ai-powered-markdown-translatorgpt-5.4-mini로 fr에서 ko로 번역된 기사.
AI-Powered Markdown Translator는 제가 2024년부터 유지해 온 오픈소스 프로젝트입니다. 이 Python 스크립트는 OpenAI, Mistral AI, Claude, Gemini라는 4개의 AI 제공자를 통해 어떤 Markdown 파일이든 14개 언어로 번역합니다. 이 블로그는 새 글을 올릴 때마다 이 스크립트를 사용합니다. 여기서 프랑스어가 아닌 언어로 읽고 있는 모든 페이지는 이 도구를 거쳤고, 현재는 약 1,800개의 번역본이 이 도구 덕분에 운영 환경에서 돌아가고 있습니다.
2026년 5월 8일, 저는 v1.9를 공개했습니다. 이번 릴리스에는 75개 커밋이 담겨 있으며, 2024년의 v1.5 이후 가장 큰 업데이트입니다. 제품 측면의 새 기능은 3가지입니다.
- 번역 후 검증(조용한 실패 방지)
- 다중 위치 번역 노트(상단, 하단 또는 둘 다)
- 원문 EN 인용을 보존하는
--news모드
하지만 이 v1.9에는 여기서 꼭 이야기하고 싶은 특징이 하나 있습니다. 코드 전체를 AI 페어로 작성했다는 점입니다. 손으로 직접 타이핑한 줄은 한 줄도 없습니다. 그래서 3가지 새 기능 외에도, 이 글은 “어떻게”에 대한 이야기이기도 합니다. 즉, AI가 대신 코드를 만들어 줄 때 우리가 직접 그 결과를 다시 읽지 않더라도 깨끗하고 안전한 코드를 목표로 하려면 어떤 안전장치를 두어야 하는가 하는 문제입니다.
맥락: 매일 쓰이지만 코드 측면에서는 거의 유지보수되지 않은 프로젝트
2024년 9월부터 2026년 5월까지: 지속적 사용, 간헐적 유지보수
저는 2024년 v1.5의 소스 코드를 자세히 다룬 글을 이미 올린 적이 있습니다. 그때는 스크립트를 글 안에 직접 실었습니다. 지금은 관점이 달라졌습니다. 중요한 것은 제가 어떤 코드를 쓰는가보다, 그 코드를 만들어 내는 작업 흐름입니다.
2024년 9월에 공개된 v1.5와 2026년 1월 사이에, 프로젝트는 계속 돌아갔습니다. 이 블로그의 새 콘텐츠를 번역하는 일도 계속했지만, 공개된 코드는 거의 움직이지 않았습니다. 2025년에는 커밋이 단 1개만 올라갔습니다. 그동안 저는 개인 용도에 맞게 로컬에서 코드를 발전시켰습니다. 특히 모델을 계속 바꿔 써 왔습니다. 새 모델이 나올 때마다 교체했고, 이런 변화는 제 머신에만 남아 있었습니다. GitLab의 공개 버전은 계속 v1.5의 기본값을 가리키고 있었습니다.
2026년 초에는 먼저 한 차례 정비 작업을 했습니다. 두 달 동안 세 번의 릴리스(v1.6과 v1.7은 1월 초 이틀 간격, v1.8은 3월)를 통해 기능을 최신화했습니다. 2026년 모델, Gemini 지원, --eco 모드, 단일 파일, 원문 인용용 --news 모드가 그때 들어갔습니다. 하지만 여전히 CI도 없고, 자동화된 테스트도 없고, 품질 게이트도 없었습니다. AI 에이전트가 내 대신 코드를 짜는 상황에서 더 나아가려면, 이 점이 저에게는 정말 큰 문제였습니다.
개인 시간으로 진행하는 프로젝트의 속도
왜 이렇게 차이가 났을까요? 이 프로젝트를 제 개인 시간으로만 운영했기 때문입니다. 가족도 있고 화면 밖의 삶도 있으니, 발전은 밤과 주말에 시간의 여유가 있을 때만 조금씩 진행됩니다. 저는 이 주제에 열정이 있고, 그래도 꽤 많은 시간을 씁니다. 많이 테스트하고, 에이전트를 안내하고, 결과를 검증합니다. 하지만 속도는 직업적 프로젝트와 같을 수 없습니다.
AI 페어는 바로 그 지점을 바꿔 줍니다. 열정과 화면 밖 삶 사이의 제약을 넘나들며 앞으로 나아가게 해 줍니다. AI 페어가 없었다면 저는 분명 여기까지도, 이렇게 빨리도 가지 못했을 것입니다. AI 페어가 있으면, 제 삶 전체를 갈아 넣지 않고도 오픈소스 프로젝트를 산업 수준으로 유지할 수 있습니다.
초기 목표: 품질 + GitLab → GitHub 마이그레이션
2026년 4월 중순, 저는 마침내 이 프로젝트를 제대로 손보기로 했습니다. 목표는 아주 단순했습니다.
- 품질 계층 추가(정적 분석, 테스트, CI)
- 저장소를 GitLab에서 GitHub로 마이그레이션
그 이상은 없었습니다. 그런데 AI 페어 코드 에이전트를 쓰면, 원래 계획했던 것만 딱 쓰고 끝나는 법이 없습니다. PR은 결국 75개 커밋, 9,837개 추가, 1,982개 삭제, 58개 파일로 끝났습니다.
| 버전 | 날짜 | 주요 내용 |
|---|---|---|
| 1.0–1.4 | 2024 | OpenAI, 그다음 Mistral, 그다음 Claude |
| 1.5 | 2024년 9월 | 클라이언트 리팩터링, 2024 모델(gpt-4o, claude-3.5-sonnet) |
| 1.6 | 2026년 1월 | 2026 모델(gpt-5, claude-sonnet-4-5, gemini-3-pro), Gemini, --eco 모드, 단일 파일 (--file) |
| 1.7 | 2026년 1월 | --keep_filename, .env, 인라인 코드 보존 |
| 1.8 | 2026년 3월 | 기본 GPT-5.4 모델, 인용 placeholder가 있는 --news 모드 |
| 1.9 | 2026년 5월 | 번역 후 검증, 다중 위치 노트, 14개 훅 + 229개 테스트 + AI 리뷰 품질 스택 |
눈덩이 효과
품질 도구를 하나씩 추가할 때마다 문제도 같이 드러났습니다. Codacy는 중복을 지적했습니다. SonarCloud는 code smell을 잡아냈습니다. 이는 오래 가기 어려운 코드의 신호입니다. 함수가 너무 길다든가, 사용되지 않는 매개변수가 있다든가, 구조가 지나치게 꼬여 있다든가 하는 것들입니다. /pr-review-toolkit는 숨어 있던 버그를 짚어 냈습니다. 지적이 들어올 때마다 에이전트가 수정했고, 때로는 인접한 부분까지 함께 개선했습니다.
