra de utilizare este saturată. GPT-5.5 în reasoning extra-high provoacă planurile înainte de execuție. /pr-review-toolkit:review-pr recitește PR-ul înainte de fiecare merge. Rolul meu se oprește la validarea direcțiilor și definirea măsurilor de siguranță.
Acest mod de dezvoltare — dezvoltare integrală la feeling (vibe coding) — nu este o lipsă de rigurozitate. Este un compromis explicit: mai puțină recitire umană, mai multă validare asistată de instrumente. Cele 3 noutăți v1.9 pe care tocmai le-am prezentat au fost toate produse în acest flux. Și tocmai pentru că nu se recitește codul trebuie să dublăm măsurile tehnice de siguranță — nu să le eliminăm.
Iată cele două măsuri de siguranță puse în aplicare pentru a face acest mod de dezvoltare viabil în producție: un stack de calitate automatizat (Măsura de siguranță 1) și o revizie asistată de IA în flux multi-model (Măsura de siguranță 2).
Măsura de siguranță 1: stack-ul de calitate automatizat (14 hook-uri + teste practice)
Privire de ansamblu
| Plasă | Instrumente | Cost tipic | Blochează dacă eșuează |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hook-uri), detect-secrets, Lizard CCN | < 10 s | Da |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Da, cu excepția pip-audit în raportare inițială |
| CI extern | SonarCloud, Codacy, CodeFactor | în paralel | Nu blochează local, badge-uri PR |
Cifre v1.9: 14 hook-uri, 229 de teste unittest stdlib, ~98 % acoperire pe noul cod v1.9, 11 badge-uri SonarCloud, 3 platforme externe.
Pre-commit: plasa rapidă
| # | Instrument | Versiune | Rol |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Lint shell |
| 2 | ruff (lint) | 0.8.6 | Lint Python |
| 3 | ruff (format) | 0.8.6 | Formatare Python |
| 4 | prettier | 3.1.0 | Formatare Markdown / JSON / YAML |
| 5 | trailing-whitespace | 5.0.0 | Eliminarea spațiilor de la sfârșitul liniei |
| 6 | end-of-file-fixer | 5.0.0 | Linie nouă finală obligatorie |
| 7 | check-yaml | 5.0.0 | Validare sintaxă YAML |
| 8 | check-toml | 5.0.0 | Validare sintaxă TOML |
| 9 | check-added-large-files | 5.0.0 | Blochează binarele mari adăugate accidental |
| 10 | check-merge-conflict | 5.0.0 | Detectarea marcatorilor de conflict Git |
| 11 | check-executables-have-shebangs | 5.0.0 | Verifică dacă executabilele au un shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Verifică dacă scripturile cu shebang sunt executabile |
| 13 | detect-secrets | 1.5.0 | Detectarea cheilor API și a secretelor |
| 14 | check-complexity (Lizard) | local | Prag de complexitate ciclomatică pe noul cod |
Total măsurat: aproximativ 2 până la 3 secunde pe întregul repo (la cald, pre-commit run --all-files cronometrat la ~2,4 s). Pe un commit mediu care atinge doar câteva fișiere, este și mai rapid. Regula de bun-simț pe care o aplic: peste 10 s, dezvoltatorii ocolesc (și pair-IA-ul la fel) — deci trebuie păstrată permanent această plasă rapidă.
Pre-push: plasa grea
- mypy în mod lax: nu există strict total (codul istoric din translate.py nu ar trece), dar există o verificare de progres pe noul cod
- Opengrep SAST:
p/security-audit p/default p/python— aproximativ 30 de secunde pentru a scana injecții, eval, deserializare nesigură - pip-audit împachetat de
scripts/check-pip-audit.sh: capturează ieșirea JSON, clasifică pe partea de shell erorile de transport (rețea, PyPI indisponibil) pentru a nu confunda vulnerabilitatea cu indisponibilitatea și raportează vulnerabilitățile. În mod de raportare inițial pentru v1.9 (warn + exit 0) — de întărit în blocare după un PR de actualizare a dependențelor învechite. - unittest discovery:
python -m unittest discoverpetests/și apoiscripts/tests/— 229 de teste, aproximativ 8 secunde local
CI extern: SonarCloud + Codacy + CodeFactor
Workflow-ul .github/workflows/sonarcloud.yml (project key jls42_ai-powered-markdown-translator) rulează pe fiecare PR. 11 badge-uri SonarCloud afișate pe README: Quality Gate, rating de Security/Reliability/Maintainability, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC.
