ai-powered-markdown-translatorÖversatt artikel från fr till sv med gpt-5.4-mini.
AI-Powered Markdown Translator är ett open-source-projekt som jag har underhållit sedan 2024: ett Python-skript som översätter vilken Markdown-fil som helst till 14 språk via 4 AI-leverantörer (OpenAI, Mistral AI, Claude, Gemini). Det driver den här bloggen vid varje publicering — varje sida du läser här på ett annat språk än franska har passerat genom det — och nära 1 800 översatta versioner körs i produktion tack vare det.
Den 8 maj 2026 publicerade jag v1.9, som samlar 75 commits och markerar den största uppdateringen sedan v1.5 från 2024. Tre produktnyheter:
- Validering efter översättning (mot tysta misslyckanden)
- Översättningsnotis med flera positioner (överst, nederst eller båda)
- Läget
--newsför att bevara källcitat på engelska
Men den här v1.9 har en särskild detalj som jag vill berätta här: all kod skrevs i pair-IA. Inte en enda rad skrevs för hand. Så utöver de tre nyheterna handlar artikeln också om ”hur”: vilka skyddsräcken man sätter upp för att sikta på ren och säker kod när man inte själv läser igenom det AI:n producerar?
Kontexten: ett projekt som används varje dag, men som knappt underhållits i kodbasen
Från september 2024 till maj 2026: kontinuerlig användning, hackvis underhåll
Jag hade publicerat en artikel som gick igenom källkoden för v1.5 år 2024. På den tiden publicerade jag skriptet direkt i artikeln. I dag har vinkeln ändrats: det som spelar roll är inte längre koden jag skriver, utan arbetsflödet som producerar den.
Mellan v1.5 som släpptes i september 2024 och januari 2026 fortsatte projektet att köras — det översätter varje nytt innehåll i den här bloggen — men den publika koden rörde sig nästan inte alls. Bara en commit lades till under 2025. Under hela den tiden utvecklade jag koden lokalt för mina privata behov — framför allt modellerna, som jag bytte ut i takt med att nya versioner kom — men dessa förändringar stannade på min maskin. Den publika versionen på GitLab fortsatte att peka på v1.5:s standardvärden.
I början av 2026 gjorde jag en första uppgraderingsinsats: tre releaser på två månader (v1.6 och v1.7 på två dagar i början av januari, v1.8 i mars) som uppdaterade projektet på funktionssidan — 2026-modeller, Gemini-stöd, läget --eco, en enda fil (--news) för källcitaten. Men fortfarande utan CI, utan automatiserade tester, utan kvalitetsgrindar — vilket var ett verkligt problem för mig om jag ville gå längre med en AI-agent som kodar åt mig.
Tempot i ett projekt på fritiden
Varför denna förskjutning? För att jag bär det här projektet på min fritid. Jag har en familj, ett liv utanför skärmen, så utvecklingen går bara framåt i ryck när jag hittar kvällarna och helgerna. Jag brinner för det, jag lägger ändå ganska mycket tid på de här ämnena — jag testar mycket, jag vägleder agenterna, jag validerar resultaten — men tempot är inte som i ett professionellt projekt.
Pair-IA förändrar just det. Det låter mig avancera mellan två begränsningar — passionen och doseringen av livet utanför skärmen. Utan pair-IA skulle jag helt klart inte gå så långt eller så snabbt. Med det kan jag underhålla ett open-source-projekt i industriell klass utan att ägna mitt liv åt det.
Det ursprungliga målet: kvalitet + migration GitLab → GitHub
I mitten av april 2026 ville jag äntligen ta tag i det på allvar. Två enkla mål:
- Lägga till ett kvalitetsskikt (statisk analys, tester, CI)
- Migrera repot från GitLab till GitHub
Inte mer. Men med en kodagent i pair-IA skriver man aldrig det som var planerat. PR:n slutade på 75 commits, 9 837 additions, 1 982 suppressions, 58 filer.
| Version | Datum | Huvudsakligt bidrag |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, sedan Mistral, sedan Claude |
| 1.5 | sep. 2024 | Refaktorering av klienter, 2024-modeller (gpt-4o, claude-3.5-sonnet) |
| 1.6 | jan. 2026 | 2026-modeller (gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, läget --eco, en enda fil (--file) |
| 1.7 | jan. 2026 | --keep_filename, .env, bevarad inline-kod |
| 1.8 | mars 2026 | GPT-5.4-modeller som standard, läget --news med platsmarkörer för citat |
| 1.9 | maj 2026 | Validering efter översättning, notis med flera positioner, kvalitetsstack 14 hooks + 229 tester + AI-granskning |
Snöbollseffekten
Varje nytt kvalitetverktyg avslöjade problem. Codacy rapporterade dupliceringar. SonarCloud pekade ut code smells (signaler om kod som kommer att åldras dåligt: för långa funktioner, oanvända parametrar, krångliga strukturer). /pr-review-toolkit avslöjade dolda buggar. Vid varje träff rättade agenten, ibland och förbättrade också angränsande saker.