범위는 유기적으로 커졌습니다. 제가 원하던 바와 정확히 일치했습니다. 프로젝트를 현대화하는 것이 목표였으니까요. 다만 작업량의 분배는 저보다 도구가 더 많이 결정했습니다. 바이브 코딩 프로젝트에서는 이 점이 핵심입니다. 품질 도구는 작업을 검증하는 것만큼이나 작업의 방향도 정합니다.
새 기능 1: 번역 후 검증(조용한 실패 방지)
사건: 테스트 도중 버그를 찾아낸 것은 AI였다
여러 공개 저장소의 README로 PR를 테스트하던 중, 어떤 fixture도 다루지 못한 사례에서 AI가 제가 놓친 문제를 짚었습니다. 일부 언어, 특히 힌디어(ISO 코드 hi)에서는 번역 중간에 원문이 그대로 남아 있었습니다. API는 200를 반환했고, 스크립트는 파일을 썼지만, 내용은 절반만 번역된 상태였습니다. 그런데 기존 단위 테스트 묶음은 이 실제 다국어 사례를 커버하지 못해서 그냥 통과해 버렸습니다.
이것이 바로 바이브 코딩이 만들어 낼 수 있는, 그리고 아무도 알아채지 못하는 버그입니다. 코드는 논리적으로 보이고, 테스트 fixture는 해당 사례를 포함하지 않으며, 사람은 결과를 다시 읽지 않습니다. 그런데 실제 다중 저장소 사례로 스크립트를 돌려 보니, AI 자신이 fixture가 하지 못한 일을 해낸 셈이었습니다.
제가 여기서 얻은 교훈은 분명합니다. 여러 저장소를 대상으로 한 실전 테스트는 단위 테스트가 놓치는 것을 찾아냅니다. 그리고 AI는 이전 AI 에이전트가 만든 버그를 찾아내는 데도 쓸 수 있습니다. 다만 실제로 다양한 사례를 눈앞에 갖다 놓아야 합니다.
그때 저는 진짜 번역 후 검증이 필요하다는 것을 깨달았습니다. 이제 소개할 첫 번째 새 기능이 바로 이 이중 검증 계층입니다.
이중 검증 계층
| 단계 | 동작 | 실패 시 |
|---|---|---|
| 1️⃣ | 프로바이더 API 호출 | 네트워크 예외 → ❌ failure |
| 2️⃣ | finish_reason의 프로바이더별 허용 목록(Claude의 경우 stop_reason) | 허용 목록 밖 → ❌ failure |
| 3️⃣ | 유출 방지: 출력 결과에 원문에서 가져온 120자 이상의 창이 그대로 존재하지 않는지 확인 | 원문 창이 발견됨 → ❌ failure |
| 4️⃣ | langdetect.detect_langs(원문 vs 대상 언어 확률) | 원문 > 0,80 그리고 대상 < 0,20 → ❌ failure |
| 5️⃣ | 빈 콘텐츠 + 출력/원문 비율 검사(원문이 500자 이상일 때) | 비어 있음 또는 출력 < max(50, source/20) → ❌ failure |
| ✅ | SUCCESS | exit code 0 |
계층 1(결정론적) — 첫 번째 안전망은 API가 돌려준 상태를 확인하는 것입니다. 각 제공자는 LLM이 생성을 멈춘 이유를 알려 주는 finish_reason(Claude의 경우 stop_reason) 필드를 노출합니다. 스크립트는 허용 가능한 상태에 대한 제공자별 허용 목록을 유지합니다. 명명 방식은 제공자마다 다릅니다(stop은 OpenAI/Mistral에서, STOP 또는 FINISH_REASON_STOP는 Gemini에서, end_turn 또는 stop_sequence는 Claude에서 사용). SDK가 이 필드를 돌려주지 않는 경우를 대비해 None도 허용합니다. 그 밖의 모든 상태, 예를 들어 제공자에 따라 length, max_tokens 또는 MAX_TOKENS처럼 토큰 한도 때문에 응답이 멈췄음을 뜻하는 값은 즉시 RuntimeError를 발생시키며, 복구 시도는 하지 않습니다.
두 번째 결정론적 안전망은 조금 더 미묘합니다. 원문 텍스트의 어떤 부분도 번역 결과에 그대로 나타나면 안 된다는 점을 확인하는 것입니다. 구체적으로는 원문에서 120자 이상의 창을 뽑아내고, 그 창 중 하나라도 출력 결과에 똑같이 발견되면 번역되지 않은 것이므로 failure입니다. 바로 이 검사가 힌디어 사례를 잡아냈습니다. LLM은 stop를 반환했기 때문에 API 관점에서는 “자연스러운” 종료였지만, 프랑스어 문단이 출력 결과에 그대로 남아 있었습니다. finish_reason 안전망은 이를 못 봤지만, 원문 그대로 유출되는지 확인하는 검사에서 잡아낸 것입니다.
계층 2(확률 기반) — langdetect.detect_langs는 출력 언어를 분석해 여러 후보 언어에 대한 확률 분포를 반환합니다. 여기서 원문 언어와 대상 언어의 확률을 뽑아낸 뒤, 원문 확률이 0,80을 넘고 대상 확률이 0,20 아래로 떨어질 때에만 거부합니다. 기술적인 코드 스위칭에서 오탐을 줄이기 위한 의도적으로 보수적인 기준입니다. 예를 들어 프랑스어 번역 안에 영어 단어가 자연스럽게 섞이는 경우를 문제로 보지 않기 위해서입니다. 이 계층은 힌디어 hi, 아랍어 ar, 중국어 zh, 일본어 ja, 한국어 ko처럼 비라틴 문자 스크립트에서는 이미 충분한 스크립트 신호가 있으면 바로 통과시킵니다. 또한 출력이 정리된 뒤 100자 이상일 때만 실행하여, 너무 짧은 텍스트에서 생길 수 있는 오탐도 막습니다.