De ce redundanța Codacy + SonarCloud + CodeFactor? Pentru că fiecare vede lucruri diferite. Codacy a semnalat duplicări pe care SonarCloud nu le-a semnalat. SonarCloud a semnalat indicii de calitate slabă (celebrele code smells) pe care Codacy le-a lăsat să treacă. CodeFactor a semnalat probleme de complexitate pe care celelalte două le-au ignorat. Niciunul singur n-ar fi fost suficient. Costul marginal al unei platforme suplimentare este zero (badge gratuit, integrare de 5 minute), deci multiplicăm unghiurile.
Teste: unittest stdlib (nu pytest)
229 de teste, 0 regresii pe parcursul celor 6 luni ale PR-ului, ~98 % acoperire pe noul cod v1.9.
Detaliu tipic:
test_silent_failure.py: 97 de teste care vizează dublă validaretest_orchestration.py: 79 de teste pe pipeline-ul orchestratortest_translation_note_position.py: 38 de teste pe matricea poziție × formattest_audit_verdict.py: 15 teste pe wrapper-ul pip-audit (înscripts/tests/)
Notă de onestitate: acoperirea de ~98 % privește noul cod v1.9 — nu întreg istoricul translate.py, care mai conține câteva funcții moștenite slab acoperite de noua suită de teste. Menționez explicit asta, pentru că a anunța « 98 % acoperire » pentru un proiect întreg ar fi înșelător.
Alegere discutabilă, dar asumată: executor de teste unittest (stdlib), nu pytest. Prefixul test_ este din obișnuință, dar unittest este cel care execută. De ce? Pe un proiect în vibe coding, fiecare dependență adăugată = fiecare dependență pe care IA o poate folosi greșit. Simplitatea este un obiectiv. unittest este în biblioteca standard Python, zero instalare, zero plugin.
Teste practice: multi-repo + utilizare internă a produsului (dogfooding) + verificarea randării vizuale
Cele 229 de teste unittest nu sunt suficiente. Adaug trei straturi de teste practice:
1. Multi-repo — testarea scriptului pe mai multe repo-uri publice cu README-uri în formate diferite. Asta scoate la iveală cazuri-limită pe care fixture-urile nu le acoperă — un README cu 8 niveluri de heading, altul cu shortcode-uri moștenite, un al treilea cu cod încorporat exotic. În această fază a fost descoperit incidentul de eșec silențios al Noutății 1.
2. Dogfooding pe blog — jls42.org este tradus chiar de scriptul însuși. Fiecare articol publicat este un test live în producție. Dacă un caz-limită scapă prin testele unitare, va ieși la iveală aici, pe pagina pe care o citești. Acesta este testul suprem — ceea ce este online este ceea ce a produs proiectul.
3. Testul randării vizuale — verific că traducerile randate se afișează corect, fie în browser (pagina web finală), fie direct în VSCode printr-un plugin de previzualizare Markdown. Ideea: să nu mă mulțumesc cu un Markdown valid sintactic, ci să văd randarea reală. Randările vizuale scot la iveală bug-uri de aspect (tabele stricate, code blocks malformate, frontmatter interpretat greșit) pe care testele text nu le văd.
IA-urile participă și ele la aceste teste. /pr-review-toolkit execută codul în mediu de test, iar utilizarea în pair-IA include sistematic treceri de validare vizuală (« verifică dacă traducerea germană a paginii X se afișează bine »).