Omfattningen växte organiskt. Det var precis vad jag ville — modernisera projektet — men mängden arbete bestämdes av verktygen, inte av mig. För ett projekt i vibe coding är det en nyckelpunkt: kvalitetsverktyg styr arbetet lika mycket som de verifierar det.
Nyhet 1: validering efter översättning (mot tysta misslyckanden)
Incidenten: det var AI:n som hittade buggen under testerna
När jag testade PR:n på README-filer från olika publika repos — ett fall som ingen fixture täckte — upptäckte AI:n det jag hade missat: på vissa språk (särskilt hindi, ISO-kod hi) låg vissa passager kvar på källspråket mitt i översättningen. API:t hade returnerat 200, skriptet hade skrivit filen, men innehållet var bara delvis översatt. Och det passerade genom den befintliga enhetenstestbatteriet — som inte täckte detta verkliga flerlangsscenario.
Det är exakt den typen av bugg som vibe coding kan producera och som ingen ser. Koden verkar logisk, testfixtures täcker inte fallet, människan läser inte igenom resultatet. Men när skriptet testades på verkliga fall (flera repos) gjorde AI:n själv det som fixtures inte gjorde.
Det jag tar med mig av det är detta: praktiska tester över flera repos hittar det som enhetstester missar. Och AI kan också användas för att upptäcka buggar i tidigare AI-agenter — förutsatt att man ställer den inför varierade verkliga fall.
Det var där jag förstod att det behövdes en riktig validering efter översättning. Det här är den första nyheten jag går igenom nu: det dubbla valideringslagret.
Det dubbla valideringslagret
| Steg | Åtgärd | Om fel |
|---|---|---|
| 1️⃣ | API-anrop till leverantören | Nätverksundantag → ❌ fel |
| 2️⃣ | Vitlista per leverantör för finish_reason (eller stop_reason hos Claude) | Utanför vitlistan → ❌ fel |
| 3️⃣ | Anti-läckage: inget källfönster på minst 120 tecken verbatim i utdata | Källfönster hittat → ❌ fel |
| 4️⃣ | langdetect.detect_langs (sannolikhet för källspråk vs målspråk) | Källan > 0,80 OCH målet < 0,20 → ❌ fel |
| 5️⃣ | Skydd mot tomt innehåll + utdata/källkvot (om källan ≥ 500 tecken) | Tomt eller utdata < max(50, source/20) → ❌ fel |
| ✅ | SUCCESS | exit code 0 |
Lager 1 (deterministiskt) — Första skyddsnätet: kontrollera statusen som returneras av API:t. Varje leverantör exponerar ett fält finish_reason (eller stop_reason hos Claude) som anger varför LLM:en slutade generera. Skriptet håller en vitlista per leverantör över godtagbara statusar — nomenklaturen varierar (stop hos OpenAI/Mistral, STOP eller FINISH_REASON_STOP hos Gemini, end_turn eller stop_sequence hos Claude). Koden tolererar också None av säkerhetsskäl, när SDK:t inte returnerar det här fältet. Alla andra statusar — till exempel length, max_tokens eller MAX_TOKENS beroende på leverantör, vilket signalerar ett svar som stoppats av token-gränsen — utlöser ett omedelbart RuntimeError, utan försök till återhämtning.
Det andra deterministiska skyddsnätet är mer subtilt: att kontrollera att ingen del av källtexten förekommer ordagrant i den översatta utdata. I praktiken extraherar man fönster på 120 tecken eller mer ur källtexten; om ett av dem återfinns exakt som det är i utdata, betyder det att det inte har översatts — failure. Det är just den kontrollen som fångade hindi-fallet: LLM:en hade svarat stop (alltså ”naturligt” slut på API-sidan), men franska stycken hade blivit kvar oförändrade i utdata — osynliga för nätet finish_reason, upptäckta av det verbatim anti-läckage-nätet.
Lager 2 (probabilistiskt) — langdetect.detect_langs analyserar språk i utdata och returnerar en sannolikhetsfördelning över flera kandidatspråk. Vi extraherar sannolikheten för källspråket och för målspråket, och avvisar sedan endast om sannolikheten för källspråket överstiger 0,80 och sannolikheten för målspråket faller under 0,20 — en medvetet konservativ tröskel för att undvika falska positiva på teknisk code-switching (legitima engelska ord i en fransk översättning, till exempel). Det här lagret kortsluts för språk med icke-latinska skriftsystem (hindi hi, arabiska ar, kinesiska zh, japanska ja, koreanska ko) där en tillräckligt stark skriftsignal redan validerar utdata. Och det körs bara om den rensade utdata är minst 100 tecken, för att undvika falska positiva på alltför kort text.