정량적 안전장치
이 두 계층 위에는 조금 더 소박하지만 꼭 필요한 두 가지 검사가 있습니다.
- 빈 콘텐츠 가드: 제공자가 빈 출력을 돌려주는데도
finish_reason가stop이면 즉시 거부합니다. 그렇지 않으면 성공으로 표시된 빈 파일을 쓰게 되기 때문입니다. - 안전 비율: 원문이 최소 500자일 때만, 출력이 의심스러울 정도로 짧지 않은지 확인합니다(보통 <
max(50, source/20)). 이것은 보편적인 길이 규칙이 아니라, 눈에 보이지 않는 잘림을 잡아내는 탐지 장치입니다.
Claude의 경우 특히 max_tokens이 v1.9에서 4,096에서 32,768로 바뀌었습니다(이 변경은 제가 증상을 확인하고 조사해 달라고 요청한 뒤 Claude가 코드 측에서 직접 반영했습니다). CHANGELOG에 적힌 이유는 16k 문자 구간에서 발생할 수 있는 잠재적 잘림을 피하고, 비라틴 문자 스크립트(FR → JA, ZH, KO, AR, HI)가 라틴 문자와 같은 길이의 출력보다 더 많은 토큰을 소비하는 점까지 고려하기 위해서입니다.
명시적 상태 반환
파일 파이프라인(translate_markdown_file())은 이제 명시적 상태를 반환합니다. success, failure 또는 skipped입니다. CLI는 이 상태들을 집계하고, 파일 하나라도 실패하면 0이 아닌 종료 코드로 끝냅니다. 덕분에 호출 스크립트나 v1.9에서 새로 추가된 CI가 실패를 바로 활용할 수 있습니다. v1.9 이전에는 몇몇 오류가 단순히 출력되기만 하거나, 성공한 번역처럼 넘어가기도 했습니다. 그 결과 파일이 없거나, 불완전하거나, 제대로 검증되지 않았는데도 프로세스가 0로 끝날 수 있었습니다. skipped 상태는 그 자체로도 읽을 수 있는 신호가 됩니다. “의도적으로 건너뜀”이라는 뜻이며, success(“번역이 올바르게 기록됨”)과 구별됩니다.
📄 Python 예시: 번역 후 이중 검증 (translate.py)
def _check_passthrough_excerpt(segment, stripped, args):
"""Couche 1 : vérifie qu'aucune fenêtre source ≥120 chars (cleaned) n'apparaît
verbatim dans la sortie (bug silent-failure typique : LLM renvoie le source brut)."""
out_norm = re.sub(r"\s+", " ", stripped).casefold()
for window in _extract_source_windows(segment, ignore_blockquotes=args.news):
if _looks_like_proper_noun_list(window):
continue
window_norm = re.sub(r"\s+", " ", window).casefold()
if window_norm in out_norm:
raise RuntimeError(
f"Output contains untranslated source excerpt "
f"(model={args.model}, target={args.target_lang}, "
f"matched window: {window_norm[:100]!r})"
)
def _check_output_language(stripped, args):
"""Couche 2 : langdetect probabiliste sur la langue de sortie. Court-circuite
si target script (HI/AR/ZH/JA/KO) déjà détecté en quantité suffisante (le
code-switching technique fait que langdetect peut sous-estimer la cible).
"""
if _has_target_script_signal(stripped, args.target_lang):
return
langdetect_text = _clean_for_language_detection(stripped)
if len(langdetect_text) < 100:
return
probas = {p.lang: p.prob for p in detect_langs(langdetect_text)}
# ... seuils source/target appliqués pour décider si on rejette새 기능 2: 다중 위치 번역 노트
요구 사항: 눈에 띄지 않지만 유익한 노트
AI-Powered Markdown Translator가 번역을 쓸 때는 사용된 모델과 날짜를 표시하는 번역 노트를 덧붙입니다. v1.9 이전에는 이 노트가 항상 파일 맨 아래에 붙었고, 눈에 보이는 구분자가 들어간 레거시 형식이었습니다.
파일 하단에 붙는 형식은 제 용도에서는 두 가지 문제가 있었습니다. 첫째, 독자는 콘텐츠가 AI에 의해 번역되었다는 사실을 맨 끝에 가서야 알 수 있었습니다. 처음부터 알려 주는 편이 기대치를 잡는 데 더 좋습니다. 둘째, 각주 형태의 노트는 이 모든 것을 가능하게 하는 번역 프로젝트를 충분히 드러내지 못했습니다. 글은 읽히는데, 다국어 흐름의 출처는 눈에 띄지 않았습니다. 그래서 기존 사용 방식을 깨지 않으면서도 추적 가능성은 유지한 채, 노트를 위로 올릴 수 있으면 좋겠다고 생각했습니다. v1.9에는 아무것도 깨지지 않는 두 개의 플래그가 추가됩니다.
--note_position {top,bottom,both}: 상단, 하단 또는 둘 다--note_format {legacy,marker}: 레거시 형식 또는 마커 형식(marker format)
하위 호환 기본값은 legacy + bottom입니다. 기존 번역 문자열의 기본 동작은 아무것도 바뀌지 않습니다. 새 플래그는 필요할 때 명시적으로 켭니다.
마커 형식: 깔끔한 GitHub 임베드 카드
마커 형식은 GitHub Markdown의 미묘한 특징 하나를 활용합니다. 사용되지 않는 링크 참조 정의는 렌더링에서 보이지 않습니다. 따라서 문서의 맨 위에 주석 마커 형태로 메타데이터(모델, 날짜, 출처)를 넣어 두되, 브라우저에서는 보이지 않고 원본을 그대로 복사할 때는 그대로 보존되게 할 수 있습니다.
또한 GitHub는 번역된 파일 링크를 공유할 때 임베드 카드(임베드 카드)를 생성하는데, 이 카드에는 텍스트 노이즈 없이 문서 제목이 잘 표시됩니다.
top 위치의 마커 형식을 사용한 원시 Markdown 예시는 다음과 같습니다.
[//]: # 'translation-marker: model=claude-sonnet-4-5 date=2026-05-08 source=fr target=en'
# Title of the article in target language
Body of the translated content...눈으로 보면 독자는 제목과 본문만 보게 됩니다. 마커는 HTML 렌더링에도, 임베드 카드에도 노이즈를 만들지 않습니다.