📄 Fragment .pre-commit-config.yaml (hook-uri pre-commit principale)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Fragment scripts/check-security-sast.sh
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Fragment .github/workflows/sonarcloud.yml
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Măsura de siguranță 2: revizia asistată de IA + fluxul multi-model
Precizare de vocabular: când vorbesc despre Claude Opus în această secțiune, vorbesc despre modelul pe care îl folosesc pentru a dezvolta v1.9 — nu despre modelul pe care AI-Powered Markdown Translator îl folosește pentru a traduce. Proiectul însuși suportă 4 provideri (OpenAI, Mistral AI, Claude, Gemini) și orice model (Sonnet, Haiku, Mistral Large, Gemini 3 Pro, etc.). Pe partea de dezvoltare, mă blochez pe Opus. Pe partea de utilizare la execuție, proiectul rămâne agnostic.
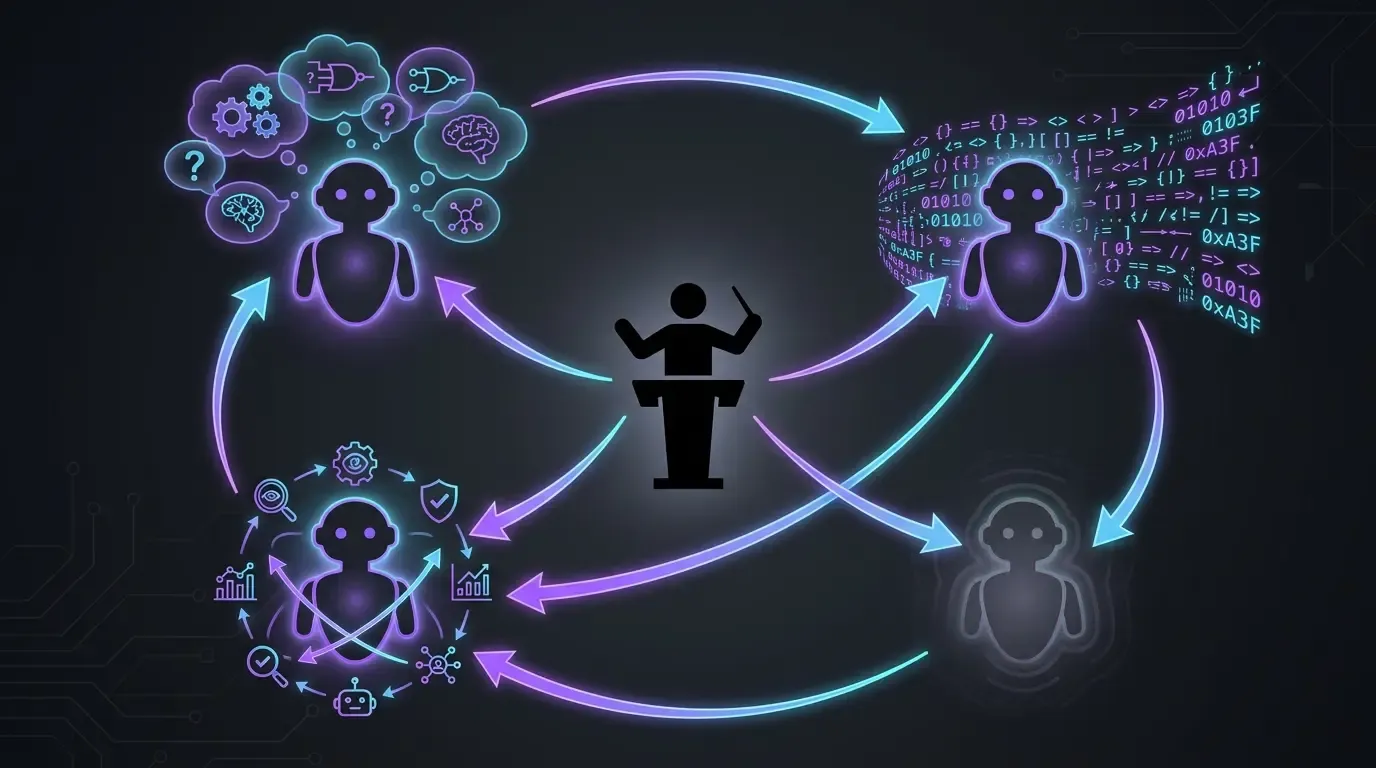
Fluxul de lucru real: 4 modele, 4 roluri (pentru dezvoltare)
- Claude Code în Opus, exclusiv (anthropic) : execuție principală. Citește contextul, scrie codul, aplică corecțiile. Fără Sonnet, fără Haiku, fără fast mode. Pe acest proiect, vreau modelul high-end de fiecare dată — ideea e simplă: ne asigurăm că avem ce e mai bun ca să vizăm cel mai bun rezultat posibil.