De kvantitativa skydden
Ovanpå de två lagren finns två mer prosaiska men nödvändiga kontroller:
- Skydd mot tomt innehåll: om leverantören returnerar tom utdata medan
finish_reasonärstop, avvisar vi direkt (annars skulle vi skriva en tom fil markerad som success) - Rimlighetskvot: bara om källtexten är minst 500 tecken kontrollerar vi att utdata inte är misstänkt kort (typiskt <
max(50, source/20)). Det är en detektor för osynlig trunkering, inte en generell längdregel
Specifikt för Claude gick max_tokens från 4 096 till 32 768 i v1.9 (ändringen gjordes i koden av Claude efter att jag hade konstaterat symptomet och bett den undersöka). Anledningen som dokumenterats i CHANGELOG: att undvika latent trunkering på segment på 16 k tecken, med extra marginal för språk med icke-latinskt skript (FR → JA, ZH, KO, AR, HI) som förbrukar fler tokens i utdata än ett motsvarande latinskt skript.
Återkoppling via explicit status
Filpipelinen (translate_markdown_file()) returnerar nu en explicit status — success, failure eller skipped. CLI:n aggregerar dessa statusar och avslutar med en icke-noll exit-kod så snart minst en fil har misslyckats — vilket gör felet användbart för ett anropande skript eller för den nya CI som lades till i v1.9. Före v1.9 visades flera fel bara i utskriften eller passerade som om översättningen lyckats: processen kunde avslutas i 0 trots att filen saknades, var ofullständig eller var felaktigt validerad. Statusen skipped blir i sig själv en läsbar signal (”medvetet ignorerad”), skild från success (”översättningen skrevs korrekt”).
📄 Python-utdrag: dubbel validering efter översättning (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejetteNyhet 2: översättningsnotisen med flera positioner
Behovet: en diskret men informativ notis
När AI-Powered Markdown Translator skriver en översättning lägger det till en översättningsnotis som anger vilken modell som användes och datumet. Före v1.9 sattes den här notisen alltid längst ned i filen, i ett ärvt (legacy) format med synliga avgränsare.
Formatet längst ned gav två problem för mina egna användningar. För det första informerades läsaren först allra sist om att innehållet hade översatts av AI — det är bättre att säga det från början, så att förväntningen på innehållet blir rätt. För det andra lyfte notisen längst ned inte fram översättningsprojektet som gör allt detta möjligt: man läser artikeln, och den flerspråkiga strömmens ursprung går obemärkt förbi. Jag ville därför kunna flytta notisen till toppen utan att tappa spårbarheten — utan att bryta befintliga användningssätt. V1.9 lägger till två flaggor som inte bryter något:
--note_position {top,bottom,both}: överst, nederst eller båda--note_format {legacy,marker}: ärvt format eller markörformat (marker format)
Bakåtkompatibla standardvärden: legacy + bottom. Ingen befintlig översättningssträng ändrar standardbeteende — de nya flaggorna aktiveras uttryckligen vid behov.
Markörformatet: ett rent inbäddat GitHub-kort (embed card)
Markörformatet utnyttjar en subtil detalj i GitHub Markdown: oanvända link reference definitions är osynliga i renderingen. Man kan alltså koda metadata (modell, datum, källa) i en kommentar-markör placerad längst upp i filen — osynlig i webbläsaren, men bevarad oförändrad vid rå kopiering.
GitHub genererar dessutom ett inbäddat kort (embed card) när man delar en länk till den översatta filen, och det kortet visar dokumentets titel utan textmässigt brus.
Rått Markdown-exempel med markörformat i position top:
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...Vid en snabb blick ser läsaren bara titeln följd av innehållet. Markören stör varken HTML-renderingen eller embed-kortet.
Den medvetna insättningen av frontmatter (frontmatter-aware)
Teknisk men avgörande detalj: att infoga en notis i top betyder inte « att infoga på rad 1 i filen ». Om filen har ett YAML-frontmatter (vilket är fallet för den här bloggen), måste man infoga efter frontmatter — annars förstör notisen YAML:en.