프론트매터를 인지하는 삽입 (frontmatter-aware)
기술적으로는 세부 사항이지만 매우 중요합니다: top에 노트를 삽입하는 것이 곧 « 파일의 1번째 줄에 삽입한다 »는 뜻은 아닙니다. 파일에 YAML frontmatter가 있다면(이 블로그가 바로 그런 경우입니다), 노트는 frontmatter 뒤에 삽입해야 합니다. 그렇지 않으면 노트가 YAML을 깨버립니다.
Claude에게 요구사항을 전달했더니(« frontmatter 뒤에 노트를 삽입해, 앞에 두지 마 — 아니면 YAML이 깨져 »), 그는 열기/닫기 --- fence를 감지하는 _split_frontmatter 헬퍼를 내놓았습니다. 파일에 닫히지 않은 YAML fence가 있으면(형식이 잘못된 경우), 이 헬퍼는 조용히 깨진 파일을 만들어 내는 대신 RuntimeError를 던집니다. 단일 덩어리 함수에서 분리 가능하고 테스트 가능한 7개의 순수 헬퍼로 옮겨 가는 것은, 잘 안내된 pair-IA가 빠르게 해낼 수 있는 일의 전형입니다. 여기서 내 역할은 요구사항을 정리하고, 테스트하고, 최종 결과를 검증하는 클라이언트입니다. 코드는 작성하지 않습니다. 이 프로젝트에서 나는 여러 모자를 쓰지만 — 코드를 작성하는 역할만은 제외입니다. 그 역할은 Claude가 맡습니다.
| 위치 | 형식 | 대표 사용 사례 |
|---|---|---|
top | marker | 블로그 글(눈에 띄지 않는 노트, 깔끔한 embed card) |
top | legacy | 가시적 추적성이 중요한 내부 문서 |
bottom | marker | 오픈소스 README(footer와 일관성 유지) |
bottom | legacy | 하위 호환이 필요한 기본값 |
both | marker | 상단 + 하단이 모두 안심을 주는 긴 글 |
both | legacy | 이중 추적성 요구가 있는 레거시 사례 |
📄 Python 발췌: helper _split_frontmatter (translate.py)
def _split_frontmatter(content):
lines = content.splitlines(keepends=True)
if not lines or lines[0].strip() != "---":
return "", content
for index in range(1, len(lines)):
if lines[index].strip() == "---":
frontmatter = "".join(lines[: index + 1]).rstrip("\n")
body = "".join(lines[index + 1 :]).lstrip("\n")
return frontmatter, body
# Opening `---` sans fence de fermeture : insérer la note sans erreur
# produirait un fichier mal formé. On préfère faire échouer le fichier
# (failed_files dans translate_markdown_file) plutôt qu'écrire un output cassé.
raise RuntimeError("malformed frontmatter: opening '---' without closing fence")새 기능 3: EN 출처 인용문을 보존하는 --news 모드
문제: 인용문을 망가뜨리지 않고 번역하기
이 블로그를 위해 ia-actualites 글을 쓸 때(다중 소스 AI 뉴스 일간/주간), 저는 트윗, 블로그 글, 영어 버전 릴리스 공지 등을 자주 인용합니다. 글 하나에 여러 개가 들어가는 경우도 흔합니다. 번역이 인용문에 손을 대면, 그것들은 더 이상 사실이 아니게 됩니다.
번역된 인용문은 변형된 인용문입니다. 모든 언어 버전(EN, DE, JA 등)에서 우리는 인용문의 원래 영어를 그대로 유지하고 싶습니다 — 이는 출처에 대한 충실성의 요구입니다 — 그리고 읽기 편하도록 대상 언어 깃발과 이탤릭체 번역을 함께 붙입니다.
해결책: <NEWSQUOTE id="N"/> placeholder
| 단계 | 작업 |
|---|---|
| 1️⃣ | 인용문 EN이 포함된 FR 소스 Markdown을 입력으로 받음 |
| 2️⃣ | 사전 처리: EN 인용문을 추출하고 <NEWSQUOTE id="0"/>, <NEWSQUOTE id="1"/> 등 placeholder로 치환 |
| 3️⃣ | API 번역(FR → target_lang) — 원래 EN 인용문은 LLM에 절대 보내지지 않으며, placeholder만 전송됨(그대로 보존됨) |
| 4️⃣ | 사후 처리: placeholder를 원래의 EN 인용문이 그대로 유지된 상태로 복원 + 대상 언어 깃발 삽입 |
| 5️⃣ | 번역 후 검증: 모든 placeholder가 복원되었는가? |
| ✅ | EN 인용문이 보존된 대상 출력 |
| ❌ | placeholder가 복원되지 않았거나 인용문이 변형되면 실패 |
--news 모드는 이 원리에 기반합니다. 사전 처리에서 모든 EN 인용문을 추출해 <NEWSQUOTE id="0"/> 같은 placeholder로 바꾸고, 나머지를 번역한 뒤, placeholder를 원상태로 복원합니다.
LANG_FLAGS 매핑은 target_lang에 맞춰 깃발을 조정합니다(15개 언어 지원): 🇬🇧 영어, 🇩🇪 독일어, 🇪🇸 스페인어, 🇮🇹 이탈리아어, 🇵🇹 포르투갈어, 🇳🇱 네덜란드어, 🇵🇱 폴란드어, 🇸🇪 스웨덴어, 🇷🇴 루마니아어, 🇸🇦 아랍어, 🇮🇳 힌디어, 🇯🇵 일본어, 🇰🇷 한국어, 🇨🇳 중국어, 🇫🇷 프랑스어.
사후 번역 검증은 모든 placeholder가 원형 그대로 복원되었는지 확인합니다. 오류는 « EN 누수 »가 아닙니다. EN은 의도된 것입니다. 오류는 복원되지 않은 placeholder 또는 변형된 인용문입니다.
현재 사용 사례와 전망
현재 저는 --news를 블로그의 ia-actualites 글에만 사용합니다. 장기적으로는 프랑스어 prose와 EN 출처 인용문이 섞인 어떤 글이든 확장될 수 있습니다 — 인터뷰, 영어 논문을 인용한 경험 공유, 컨퍼런스 발표 전사본 등.