- OpenAI Codex ca soluție de rezervă (fallback) : folosit în două cazuri precise :
- Când Opus se blochează pe un subiect (rar, dar se întâmplă — de exemplu la corecții cerute de agenți externi de tip Codacy sau SonarCloud, Claude nu converge uneori și mut subiectul pe Codex ca să deblochez situația)
- Când fereastra de utilizare Anthropic este saturată. Codex permite să nu pierd avântul în așteptarea resetării cotelor.
- GPT-5.5 reasoning extra-high (
xhigh) : contestă planurile înainte de execuție. Înainte să las Claude Code să atace un subiect, trec planul prin GPT-5.5 în reasoning extra-high. Pune întrebările potrivite, scoate la lumină unghiurile moarte. Asta evită să pornesc pe o direcție greșită, pe care ar trebui s-o repar mai târziu. /pr-review-toolkit:review-pr(skill plugin Claude Code) : revizuire înainte de merge cu agenți specializați (securitate, calitate, teste, comentarii, concepția tipurilor). Skill-ul rulează pe PR înainte să fac merge — e ultima plasă de siguranță IA înainte ca codul să intre înmain.
Niciunul dintre aceste modele nu este suficient singur. Fiecare joacă un rol diferit — executorul high-end, supleantul de capacitate, challenger-ul de planuri, revizorul (reviewer) din mai multe unghiuri.
/pr-review-toolkit : ce n-aș fi observat
Totul. Nu mă uit la cod. Skill-ul ridică totul — bug-uri ascunse, probleme de securitate, inconsistențe în teste, teste care trec dar nu testează nimic.
Pe PR-ul #2 (75 commit-uri, 9 837 additions, 1 982 suppressions, 58 fișiere), un om singur ar fi sărit peste 80 % din PR din oboseală. Skill-ul nu sare peste nimic. Citește fiecare diff, fiecare test, fiecare comentariu. Și, mai ales, contestă — refuză pattern-urile pe care le identifică drept greșite și propune alternative.
Omul ca dirijor, nu ca muzician
Rolul meu acoperă toată lanțul — cu excepția scrierii codului. Iau pe rând pălăriile de product manager (să mă gândesc la features, să prioritizez, să arbitrez), QA (să testez pe cazuri reale, să validez vizual randarea), tech lead (să contest planurile cu GPT-5.5 reasoning extra-high), client final (să judec rezultatul după propria mea experiență de utilizare de zi cu zi pe blog). Singura pălărie pe care nu o port este cea de codare. Restul sunt eu.
Am devenit producător, nu muzician.
În slujba blogului: se traduce singur (aproape 1 800 de traduceri)
AI-Powered Markdown Translator își generează propriul README în 14 limbi, iar el produce toate versiunile în limbi străine ale conținuturilor de pe jls42.org. Concret: aproape 1 800 de versiuni traduse alimentează blogul (25 de articole + 4 proiecte + 98 de actualități IA × 14 limbi, fără sursele FR — adică 1 778 de versiuni în momentul în care scriu). Orice pagină pe care o parcurgeți aici într-o limbă alta decât franceza a trecut prin acest proiect.
Este dogfooding dus la extrem — și stress-testează traducerea pe articolul care vorbește despre traducere. Dacă ceea ce citiți în ar, hi sau ko este coerent, înseamnă că plasa Noutății 1 (validare post-traducere) ține; dacă nota de traducere se afișează corect în partea de sus, înseamnă că Noutatea 2 (nota multi-poziție) funcționează; dacă citatele EN sunt păstrate în versiunile lingvistice, înseamnă că Noutatea 3 (modul --news) merge și ea.