Jag gav behovet till Claude (« infoga notisen efter frontmatter, inte före — annars förstör du YAML:en »), och han tog fram en _split_frontmatter-hjälpare som detekterar öppna/stängda ----fences. Om filen har en oavslutad YAML-fence (felaktigt format) kastar hjälpfunktionen en RuntimeError i stället för att tyst producera en trasig fil. Övergången från en monolitisk funktion till 7 rena hjälpfunktioner (separerade och testbara) är typisk för vad en väl guidad pair-IA snabbt kan göra. Min roll här: kravställare, testare, slutkund som validerar resultatet. Inte kodare. I det här projektet bär jag flera hattar — utom den att skriva koden, som tillhör Claude.
| Position | Format | Typiskt användningsfall |
|---|---|---|
top | marker | Bloggartiklar (diskret notis, snyggt embed-kort) |
top | legacy | Intern dokumentation där synlig spårbarhet är viktig |
bottom | marker | README för öppen källkod (i linje med sidfoten) |
bottom | legacy | Standardvärden — bakåtkompatibla |
both | marker | Långa artiklar där top + bottom känns tryggt |
both | legacy | Legacy-fall med krav på dubbel spårbarhet |
📄 Python-utdrag: hjälpfunktionen _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")Nyhet 3: läget --news för att bevara engelska källcitat
Problemet: att översätta utan att förstöra citaten
När jag skriver ia-actualites-artiklar för den här bloggen (dagliga/veckovisa AI-nyheter från flera källor) citerar jag regelbundet tweets, blogginlägg och versionsannonser på engelska — ofta flera per artikel. Om översättningen rör citaten blir de felaktiga.
Ett översatt citat är ett förvanskat citat. I alla språkversioner (EN, DE, JA, etc.) vill man bevara citaten i originalengelska — det är ett krav på källtrogenhet — tillsammans med mål-språkets flagga och en kursiv översättning för läsbekvämligheten.
Lösningen: placeholders <NEWSQUOTE id="N"/>
| Steg | Åtgärd |
|---|---|
| 1️⃣ | FR-käll-Markdown med EN-citat som indata |
| 2️⃣ | Förbearbetning: extrahering av EN-citat, ersättning med placeholders <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/>, etc. |
| 3️⃣ | API-översättning (FR → target_lang) — de ursprungliga EN-citaten skickas aldrig till LLM, bara placeholders gör det (bevarade som de är) |
| 4️⃣ | Efterbearbetning: återställning av placeholders med de ursprungliga EN-citaten intakta + insättning av mål-språkets flagga |
| 5️⃣ | Post-translation-validering: har alla placeholders återställts? |
| ✅ | Målutdata med bevarade EN-citat |
| ❌ | Fel om en placeholder inte återställts eller ett citat förvanskats |
Läget --news bygger på denna princip: en förbehandling extraherar alla EN-citat, ersätter dem med placeholder-typer som <NEWSQUOTE id="0"/>, översätter resten och återställer placeholders intakta.
Mappningen LANG_FLAGS anpassar flaggan efter target_lang (15 språk täckta): 🇬🇧 för engelska, 🇩🇪 för tyska, 🇪🇸 för spanska, 🇮🇹 för italienska, 🇵🇹 för portugisiska, 🇳🇱 för nederländska, 🇵🇱 för polska, 🇸🇪 för svenska, 🇷🇴 för rumänska, 🇸🇦 för arabiska, 🇮🇳 för hindi, 🇯🇵 för japanska, 🇰🇷 för koreanska, 🇨🇳 för kinesiska, 🇫🇷 för franska.
Efteröversättningsvalideringen kontrollerar att alla placeholders har återställts intakta. Felet är inte en « EN-läcka » — EN är avsiktligt — utan en placeholder som inte återställts eller ett citat som förvanskats.
Nuvarande användningsfall och perspektiv
I dag använder jag --news uteslutande på bloggens ia-actualites-artiklar. På sikt kan det utvidgas till vilken artikel som helst som blandar fransk prosa och EN-källcitat — intervjuer, erfarenhetsåterkopplingar som citerar engelska forskningsartiklar, transkriptioner av konferenspresentationer.
Utan att läsa om koden: varför man måste dubbla skyddsräckena
« Jag läser inte koden. »
Jag läser inte om något. Ibland tittar jag snabbt på en diff — det är sällsynt, och det händer bara när Claude inte klarar ett visst moment själv. Här är flödet jag använder dagligen och som gav v1.9: Claude Code (endast Opus) skriver koden. Codex tar över när Opus fastnar eller när användningsfönstret är mättat. GPT-5.5 i reasoning extra-high utmanar planerna före exekvering. /pr-review-toolkit:review-pr läser igenom PR:n före varje merge. Min roll stannar vid att validera riktningar och definiera skyddsräckena.
Det här utvecklingssättet — renodlad utveckling på känsla (vibe coding) — är inte en brist på noggrannhet. Det är en uttrycklig kompromiss: mindre mänsklig granskning, mer verktygsstödd validering. De 3 v1.9-nyheterna jag just presenterade har alla producerats i detta flöde. Och just för att man inte läser om koden måste man dubbla de tekniska skyddsräckena — inte ta bort dem.