코드를 다시 읽지 않고도: 왜 안전장치를 두 겹으로 해야 하는가
« 나는 코드를 읽지 않는다. »
저는 아무것도 재검토하지 않습니다. 가끔 diff를 빠르게 훑어보긴 합니다 — 드물게만, 그리고 그건 Claude가 어떤 지점에서 혼자 해결하지 못할 때뿐입니다. 제가 매일 사용하는 흐름이자 v1.9를 만들어 낸 흐름은 다음과 같습니다. Claude Code(오직 Opus만 사용)가 코드를 작성합니다. Opus가 막히거나 사용 가능한 창이 가득 차면 Codex가 이어받습니다. GPT-5.5 reasoning extra-high는 실행 전에 계획을 검토합니다. /pr-review-toolkit:review-pr는 매 merge 전에 PR을 다시 읽습니다. 제 역할은 방향을 확인하고 안전장치를 정의하는 데서 끝납니다.
이런 개발 방식 — 전면적인 vibe coding — 은 엄격함의 부족이 아닙니다. 이것은 명시적인 절충입니다: 사람의 재검토는 줄이고, 도구 기반 검증은 늘립니다. 방금 소개한 v1.9의 3개 신규 기능은 모두 이 흐름에서 만들어졌습니다. 그리고 바로 코드 재검토를 하지 않기 때문에 기술적 안전장치를 두 겹으로 해야 합니다 — 없애는 것이 아니라.
프로덕션에서 이 개발 모드를 성립시키기 위해 마련한 두 가지 안전장치는 다음과 같습니다: 자동화된 품질 스택(안전장치 1)과 멀티모델 흐름의 AI 보조 리뷰(안전장치 2).
안전장치 1: 자동화된 품질 스택(14개 hook + 실전 테스트)
개요
| 가드레일 | 도구 | 일반적 비용 | 실패 시 차단 여부 |
|---|---|---|---|
| pre-commit | shellcheck, ruff, prettier, pre-commit-hooks(8개의 sub-hook), detect-secrets, Lizard CCN | < 10초 | 예 |
| pre-push | mypy, Opengrep SAST, pip-audit + audit_verdict, unittest(229) | ~ 30초 | 예, 단 pip-audit는 초기 reporting만 차단 아님 |
| 외부 CI | SonarCloud, Codacy, CodeFactor | 병렬 실행 | 로컬에서는 차단하지 않음, PR 배지 |
v1.9 수치: 14개 hook, stdlib unittest 테스트 229개, 새로운 v1.9 코드에 약 98% 커버리지, SonarCloud 배지 11개, 외부 플랫폼 3개.
Pre-commit: 빠른 가드레일
| # | 도구 | 버전 | 역할 |
|---|---|---|---|
| 1 | shellcheck-py | 0.10.0.1 | shell lint |
| 2 | ruff (lint) | 0.8.6 | Python lint |
| 3 | ruff (format) | 0.8.6 | Python 포맷팅 |
| 4 | prettier | 3.1.0 | Markdown / JSON / YAML 포맷팅 |
| 5 | trailing-whitespace | 5.0.0 | 줄 끝 공백 제거 |
| 6 | end-of-file-fixer | 5.0.0 | 파일 끝 newline 강제 |
| 7 | check-yaml | 5.0.0 | YAML 구문 검증 |
| 8 | check-toml | 5.0.0 | TOML 구문 검증 |
| 9 | check-added-large-files | 5.0.0 | 실수로 추가된 대용량 바이너리 차단 |
| 10 | check-merge-conflict | 5.0.0 | Git 충돌 마커 감지 |
| 11 | check-executables-have-shebangs | 5.0.0 | 실행 파일에 shebang이 있는지 확인 |
| 12 | check-shebang-scripts-are-executable | 5.0.0 | shebang이 있는 스크립트가 실행 가능한지 확인 |
| 13 | detect-secrets | 1.5.0 | API 키와 비밀값 탐지 |
| 14 | check-complexity (Lizard) | local | 새 코드에 대한 순환 복잡도 상한 |
측정된 총합: repo 전체에서 약 2~3초(워밍업 상태, pre-commit run --all-files 기준 약 2.4초). 몇 개 파일만 건드리는 일반적인 커밋은 더 빠릅니다. 제가 적용하는 경험칙은 이렇습니다: 10초를 넘기면 개발자들은 우회합니다(pair-IA도 마찬가지입니다). 따라서 이 빠른 가드레일은 항상 유지해야 합니다.
Pre-push: 무거운 가드레일
- mypy를 느슨한 모드로 사용: 전체 strict는 아님(translate.py의 역사적인 코드는 통과하지 못함), 대신 새 코드의 진행 상황을 검증
- Opengrep SAST:
p/security-audit p/default p/python— injection, eval, 안전하지 않은 역직렬화를 스캔하는 데 약 30초 scripts/check-pip-audit.sh으로 감싼 pip-audit: JSON 출력을 캡처하고, shell 쪽에서 전송 오류(네트워크, PyPI 다운)를 분류해 취약점과 가용성 문제를 혼동하지 않도록 하며, 취약점을 보고합니다. v1.9에서는 초기 reporting 모드(warn + exit 0)로 운영 중이며 — 오래된 의존성의 bump PR 이후에는 차단 모드로 더 강하게 설정할 예정입니다.- unittest discovery:
python -m unittest discover를tests/에서 실행한 뒤scripts/tests/— 229개 테스트, 로컬에서 약 8초
외부 CI: SonarCloud + Codacy + CodeFactor
.github/workflows/sonarcloud.yml 워크플로우(프로젝트 키 jls42_ai-powered-markdown-translator)는 모든 PR에서 실행됩니다. README에는 SonarCloud 배지 11개가 표시되어 있습니다: Quality Gate, Security/Reliability/Maintainability Rating, Coverage, Vulnerabilities, Bugs, Code Smells, Duplications, Technical Debt, LOC.
왜 Codacy + SonarCloud + CodeFactor를 중복해서 쓰는가? 각각 보는 것이 다르기 때문입니다. Codacy는 SonarCloud가 잡지 못한 중복을 보고했습니다. SonarCloud는 Codacy가 놓친 품질 저하 신호(그 유명한 code smells)를 보고했습니다. CodeFactor는 나머지 둘이 무시한 복잡도 문제를 잡아냈습니다. 어느 하나만으로는 충분하지 않았습니다. 플랫폼 하나를 더 추가하는 비용은 사실상 0입니다(배지는 무료이고, 통합은 5분이면 됩니다). 그래서 시각을 여러 개로 늘립니다.
테스트: stdlib unittest 사용(ppytest 아님)
테스트 229개, PR 6개월 동안 회귀 0건, v1.9의 새 코드에 약 98% 커버리지.