Concluzie: pair-IA riguros, nu pair-IA de mântuială
Dezvoltarea la feeling are o reputație proastă din motive întemeiate. Exact împotriva lor lucrez. Din această v1.9 ies patru lecții concrete:
-
Eșecurile silențioase sunt dușmanul numărul unu. IA produce cod care pare OK și trece prin testele unitare. Validare sistematică pe partea de client. Și folosirea altei IA pentru a revizui producția reală, nu doar codul.
-
Hooks pre-commit sub 10 s, altfel sunt ocolite; pre-push pot dura 30 s+. IA adaugă cu plăcere unelte fără să le ia în calcul costul. Trebuie încadrate manual, fie în plan, fie ulterior — important este ca, la final, hook-urile să fie bine configurate și efectiv folosite în viața de zi cu zi.
-
Acoperire fără aserțiune puternică = teatru. IA poate genera 200 de teste care trec și nu testează nimic. unittest + aserțiuni precise > pytest cu mocks din belșug. Verifică valoarea returnată, nu doar că nu s-a prăbușit codul.
-
Revizuirea (PR review) IA nu este opțională. Când autorul uman nu a recitit, relectura IA nu e un moft — este ochiul delegat.
Vibe coding-ul făcut bine înseamnă și să accepți că nu citești codul și să delegi lectura critică altor IAs care chiar o fac.
Ce dezvăluie acest proiect
Această v1.9 ilustrează mai multe aspecte ale modului meu de a lucra:
- Rolul uman acoperă toată lanțul, cu excepția codului : produs (să mă gândesc la features, să prioritizez), QA (să testez pe cazuri reale, să validez vizual), tech lead (să contest planurile cu un LLM în reasoning extra-high), client final (să judec după utilizarea reală). Singura pălărie pe care nu o port este codarea.
- Să dublezi plasele de siguranță, nu să le elimini : mai puțină recenzie umană = mai multă validare instrumentată. Compromis asumat, nu lipsă de rigoare. Dacă elimin recitirea, trebuie să dublez plasele de siguranță, nu să mă bazez orbește pe IA.
- IA pentru a descoperi bug-urile IA-ului : eșecul silențios a fost găsit de Claude în timpul testelor practice multi-repo. Delegare completă: poți delega și lectura critică.
- Pair-IA ca multiplicator pentru timpul personal : duc proiectul acesta în serile și weekendurile mele. Fără pair-IA, n-aș merge clar atât de departe și atât de repede. Cu ea, pot menține un proiect open-source la nivel industrial pe lângă celelalte obligații. Asta face posibil vibe coding-ul — nu să înlocuiască dezvoltatorul, ci să-i permită să facă ce n-ar putea singur.
- Să iterezi mai degrabă decât să refaci totul : 9 versiuni, refactoring incremental (1 funcție → 7 helpers), retrocompatibilitate păstrată. Pair-IA ajută la iterare rapidă fără să rescrii totul.
Resurse
- AI-Powered Markdown Translator pe GitHub
- Lansarea v1.9
- PR #2 — 75 de commit-uri, migrare + calitate
- CHANGELOG complet
- Pagina proiectului pe acest blog
- Articolul din 2024 — v1.5 (în stilul notelor de lansare) — pentru a compara tonul
- Analiză aprofundată AWS Diagram — alt articol din serie
Dacă vreți să testați AI-Powered Markdown Translator pe propriile voastre Markdown-uri — README-uri open-source, articole de blog, documentație tehnică —, codul este pe GitHub. Instalare în câteva minute, 4 provideri suportați, mod --eco pentru a reduce costul, mod --news pentru a păstra citatele-sursă și, de acum, o stack de calitate v1.9 pe care o puteți reutiliza ca template pentru propriile proiecte în pair-IA.
Dacă dezvoltați la feeling (vibe coding) proiectele personale, nu mergeți către soluția cea mai simplă pe partea de calitate. Fiabilitatea este prețul vitezei — asumați-le pe amândouă împreună.