Här är de två skyddsräckena som satts på plats för att göra detta utvecklingssätt hållbart i produktion: en automatiserad kvalitetsstack (Skyddsräcke 1) och en AI-assisterad granskning i ett multimodellflöde (Skyddsräcke 2).
Skyddsräcke 1: den automatiserade kvalitetsstacken (14 hooks + praktiska tester)
Översikt
| Nät | Verktyg | Typisk kostnad | Blockerar vid fel |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks (8 sub-hooks), detect-secrets, Lizard CCN | < 10 s | Ja |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest (229) | ~ 30 s | Ja, förutom pip-audit i initialt rapporteringsläge |
| extern CI | SonarCloud, Codacy, CodeFactor | parallellt | Inte blockerande lokalt, PR-badges |
v1.9-siffror: 14 hooks, 229 unittest-tester stdlib, ~98 % täckning på den nya v1.9-koden, 11 SonarCloud-badges, 3 externa plattformar.
Pre-commit: det snabba nätet
| # | Verktyg | Version | Roll |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | Shell-lint |
| 2 | ruff (lint) | 0.8.6 | Python-lint |
| 3 | ruff (format) | 0.8.6 | Python-formatering |
| 4 | prettier | 3.1.0 | Markdown / JSON / YAML-formatering |
| 5 | trailing-whitespace | 5.0.0 | Tar bort whitespace i slutet av raden |
| 6 | end-of-file-fixer | 5.0.0 | Obligatorisk slutrad (newline) |
| 7 | check-yaml | 5.0.0 | Validering av YAML-syntax |
| 8 | check-toml | 5.0.0 | Validering av TOML-syntax |
| 9 | check-added-large-files | 5.0.0 | Stoppar stora binärer som råkat läggas till |
| 10 | check-merge-conflict | 5.0.0 | Detektering av Git-konfliktmarkörer |
| 11 | check-executables-have-shebangs | 5.0.0 | Kontrollerar att körbara filer har shebang |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | Kontrollerar att shebang-skript är körbara |
| 13 | detect-secrets | 1.5.0 | Detektering av API-nycklar och hemligheter |
| 14 | check-complexity (Lizard) | local | Taksättning för cyklomatisk komplexitet på ny kod |
Total uppmätt tid: cirka 2 till 3 sekunder för hela repot (varmt, pre-commit run --all-files tidsmätt till ~2,4 s). På en genomsnittlig commit som bara rör några filer går det ännu snabbare. Tumregeln jag tillämpar: över 10 s börjar utvecklarna kringgå det (även pair-IA) — därför måste detta snabba nät hållas uppe hela tiden.
Pre-push: det tunga nätet
- mypy i lax läge: ingen total strictness (den historiska koden i translate.py skulle inte gå igenom), men en framstegskontroll på den nya koden
- Opengrep SAST:
p/security-audit p/default p/python— cirka 30 sekunder för att skanna injectioner, eval, osäker deserialisering - pip-audit omslutet av
scripts/check-pip-audit.sh: fångar JSON-utdata, klassificerar transportfel på shell-sidan (nätverk, PyPI nere) för att inte blanda ihop sårbarhet och otillgänglighet, och rapporterar sårbarheterna. I initialt rapporteringsläge för v1.9 (warn + exit 0) — att skärpas till blockering efter en PR med bump av föråldrade beroenden. - unittest-discovery:
python -m unittest discoverpåtests/och sedanscripts/tests/— 229 tester, cirka 8 sekunder lokalt
Extern CI: SonarCloud + Codacy + CodeFactor
Arbetsflödet .github/workflows/sonarcloud.yml (projektnyckel jls42_ai-powered-markdown-translator) körs på varje PR. 11 SonarCloud-badges visas i README: Quality Gate, Security/Reliability/Maintainability Rating, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC.
Varför redundansen Codacy + SonarCloud + CodeFactor? För att var och en ser olika saker. Codacy rapporterade dubbletter som SonarCloud inte hade flaggat. SonarCloud rapporterade signaler om låg kvalitet (de berömda code smells) som Codacy släppte igenom. CodeFactor rapporterade komplexitetsproblem som de två andra missade. Ingen av dem hade räckt ensam. Den marginella kostnaden för en extra plattform är noll (gratis badge, 5 minuters integration), så man multiplicerar vinklarna.
Tester: unittest stdlib (inte pytest)
229 tester, 0 regression under PR:ns 6 månader, ~98 % täckning på den nya v1.9-koden.
Typisk detalj:
test_silent_failure.py: 97 tester som riktar in sig på dubbelvalideringentest_orchestration.py: 79 tester på orkestrator-pipelinentest_translation_note_position.py: 38 tester på matrisen position × formattest_audit_verdict.py: 15 tester på pip-audit-wrappen (iscripts/tests/)
Ärlig notis: täckningen ~98 % gäller den nya v1.9-koden — inte hela den historiska translate.py, som fortfarande innehåller några ärvda funktioner med begränsad täckning i den nya testsviten. Jag nämner det uttryckligen eftersom att ange « 98 % täckning » för ett helt projekt skulle vara vilseledande.