전형적인 세부 사항은 다음과 같습니다:
test_silent_failure.py: 97개 테스트로 이중 검증을 집중 점검test_orchestration.py: 오케스트레이터 파이프라인에 대한 79개 테스트test_translation_note_position.py: position × format 매트릭스에 대한 38개 테스트test_audit_verdict.py: pip-audit wrapper에 대한 15개 테스트(scripts/tests/안에서)
솔직한 메모: 약 98% 커버리지는 v1.9의 새 코드에만 해당합니다. 전체 역사적 translate.py에는 여전히 새 테스트 배터리로 충분히 덮이지 않은 몇몇 상속 함수가 있습니다. 프로젝트 전체에 대해 « 98% 커버리지 »라고 말하면 오해를 부를 수 있기 때문에 이를 명시적으로 밝힙니다.
논란의 여지가 있지만 받아들인 선택: 테스트 실행기 unittest(stdlib), pytest 아님. test_ 접두사는 관습상 사용하지만, 실제로 실행하는 것은 unittest입니다. 왜냐하면? vibe coding 프로젝트에서는 추가하는 의존성 하나 = AI가 잘못 사용할 수 있는 의존성 하나이기 때문입니다. 단순함이 목표입니다. unittest는 Python 표준 라이브러리에 들어 있으므로 설치가 필요 없고, plugin도 필요 없습니다.
실전 테스트: multi-repo + 제품 내부 사용(dogfooding) + 시각적 렌더링 검증
229개의 unittest만으로는 충분하지 않습니다. 저는 실전 테스트를 세 겹으로 추가합니다:
1. Multi-repo — 여러 공개 repo에서 다양한 형식의 README를 대상으로 스크립트를 테스트합니다. 그러면 fixture가 덮지 못한 특이 사례가 드러납니다 — 8단계 제목이 있는 README, 레거시 shortcodes가 섞인 README, 특이한 임베디드 코드가 들어간 README 등입니다. Nouveauté 1의 silent-failure 사건도 바로 이 단계에서 발견됐습니다.
2. 블로그에서의 dogfooding — jls42.org는 스크립트 자체로 번역됩니다. 게시되는 모든 글은 프로덕션에서의 실시간 테스트입니다. 단위 테스트를 통과하지 못한 엣지 케이스가 있더라도, 결국 여러분이 지금 읽고 있는 이 페이지에서 드러납니다. 이것이 최종 테스트입니다 — 온라인에 올라간 것이 곧 이 프로젝트가 만들어 낸 결과입니다.
3. 시각적 렌더링 테스트 — 렌더링된 번역이 브라우저(최종 웹 페이지)에서든, Markdown 미리보기 plugin이 있는 VSCode에서든 제대로 표시되는지 확인합니다. 핵심은 문법적으로 유효한 Markdown에 만족하지 않고 실제 렌더링을 보는 것입니다. 시각적 렌더링은 텍스트 테스트가 놓치는 외관상의 버그(깨진 표, 잘못된 코드 블록, 잘못 해석된 frontmatter)를 드러냅니다.
AI들도 이 테스트에 참여합니다. /pr-review-toolkit는 테스트 환경에서 코드를 실행하며, pair-IA 사용에는 시각적 검증 패스가 항상 포함됩니다(« X 페이지의 독일어 번역이 잘 표시되는지 확인해 »).
📄 .pre-commit-config.yaml 발췌 (주요 pre-commit hooks)
repos:
- repo: https://github.com/shellcheck-py/shellcheck-py
rev: v0.10.0.1
hooks:
- id: shellcheck
args: ['-x']
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
- repo: https://github.com/pre-commit/mirrors-prettier
rev: v3.1.0
hooks:
- id: prettier
files: \.(json|yaml|yml|md)$
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
args: [--maxkb=1000]
- id: check-merge-conflict
- id: check-executables-have-shebangs
- id: check-shebang-scripts-are-executable
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
- repo: local
hooks:
- id: check-complexity
name: Lizard cyclomatic complexity (CCN <= 12)
entry: scripts/check-complexity.sh
language: system
pass_filenames: false
stages: [pre-commit]📄 scripts/check-security-sast.sh 발췌
#!/usr/bin/env bash
set -euo pipefail
cd "$(dirname "${BASH_SOURCE[0]}")/.."
# Skip gracieusement si opengrep absent en local ; fail-closed en CI.
if ! command -v opengrep >/dev/null 2>&1; then
if [[ -n "${CI:-}" || -n "${GITHUB_ACTIONS:-}" ]]; then
echo "opengrep introuvable en CI → fail-closed" >&2
exit 1
fi
exit 0
fi
exec opengrep scan \
--config=p/security-audit \
--config=p/default \
--config=p/python \
--severity=ERROR \
--error \
--exclude=venv \
--exclude=tests/fixtures \
translate.py scripts/📄 .github/workflows/sonarcloud.yml 발췌
name: SonarCloud
on:
push:
branches: [main]
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- uses: actions/setup-python@v6
with:
python-version: '3.12'
cache: pip
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
pip install coverage
- name: Run tests with coverage
run: |
coverage run --source=translate,scripts -m unittest discover tests
coverage run --append --source=translate,scripts -m unittest discover scripts/tests
coverage xml -o coverage.xml
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@v8
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}안전장치 2: AI 보조 리뷰 + 멀티모델 흐름
용어 정밀화: 이 섹션에서 Claude Opus라고 말할 때는 v1.9를 개발하는 데 사용하는 모델을 말합니다 — AI-Powered Markdown Translator가 번역에 사용하는 모델이 아닙니다. 이 프로젝트 자체는 4개 provider(OpenAI, Mistral AI, Claude, Gemini)를 지원하며, 어떤 모델이든(예: Sonnet, Haiku, Mistral Large, Gemini 3 Pro 등) 사용할 수 있습니다. 개발 측면에서는 Opus로 고정합니다. 실행 시 사용 측면에서는 프로젝트가 여전히 agnostic합니다.