Diskutabelt men medvetet val: testköraren unittest (stdlib), inte pytest. Prefixet test_ är av vana, men det är unittest som kör. Varför? I ett vibe coding-projekt är varje extra beroende = varje beroende som AI:n kan använda fel. Enkelhet är ett mål. unittest finns i Pythons standardbibliotek, ingen installation, inga plugins.
Praktiska tester: multi-repo + intern användning av produkten (dogfooding) + verifiering av visuell rendering
De 229 unittest-testerna räcker inte. Jag lägger till tre lager av praktiska tester:
1. Multi-repo — testa skriptet på flera publika repos med README-filer i olika format. Det avslöjar hörnfall som fixtures inte täcker — en README med 8 rubriknivåer, en annan med ärvda shortcodes, en tredje med exotisk inbäddad kod. Det var i den här fasen som silent-failure-incidenten i Nyhet 1 upptäcktes.
2. Dogfooding på bloggen — jls42.org översätts av själva skriptet. Varje publicerad artikel är ett live-test i produktion. Om ett hörnfall slinker igenom enhetstesterna kommer det ut här, på sidan du läser. Det är det ultimata testet — det som ligger online är det som projektet har producerat.
3. Test av den visuella renderingen — jag kontrollerar att de renderade översättningarna visas korrekt, antingen i webbläsaren (den slutliga webbsidan) eller direkt i VSCode via ett förhandsgranskningsplugin för Markdown. Idén: nöja sig inte med ett syntaktiskt giltigt Markdown, utan se den faktiska renderingen. Visuella renderingar fångar upp utseendebuggar (trasiga tabeller, felaktiga code blocks, felaktigt tolkat frontmatter) som texttester inte ser.
IAs deltar också i dessa tester. /pr-review-toolkit kör koden i testmiljö, och pair-IA-användningen inkluderar systematiskt visuella valideringspass (« kontrollera att den tyska översättningen av sida X visas korrekt »).
📄 Utdrag ur Python: hjälpfunktionen _split_frontmatter (translate.py)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 Utdrag ur .pre-commit-config.yaml (huvudsakliga pre-commit-hooks)
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 Utdrag ur scripts/check-security-sast.sh
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}Skyddsräcke 2: AI-assisterad granskning + multimodellflödet
Terminologisk precision : när jag talar om Claude Opus i det här avsnittet talar jag om modellen jag använder för att utveckla v1.9 — inte om den modell som AI-Powered Markdown Translator använder för att översätta. Själva projektet stöder 4 providers (OpenAI, Mistral AI, Claude, Gemini) och vilken modell som helst (Sonnet, Haiku, Mistral Large, Gemini 3 Pro, etc.). På utvecklingssidan låser jag mig till Opus. Vid körning förblir projektet agnostiskt.