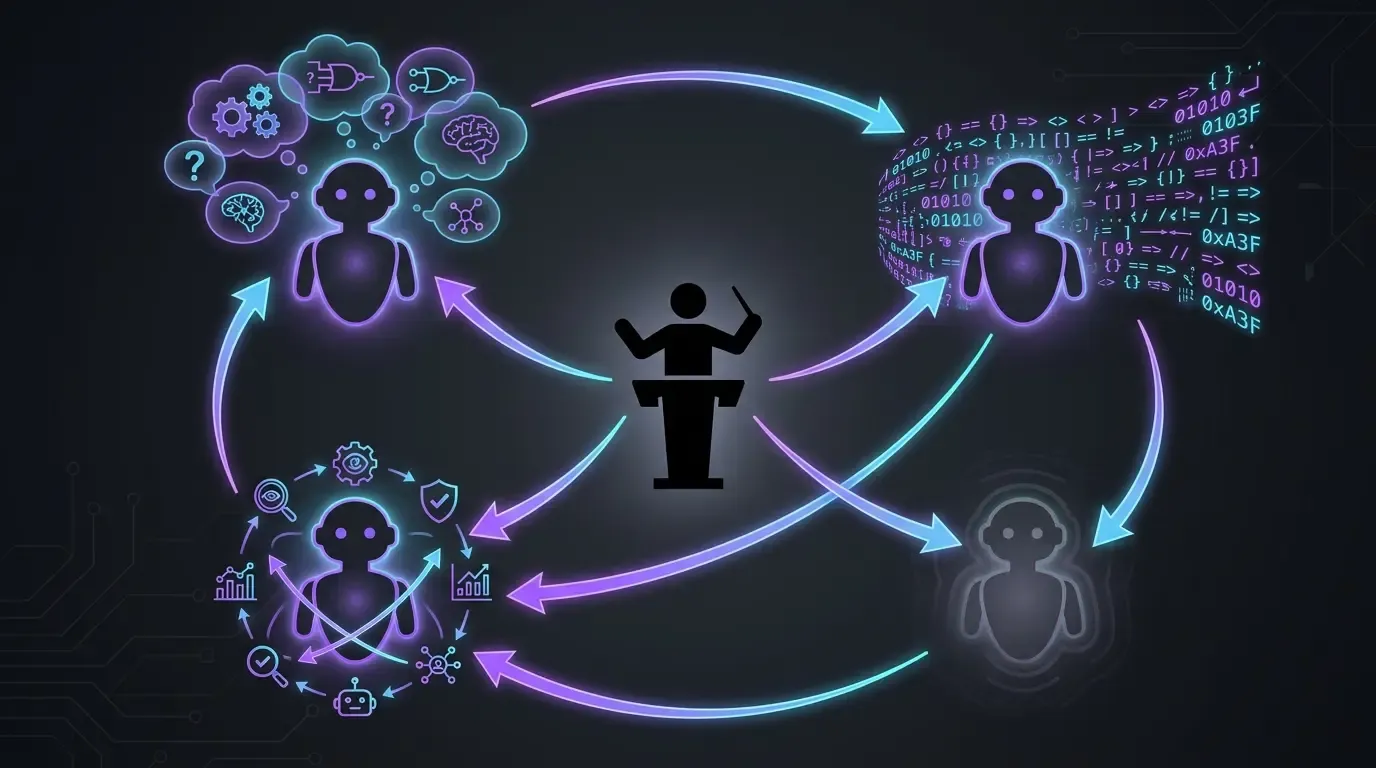
실제 워크플로: 4개 모델, 4가지 역할(개발용)
- Claude Code의 Opus만, 그것도 전용으로(anthropic): 주 실행 담당. 컨텍스트를 읽고, 코드를 작성하고, 수정 사항을 적용한다. Sonnet도, Haiku도, fast mode도 없다. 이 프로젝트에서는 매번 최상급 모델을 원한다 — 의도는 단순하다. 가능한 최상의 결과를 노리기 위해, 최고를 쓰는 것부터 확실히 한다.
- OpenAI Codex는 백업 솔루션(fallback): 두 가지 특정 상황에서 사용한다.
- Opus가 어떤 주제에서 막힐 때(드물지만 실제로 있다 — 예를 들어 Codacy나 SonarCloud 같은 외부 에이전트가 요청한 수정 사항에서 Claude가 때로는 수렴하지 못하고, 막힘을 풀기 위해 주제를 Codex로 넘긴다)
- Anthropic 사용량 창이 꽉 찼을 때. Codex는 할당량 리셋을 기다리는 동안 흐름을 잃지 않게 해준다.
- GPT-5.5 reasoning extra-high (
xhigh): 실행 전에 계획을 검증한다. Claude Code가 어떤 주제를 건드리기 전에, 계획을 GPT-5.5 reasoning extra-high에 넣는다. 그러면 제대로 된 질문을 던지고, 사각지대를 짚어낸다. 나중에 다시 수습해야 할 잘못된 방향으로 빠지는 일을 막아준다. /pr-review-toolkit:review-pr(Claude Code의 skill 플러그인): 전문 에이전트들(보안, 품질, 테스트, 주석, 타입 설계)과 함께 merge 전 리뷰를 한다. 이 skill은 PR 위에서 돌고 나서야 내가 merge한다 — 코드가main에 들어가기 전 마지막 AI 안전망이다.
이 모델들 중 어느 하나도 단독으로는 충분하지 않다. 각각이 서로 다른 역할을 맡는다 — 고급 실행자, 용량을 메우는 대체재, 계획을 검증하는 도전자, 여러 관점의 리뷰어(reviewer).
/pr-review-toolkit : 내가 보지 못했을 것들
전부다. 나는 코드를 보지 않는다. skill이 전부 끌어올린다 — 숨은 버그, 보안 문제, 테스트의 불일치, 통과하지만 사실 아무것도 검증하지 않는 테스트까지.
PR #2(75 commits, 9 837 additions, 1 982 suppressions, 58 files)에서는, 인간 혼자였다면 피로 때문에 PR의 80%를 skip했을 것이다. skill은 아무것도 skip하지 않는다. 모든 diff, 모든 테스트, 모든 코멘트를 읽는다. 그리고 무엇보다도, 도전한다 — 자신이 나쁘다고 판단한 패턴은 거부하고, 대안을 제시한다.
인간은 연주자가 아니라 지휘자다
내 역할은 코드 작성만 빼고 전체 체인을 아우른다. 나는 프로덕트 매니저(기능을 고민하고, 우선순위를 정하고, 판단한다), QA(실제 사례로 테스트하고, 화면 결과를 시각적으로 검증한다), tech lead(GPT-5.5 reasoning extra-high로 계획을 검증한다), 최종 고객(블로그에서 매일 쓰는 내 실제 경험으로 결과를 판단한다) 역할을 맡는다. 내가 맡지 않는 단 하나의 모자는 코딩이다. 나머지는 전부 나다.
나는 음악가가 아니라 프로듀서가 되었다.
블로그를 위해: 이 프로젝트가 스스로 번역한다(약 1,800개 번역)
AI-Powered Markdown Translator는 14개 언어로 자기 자신의 README를 생성하고, jls42.org의 모든 외국어 버전도 이 프로젝트가 만든다. 구체적으로는: 거의 1,800개의 번역본이 블로그를 채운다(25개 글 + 4개 프로젝트 + 98개 AI 뉴스 × 14개 언어, FR 원문 제외 — 내가 글을 쓰는 시점 기준 1,778개 버전). 여기서 프랑스어가 아닌 언어로 읽는 페이지는 모두 이 프로젝트를 거친 것이다.
이건 제품의 내부 사용(dogfooding)을 극단까지 밀어붙인 사례다 — 그리고 번역에 대한 글 자체를 번역하면서 번역을 스트레스 테스트한다. 여러분이 ar, hi 또는 ko에서 읽는 내용이 일관된다면, 새 기능 1(번역 후 검증) 안전망이 제대로 작동한다는 뜻이다. 상단에 번역 노트가 올바르게 표시된다면, 새 기능 2(다중 위치 노트)가 제대로 동작한다는 뜻이다. 언어별 버전에서 EN 인용문이 보존된다면, 새 기능 3(--news 모드) 역시 잘 작동한다는 뜻이다.
결론: 대충 하는 AI 페어가 아니라, 엄격한 AI 페어
감에 의존한 개발이 나쁜 평판을 받는 데는 그럴 만한 이유가 있다. 바로 그 점에 맞서 내가 일하고 있다. 이 v1.9에서 얻은 구체적인 교훈은 네 가지다.
-
침묵하는 실패가 가장 큰 적이다. AI는 그럴듯해 보이고 단위 테스트도 통과하는 코드를 만든다. 클라이언트 측 검증은 반드시 해야 한다. 그리고 코드만이 아니라 실제 산출물을 다른 AI로 다시 읽게 하는 것이 중요하다.
-
pre-commit 훅은 10초 이하여야 하고, 아니면 우회된다. pre-push는 30초 이상 걸려도 된다. AI는 비용을 고려하지 않고 도구를 덧붙이기 쉽다. 계획 단계에서든 사후 조정에서든 수동으로 기준을 잡아야 한다 — 중요한 건 결국 훅이 제대로 설정되고, 실제로 일상에서 쓰이게 만드는 것이다.
-
강한 assertion이 없는 coverage는 연극이다. AI는 통과만 하고 아무것도 검증하지 않는 테스트 200개도 만들 수 있다. mocks를 잔뜩 쓰는 pytest보다 unittest + 정확한 assertion이 낫다. 코드가 크래시하지 않았는지만 보지 말고, 반환값을 검증해야 한다.
-
AI PR review는 선택 사항이 아니다. 인간 작성자가 다시 읽지 않았다면, AI 리뷰어는 사치품이 아니다 — 위임된 눈이다.
vibe coding을 제대로 한다는 건, 코드 자체를 읽지 않는다는 사실을 받아들이고, 비판적 읽기를 정말로 해주는 다른 AI들에게 그 역할을 위임하는 것도 포함한다.
이 프로젝트가 보여주는 것
이 v1.9는 내가 일하는 방식을 여러 측면에서 보여준다.
- 인간의 역할은 코드를 제외한 전 체인을 포괄한다: 프로덕트(기능을 고민하고 우선순위를 정함), QA(실제 사례로 테스트하고 시각적으로 검증함), tech lead(GPT로 계획을 검증함), 최종 고객(실제 사용 경험으로 판단함). 내가 맡지 않는 유일한 모자는 코딩이다.
- 안전망을 없애는 게 아니라, 더한다: 사람이 덜 읽는 대신 도구 검증을 더한다. 이것은 성의 부족이 아니라 의도한 절충이다. 내가 리뷰를 줄이면, 믿음을 늘리는 게 아니라 안전망을 두 배로 늘려야 한다.
- AI를 써서 AI의 버그를 찾는다: 침묵하는 실패는 다중 repo 실전 테스트 중 Claude가 찾아냈다. 완전한 위임: 비판적 리뷰도 위임할 수 있다.
- AI 페어는 개인 시간에 곱셈 효과를 낸다: 나는 이 프로젝트를 저녁과 주말에 진행한다. AI 페어가 없었다면, 분명 지금처럼 멀리도 빠르게도 못 갔을 것이다. 함께라면, 다른 업무를 병행하면서도 오픈소스 프로젝트를 산업 수준으로 유지할 수 있다. 이것이 vibe coding이 가능하게 하는 것이다 — 개발자를 대체하는 것이 아니라, 혼자서는 할 수 없는 일을 가능하게 해주는 것.
- 전부 다시 쓰기보다 반복 개선하기: 9개 버전, 점진적 리팩터링(함수 1개 → helper 7개), 하위 호환성 유지. AI 페어는 전부 다시 쓰지 않고도 빠르게 반복 개선하도록 도와준다.
자료
- GitHub의 AI-Powered Markdown Translator
- v1.9 릴리스
- PR #2 — 75 commits, 마이그레이션 + 품질
- 전체 CHANGELOG
- 이 블로그의 프로젝트 페이지
- 2024년 글 — v1.5(릴리스 노트 스타일) — 톤 비교용
- AWS 다이어그램 심층 분석 — 시리즈의 다른 글
자신의 Markdown — 오픈소스 README, 블로그 글, 기술 문서 — 에 AI-Powered Markdown Translator를 시험해보고 싶다면, 코드는 GitHub에 있습니다. 몇 분 만에 설치할 수 있고, 4개의 provider를 지원하며, 비용을 줄이기 위한 --eco 모드, 원문 인용을 보존하는 --news 모드, 그리고 이제는 자신의 AI 페어 프로젝트에 템플릿처럼 재사용할 수 있는 v1.9 품질 스택까지 갖추고 있습니다.
여러분이 개인 프로젝트를 감으로(vibe coding) 개발한다면, 품질 쪽에서 가장 쉬운 길로 가지 마세요. 신뢰성은 속도를 위한 대가입니다 — 둘 다 함께 받아들이세요.