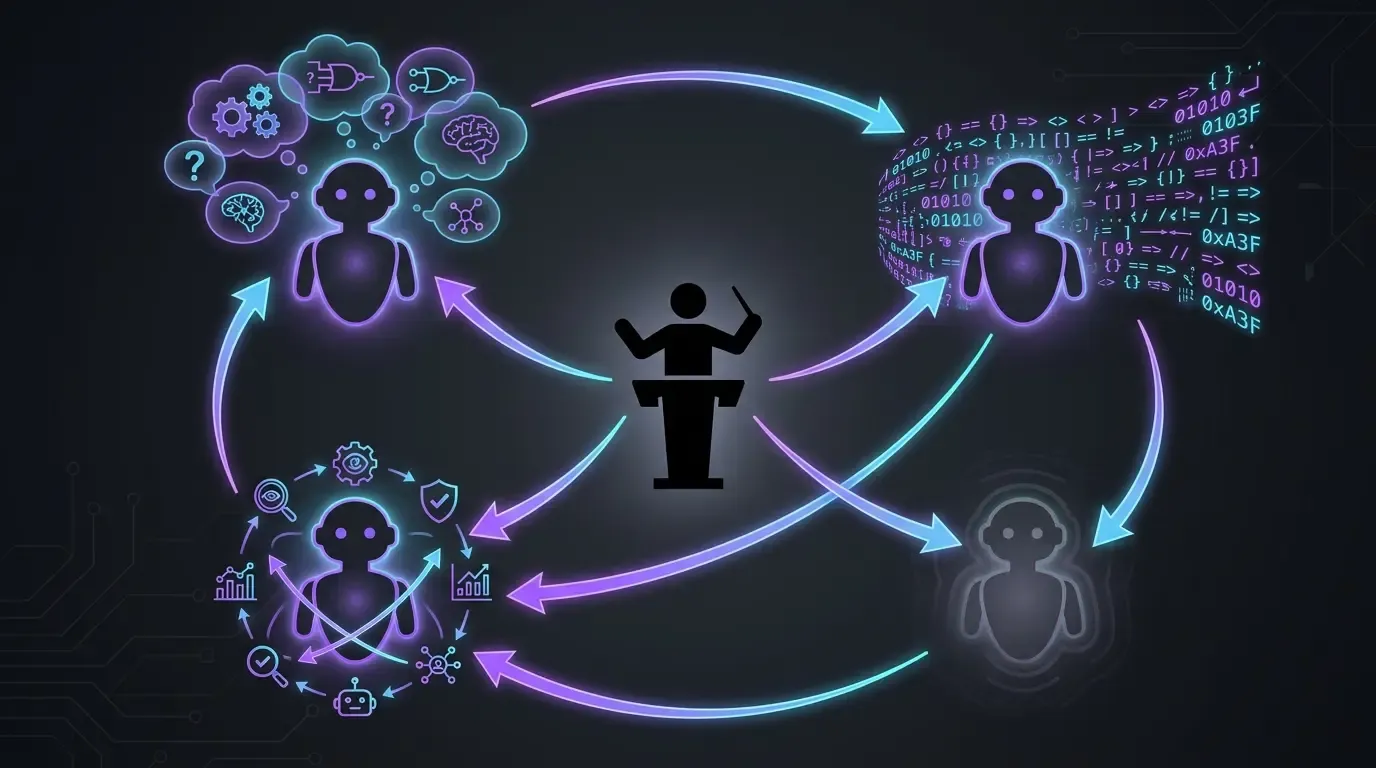
Det verkliga arbetsflödet: 4 modeller, 4 roller (för utveckling)
- Claude Code i Opus, uteslutande (anthropic) : huvudsaklig exekvering. Läser kontexten, skriver koden, tillämpar korrigeringarna. Ingen Sonnet, ingen Haiku, inget fast mode. I det här projektet vill jag ha toppmodellen varje gång — idén är enkel: vi ser till att ha det bästa för att sikta på bästa möjliga resultat.
- OpenAI Codex som reservlösning (fallback) : används i två specifika fall :
- När Opus kör fast på ett ämne (sällsynt men förekommer — till exempel vid korrigeringar som begärs av externa agenter som Codacy eller SonarCloud, konvergerar Claude ibland inte och då flyttar jag ämnet till Codex för att låsa upp det)
- När Anthropics användningskvot är mättad. Codex gör att man inte tappar momentum medan man väntar på kvotåterställning.
- GPT-5.5 reasoning extra-high (
xhigh) : utmanar planer före exekvering. Innan jag låter Claude Code angripa ett ämne skickar jag planen till GPT-5.5 i reasoning extra-high. Den ställer rätt frågor, lyfter fram blinda fläckar. Det gör att man slipper ge sig in i en dålig riktning som måste rättas upp senare. /pr-review-toolkit:review-pr(skill plugin Claude Code) : granskning före merge med specialiserade agenter (säkerhet, kvalitet, tester, kommentarer, typdesign). Skills körs på PR:n innan jag mergar — det är den sista AI-säkerhetslinjen innan koden går in imain.
Ingen av dessa modeller räcker ensam. Var och en har en annan roll — toppklassig exekverare, kapacitetsersättare, planutmanare, flerperspektivgranskare (reviewer).
/pr-review-toolkit : det jag inte hade sett
Allt. Jag tittar inte på koden. Skillet lyfter allt — dolda buggar, säkerhetsproblem, inkonsekvenser i testerna, tester som går igenom men inte testar någonting.
På PR #2 (75 commits, 9 837 additions, 1 982 suppressions, 58 filer) hade en ensam människa hoppat över 80 % av PR:n av trötthet. Skillet hoppar inte över någonting. Det läser varje diff, varje test, varje kommentar. Och framför allt utmanar det — det avvisar mönster som det identifierar som dåliga och föreslår alternativ.
Människan som dirigent, inte som musiker
Min roll täcker hela kedjan — utom kodskrivandet. Jag bär hattarna som produktchef (tänka kring features, prioritera, göra avvägningar), QA (testa på verkliga fall, visuellt validera resultatet), tech lead (utmana planerna med GPT-5.5 reasoning extra-high), slutanvändare (bedöma resultatet utifrån min egen dagliga användarupplevelse på bloggen). Den enda hatt jag inte bär är den som kodare. Resten är jag.
Jag har blivit producent, inte musiker.
Till bloggens tjänst: den översätter sig själv (nära 1 800 översättningar)
AI-Powered Markdown Translator genererar sin egen README på 14 språk, och det är den som producerar alla utländska versioner av innehållet på jls42.org. I praktiken: nära 1 800 översatta versioner matar bloggen (25 artiklar + 4 projekt + 98 AI-nyheter × 14 språk, exklusive FR-källor — alltså 1 778 versioner när jag skriver detta). Varje sida du bläddrar igenom här på ett annat språk än franska har passerat genom det här projektet.
Det är intern produktanvändning (dogfooding) driven till extremen — och det stresstestar översättningen på artikeln som handlar om översättning. Om det du läser på ar, hi eller ko är konsekvent, då håller skyddsnätet i Nyhet 1 (validering efter översättning); om översättningsnoteringen visas korrekt högst upp, då fungerar Nyhet 2 (notering på flera positioner); om EN-citat bevaras i språkversionerna, då fungerar också Nyhet 3 (läget --news).
Slutsats: rigorös AI-pargranskning, inte slarvig AI-pargranskning
Utveckling på känsla har dåligt rykte av goda skäl. Det är just mot dem jag arbetar. Fyra konkreta lärdomar sticker ut från den här v1.9:
-
Tysta fel är fiende nummer ett. AI producerar kod som verkar okej och passerar igenom enhetstesterna. Alltid klientsidig validering. Och att använda en annan AI för att granska den faktiska produktionen, inte bara koden.
-
Hooks pre-commit < 10 s annars kringgås de ; pre-push kan ta 30 s+. AI lägger gärna till verktyg utan att ta hänsyn till kostnaden. Det måste ramas in manuellt, antingen i planen eller i efterhand — det viktiga är att hooks till slut är rätt inställda och faktiskt används i vardagen.
-
Täckning utan starka assertioner = teater. AI kan generera 200 tester som går igenom och inte testar någonting. unittest + precisa assertioner > pytest med hur många mocks som helst. Verifiera returvärdet, inte bara att koden inte kraschade.
-
AI-granskning (PR review) är inget valfritt tillval. När den mänskliga författaren inte har läst igenom, då är AI-granskaren inte en gimmick — det är den delegerade blicken.
Vibe coding som görs rätt handlar också om att acceptera att man inte läser koden och att delegera den kritiska läsningen till andra IAs som faktiskt gör det.
Vad det här projektet avslöjar
Den här v1.9 illustrerar flera aspekter av mitt sätt att arbeta:
- Den mänskliga rollen täcker hela kedjan utom koden : produkt (tänka kring features, prioritera), QA (testa på verkliga fall, visuellt validera), tech lead (utmana planerna med en LLM i reasoning extra-high), slutanvändare (bedöma utifrån verklig användning). Den enda hatt jag inte bär är att koda.
- Förstärk skyddsnäten, ta inte bort dem : mindre mänsklig granskning = mer verktygsstödd validering. Ett medvetet avvägande, inte brist på noggrannhet. Om jag tar bort granskningen måste jag dubbla skyddsnäten, inte blindt lita på AI:n.
- AI för att upptäcka AI-buggar : det tysta felet hittades av Claude under praktiska tester över flera repos. Full delegering: man kan också delegera den kritiska granskningen.
- AI-pararbete som multiplikator på fritiden : jag driver det här projektet på kvällar och helger. Utan AI-pararbete hade jag tydligt inte kommit lika långt eller lika snabbt. Med det kan jag hålla ett open source-projekt på industrinivå vid sidan av mina andra åtaganden. Det är detta vibe coding gör möjligt — inte att ersätta utvecklaren, utan att låta honom göra det han inte skulle kunna göra ensam.
- Iterera i stället för att göra om allt : 9 versioner, inkrementell refaktorering (1 funktion → 7 hjälpfunktioner), bevarad bakåtkompatibilitet. AI-pararbete hjälper till att iterera snabbt utan att skriva om allt.
Resurser
- AI-Powered Markdown Translator på GitHub
- Utgåva v1.9
- PR #2 — 75 commits, migrering + kvalitet
- Fullständig CHANGELOG
- Projektsidan på denna blogg
- Artikel 2024 — v1.5 (release notes-stil) — för att jämföra tonen
- Djupdykning i AWS Diagram — annan artikel i serien
Om du vill testa AI-Powered Markdown Translator på dina egna Markdown-filer — README för open source, bloggartiklar, teknisk dokumentation —, finns koden på GitHub. Installation på några minuter, 4 stödda leverantörer, läget --eco för att sänka kostnaden, läget --news för att bevara källcitaten, och nu dessutom en kvalitetstack v1.9 som du kan återanvända som mall för dina egna projekt i AI-pararbete.
Om du utvecklar dina personliga projekt på känsla (vibe coding), gå inte till det enklaste på kvalitetssidan. Tillförlitlighet är priset för snabbhet — stå för båda samtidigt.